用 4.5 万字,谈一谈网络协议的微缩宇宙
🌈笔者决定围绕 HTTP 协议展开一次宏观了解,包括 TCP / HTTPS / 跨域 / Socket / WebSocket / Session & Cookie 等内容,并计划着用一长篇文章搞定它们。同学们可以根据自身的兴趣点各取所需,在阅览前可以先检查下面的大纲:
- TCP 传输过程
- HTTP 1.0 | 1.1 | 2.0协议
- HTTPS | 非对称加密算法概述 | TLS验证过程
- QUIC 协议
- Socket API | 服务器并发
- WebSocket 协议
- 跨域和 CORS
- Cookies | Session
篇幅很长,手机端不显示侧边目录,推荐用电脑端打开阅览。

大部分均为阅读内容,少部分代码内容基于 Spring Boot 给出实现。内容的广度越大,在细节之处的纰漏可能也越多,深度也可能有所不及。笔者通过网络资源对上述的知识点进行了整理,对有些概念的理解难免有失偏颇,欢迎大家多加指正。
注:Socket 并不是协议,但是上层网络协议都离不开它。因此笔者也将它纳入到这篇文章中进行了介绍。
RTT : Root of all evil
为何称RTT是"万恶之源"?因为网络协议的进化史,就是人类不断与RTT斗争的历史。
RTT(Round-Trip Time),往返时延,表示从发送端发送数据开始,到它收到响应所经历的时延,包含了两端的一去,一反。比如我们在北京访问上海的服务器,两端的物理距离为1000 km,假使信息以光速 30,000 km/s 传播,那么北京到上海的 RTT= (1000 x 2 / 30,000) ≈ 6.7 ms。
当然,考虑到信息并不是完全以光速传递,并且信息在是在一个拓扑网络中进行转发的,而非简单的两点一线。因此实际上北京到上海的 RTT 要比这种简单的估算要高很多,实际情况下北京到上海的 RTT 时延约 40 ms。
我们很容易能推断出来:地理位置 / 网络拓扑位置越相近的两台主机,估算下来的时延也应当越低。在客观物理规律(比如说光速)的限制下,一个有效降低 RTT 时延的方法就是:让两个主机“挨得更近些”。 CDN 就是通过这样的启示诞生的,它将内容分发到距离用户近的网络节点来降低用户访问延迟,简单而有效。
从网络传输的过程开始
在发送端,来自应用层的 HTTP 报文会被不断"装箱",随后经过链路层发送到接收端,再逐渐进行"拆箱"。图中是经典的五层网络模型的一部分,在这里我们不考虑物理层。
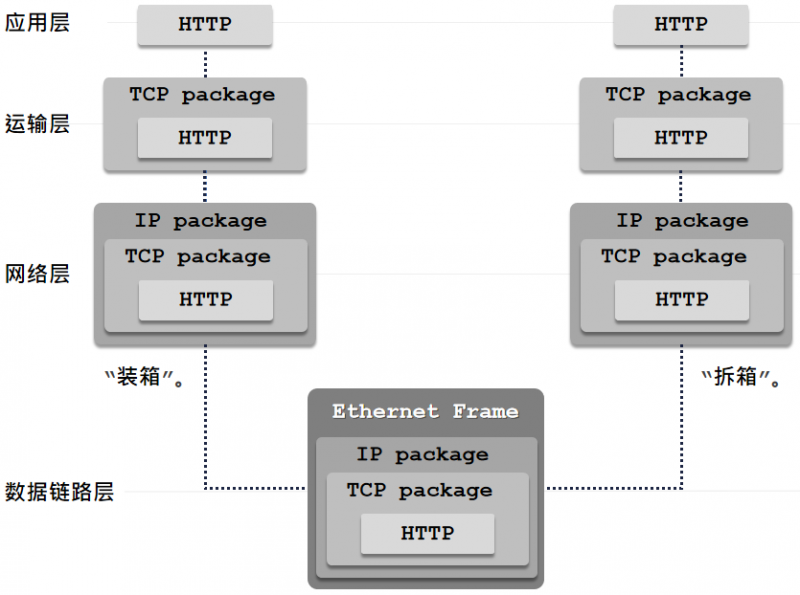
在HTTP/3 协议之前, HTTP 基于 TCP 协议之上运行。我们不妨在这里对 TCP 协议做一个回顾,而不仅限于画出三次握手或是四次握手(本文没有提及)的草图。笔者在这里选择性回顾有关 TCP 的细节,以便我们在后续的文章中探讨 TCP 对 HTTP 协议发展的影响,包括对 Socket 的理解。
回顾 TCP 连接
三次握手
TCP 为保证其可靠性使用了种种复杂的机制和计时器。这里仅介绍 TCP 连接部分的简要过程。
客户端和服务器端建立 TCP 连接过程如下图所示:
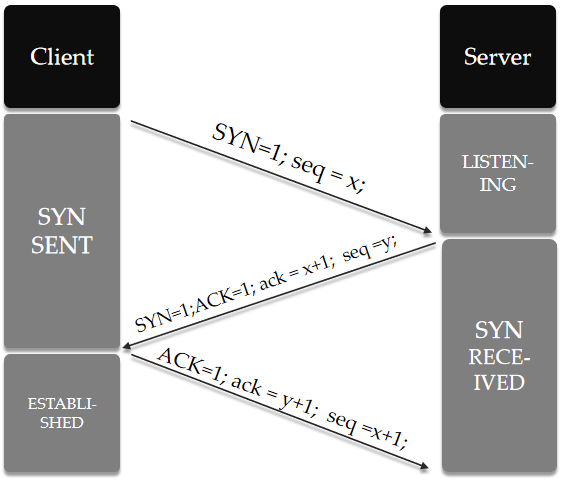
注意:
大写的 ACK 是报文中的标志位,和小写的 ack 的涵义不同。
一次 TCP 连接需要经历1.5个 RTT 的时延。有些人认为第三次握手的时候就可以携带数据了,因此一次 TCP 握手也可以是 1 个 RTT 时延。笔者在全篇文章中都是按 1.5 个 RTT 计算的。
