
中文关键词如何与pdf文本进行模糊匹配?
我现在有一个excel表里面包含了需要匹配的关键词,如下
现在我拥有若干pdf文档,想实现寻找pdf中是否包含该关键词并计数,实现结果如下: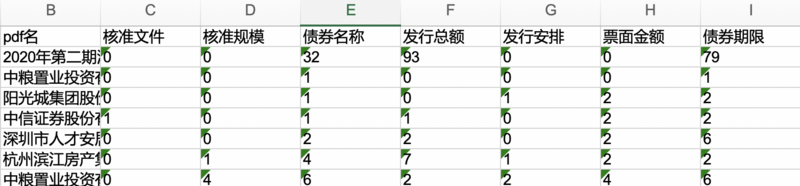
现在面临的问题是,因为这是精确匹配,导致很多关键词实际在pdf文档中出现但并不会被记录。比如关键词【债券负责人联系电话】,在pdf中可能会是【联系电话】作为【债券负责人】的子类,或者会出现【债券负责人和联系电话】。在类似情况中,匹配无法进行。想请问各位大神,在匹配过程中有办法进行一定程度的模糊匹配" title="模糊匹配">模糊匹配吗?十分感谢。
回答
只从文本操作这不太懂,如果可以的话建议使用搜索引擎,比如elasticsearch,将pdf内容录入到elasticsearch,然后检索关键词,这个方案应该可行,但有点学习成本。
以上是 中文关键词如何与pdf文本进行模糊匹配? 的全部内容, 来源链接: utcz.com/a/39575.html

