scrapy-爬取京东笔记本电脑信息问题
出现的问题:
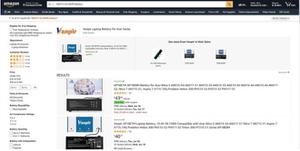
在下载器中间键中,把browser.quit()注释掉,可以正常的爬取,但是如果不注释掉,则会出现“目标计算机积极拒绝访问”的问题(如下图)
这个是什么原因导致的啊?恳请大佬解答
爬虫代码:
import scrapyfrom JD_books_Spider.items import brands_goods
class JD_compter_spider(scrapy.Spider):
name = 'jd'
def start_requests(self):
urls = ['https://list.jd.com/list.html?cat=670%2C671%2C672&go=0']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self,response):
brand_href_list = response.xpath("//ul[@class='J_valueList v-fixed']/li")
for li in brand_href_list:
brand_href = li.xpath("./a/@href").extract_first()
title = li.xpath('./a/@title').extract_first()
if brand_href is not None:
brand_href = 'https://list.jd.com' + brand_href
yield scrapy.Request(url=brand_href, callback=self.single_brand_page, meta={'item': title})
break
def single_brand_page(self, response):
bg = brands_goods()
bg['brand_title'] = response.meta['item']
goods_list = response.xpath("//ul[@class='gl-warp clearfix']/li")
for good in goods_list:
id = good.xpath('./div/div[3]/a/@href').extract_first()
if id is not None:
id =id.split('/')[-1].split('.')[0]
bg['goods_id'] = id
yield bg
# page_num = response.xpath("//div[@class='page clearfix']/div/span[2]/em[1]/b/text()").extract_first()
# page_num = int(page_num)
# num = 1
# for i in range(page_num-1):
# num += 2
# next_url = ('https://list.jd.com/list.html?cat=670%2C671%2C672&ev=exbrand_') + bg['brand_title'] + ('%5E&page=') + str(num)
# try:
# yield scrapy.Request(url=next_url, callback=self.single_brand_page)
# except:
# print(next_url)
# print("网址不可用")
下载器中间件代码:
from selenium import webdriverfrom scrapy.http.response.html import HtmlResponse
from time import sleep
class JD_Spider_MiddleWare(object):
def process_request(self, request, spider):
options = webdriver.ChromeOptions()
options.add_argument('--log-level=3')
browser = webdriver.Chrome(options=options)
browser.maximize_window() # 最大化窗口
browser.get(request.url)
target = browser.find_element_by_id("J_promGoodsWrap_292")
browser.execute_script("arguments[0].scrollIntoView();", target) # 拖动至见到下一页为止
sleep(5)
browser.quit()
return HtmlResponse(url=request.url, body=browser.page_source, request=request, encoding='utf-8') # 返回response
class JD_spider_MiddleWare_return(object):
def process_response(self, request, response, spider):
return response
回答
browser.quit() return HtmlResponse(url=request.url, body=browser.page_source, request=request, encoding='utf-8') # 返回response
这还看不出来吗?return中用到了browser,肯定报错了
你改成
body = browser.page_sourcebrowser.quit()
return HtmlResponse(url=request.url, body=body, request=request, encoding='utf-8') # 返回response
试试看
以上是 scrapy-爬取京东笔记本电脑信息问题 的全部内容, 来源链接: utcz.com/a/41890.html