- 双方发送的第一个 seq 序号是随机数,故这里用 x 和 y 来代替。
为什么要进行三次握手呢?
三次握手是为了保证 Client 和 Server 之间能够相互确认。假定现在有一个长时间滞留的报文刚刚到达 Server 端(但此时 Client 可能因等不到回复而提前关闭了连接),如果 Server 不加验证就进入就绪状态,此时就会陷入空等而白白浪费自己的网络资源。
因此双方都应该使用seq序列号来让对方确认并回执ack,来表示一个双向有效的连接被建立起来了。
MSS
MSS(Maximum Segment Size), TCP 协议所设定的最大报文段长度。在连接建立之初(发送SYN段)的时候,均会将 MSS 发送给对方,表示自己希望接收的 TCP 报文段数据部分的最大值(注意,只包含数据部分,TCP 报文头的长度没有计入其中)。
算上 IP 报文头部的 20 字节和 TCP 报文头部的 20 字节,发送一个 TCP 报文本身就需要携带 40 字节的荷载。设 TCP 内部的数据为 n 字节,传输效率 = n / (n + 40),也就是说, TCP 传输的数据量越大,网络利用率越高,因此我们总是尽可能想把 MSS 调节的高一些。
当然 MSS 的设定也有限制。数据链路层规定了一个帧大小至多为 1518 个字节,其中包含了 14 字节的帧头, 4 字节帧校验和,数据部分至多占 1500 字节(它又称 MTU )。若 IP 报文总长度超过了 1500 字节,那么在数据链路层就需要两个帧来运输。
为了节省开销,我们总希望一个以太网帧正好能装下一个 IP 数据报,或者说在一个数据帧内尽可能传输多的内容,因此 TCP 报文的 MSS 被压缩至( 1500 - 40 ) = 1460字节。
MTU
为什么 IP 层不希望将一个完整的 TCP 报文分片呢?因为 IP 层本身没有丢失重传机制,也就是一旦运输过程中丢失了 TCP 报文片的一小部分,就需要上层的 TCP 协议再次重传一遍整个报文。
MTU(Maximum Transmission Unit),最大传输单元。我们刚才提到了" IP 报文超过 1500 字节,TCP 报文就会被迫分片"。这个 1500 字节就是以太网数据链路层设定的 MTU 值,实际上 MSS = ( MTU - IP 首部 - TCP 首部) 。
TCP 协议之所以让双方在建立连接之初协商就 MSS 的大小,其目的就是为了事先控制 TCP 报文不要超过 MTU 的限制,以免 IP 层将数据包向下传递到数据链路层的时候再次进行分片。
🌎这个帖子介绍了有关 MSS 和 MTU 的更多细节。
滑动窗口机制(流量控制)
TCP 是全双工通信,通信的双方具有独立的接收窗口和发送窗口。滑动窗口主要由三个指针来描述:头/尾/目前的位置。在接收/发送报文的时候,这些指针会时刻地变化。另外,滑动窗口以字节为单位发送数据。以下面的图示为例:

字节序列可分为四个部分:
- 已经被处理并得到确认的。
- 处于滑动窗口中已被处理但未得到确认的。
- 处于滑动窗口中等待被处理的。
- 暂时不在滑动窗口中的。
这里的处理指接收,或发送。在同一时刻内, Sender 的发送窗口和 Receiver 的接收窗口大小并不总是相同。
图中 Sender 的发送窗口的起始字节为32,窗口Win大小为5(由对方的 Receiver 规定),发送窗口在36号序列截止。对于 Sender 来说:
