如何导入没有列名的txt数据文件
我的DolphinDB建库建表定义如下:
db1 = database("", VALUE, 2020.01.01..2020.12.31)db2 = database("", HASH,[SYMBOL,20])
db = database(database,COMPO, [db1,db2])
colNames=`TradeDate`Type`Seq`ExchID`SecID`ExTime`LocalTime`TradeTime`TradePrice`Volumn`Turnover`TradeBuyNo`TradeSellNo`TradeFlag
colTypes=[DATE,INT,INT,SYMBOL,SYMBOL,TIME,TIME,TIME,LONG,LONG,DOUBLE,INT,INT,SYMBOL]
t=table(1:0,colNames,colTypes)
transpt=db.createPartitionedTable(t,`transpt,`TradeDate`SecID)
我的txt文件数据样本如下: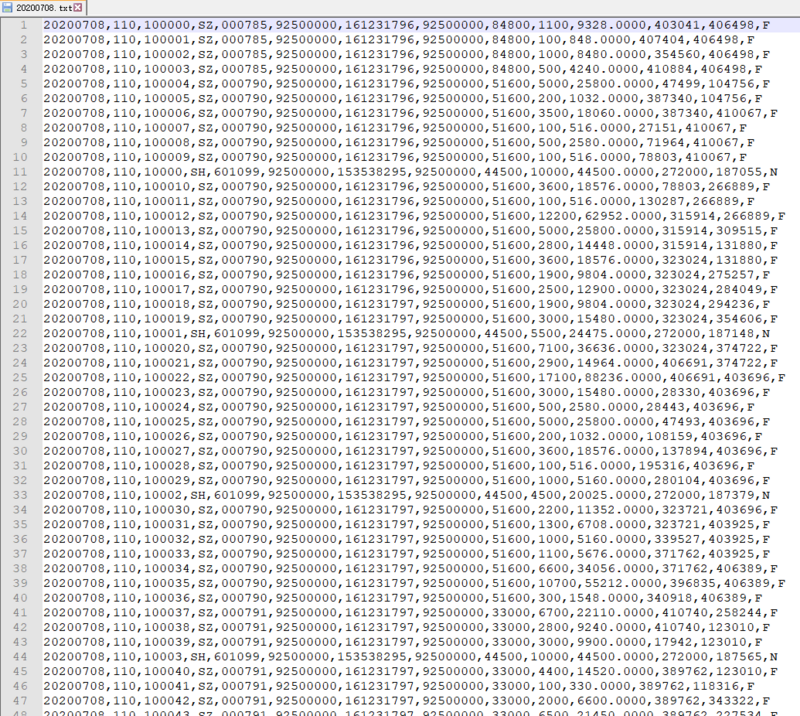
txt文件头中没有列名,但其每列的定义如下图: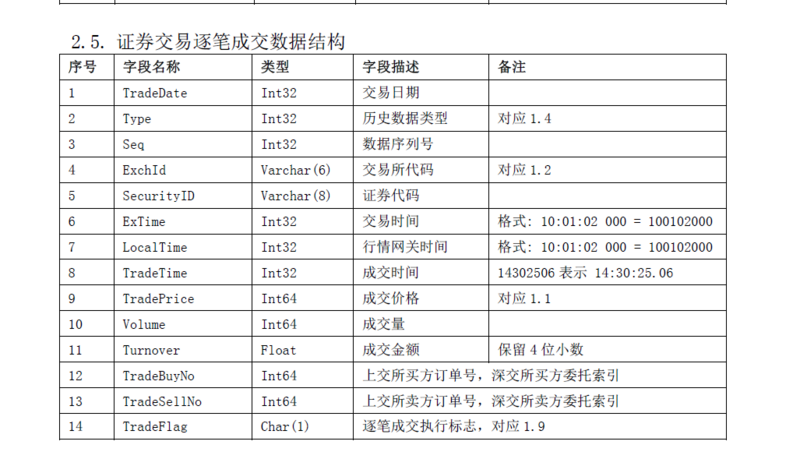
我导入数据的脚本如下:
database="dfs://dataImportTxt"fileName="/home/mdp/marketdata/20200708.txt"
def d2m(mutable t){
return t.replaceColumn!(`TradeDate,datetimeParse(string(t.TradeDate),"yyyyMMdd")).replaceColumn!(`LocalTime,datetimeParse(string(t.LocalTime),"HmmssSSS")).replaceColumn!(`TradeTime,datetimeParse(string(t.TradeTime),"HmmssSSS")).replaceColumn!(`ExTime,datetimeParse(string(t.ExTime),"HmmssSSS"))
}
schema=extractTextSchema(fileName)
table=loadTextEx(db,`transpt,`TradeDate`SecID,fileName,',',schema,,d2m)
transpt=loadTable("dfs://dataImportTrans","table")
执行上述脚本会报如下错误:
请问是什么原因?
回答
加载时要先看一下txt文件的shema,可通过执行extractTextSchema("20200708.txt")获取,结果如下:
name typecol0 DATE
col1 INT
col2 INT
col3 SYMBOL
col4 SYMBOL
col5 INT
col6 INT
col7 INT
col8 INT
col9 INT
col10 DOUBLE
col11 INT
col12 INT
col13 CHAR
所以导入代码如下:
def d2m(mutable t){ return t.replaceColumn!(`col5, t.col5.format("000000000").datetimeParse("HHmmssSSS")).replaceColumn!(`col6, t.col6.format("000000000").datetimeParse("HHmmssSSS")).replaceColumn!(`col7, t.col7.format("000000000").datetimeParse("HHmmssSSS")).replaceColumn!(`col13,string(t.col13))
}
db=database("dfs://dataImportTxt")
loadTextEx(dbHandle=db, tableName=`transpt, partitionColumns=`col0`col4, filename="20200708.txt", delimiter=',',transform=d2m)
以上是 如何导入没有列名的txt数据文件 的全部内容, 来源链接: utcz.com/a/42573.html