- 31号及之前的序列已经发送并得到了 Receiver 的 ack 确认。
- 32-34 的序列已经装入 TCP 报文并发送,但未得到回执。
- 剩余的 35,36 则暂时还没有发送出去。
- 受对方的窗口大小限制,暂时不能发送 37 号之后的序列。
对于 Receiver 来说,它刚刚收到32-34号的字节序列,在一段时间之后(参见延迟确认机制), Receiver 会向 Sender 发送 ack = 35,并重新调整窗口。
Sender 的发送窗口在做什么
设 Sender 的发送窗口的起始序列号为 N。每次在 Sender 接收到 Receiver 的 ack 报文时:
- 取出 ack 字段重新为 N 赋值,相当于将 Sender 的发送窗口向后推。
- 根据 Win+ N 计算出窗口的末尾,相当于将窗口向后延展。
设 Sender 下一个要发送的序列号起点为 next,并准备发送 TCP 报文。每装入一个字节,则更新 next 的值。发送多少个字节序列就向前移动多少,但是不会超过 N + Win。
被装入 TCP 报文发送的字节序列会处于“在滑动窗口内,但未得到响应”的状态,有利于 Sender 在必要时重新发送。当得到 Receiver 新的确认号 ack 之后, Sender 的发送窗口就会“滑过”这些序列,并向后纳入新的等待发送的字节序列。
Receiver 的接收窗口在做什么
设 Receiver 的接收窗口的起始序列号为M,每次在 Receiver 确认收到 Sender 发送的报文时,它会将有序序列的最后一个序列号赋值给ack并回执给 Sender 。同时, Receiver 会将这个 ack 的值赋给 M,相当于将 Receiver 的接收窗口向后推。
Receiver 还会根据自身的实际状态计算出 Win 的值装入报文发送给 Sender ,告示 Sender 不要一次性发送过多的内容。
比如说 Receiver 此时接收到了 31号序列之后,下次给 Sender 发送的 TCP 报文的 ack = 32 且 Win = 5( Win 取何值一部分取决于 Receiver 缓冲区剩余容量 n )。 Sender 在收到这个报文后就会知道:31号序列及之前的字节都已经接收,下一次只要发送 32 号序列,并至多发送到 36 号。
Win 的值除了取决于 Receiver 方的缓冲区剩余容量 n 之外,还取决于拥塞窗口的大小,我们稍后就会提到它。
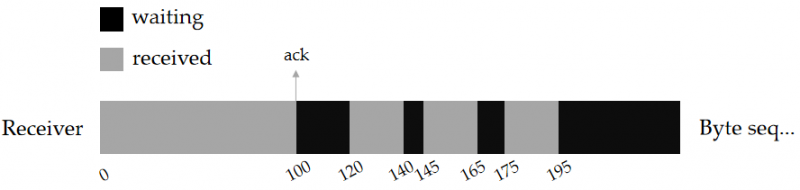
为了说明“ Receiver 将最后一个有序序列号赋值给 ack ”的问题,这里再举一个例子。如图所示,下面是 Receiver 接收到的字节序列示意图。它除了接受到 0~100 号完全有序的序列之外,假设还收到了后面的 121~140,146~165 等字节序列,但是它们之间不连续。按理说 Sender 会按照窗口的滑动顺序发送序列,显然中间空缺的序列是因为对应的 TCP 包发生了丢失或因网络问题没有及时到达。
在这种情况下, Receiver 下次发送给发送方的 ack 仍然是 101 :表示“ 0 ~ 100 号序列已经完全没有问题,我希望将 101 ~ 120 的部分补齐“,而不是发送 196 。或者说, Receiver 的接收窗口的头仍然停留在101号的位置。
❗如果迟迟接收不到100~120的数据包,则 Receiver 的接收窗口会陷入停滞状态而不会向后滑动。
数据传输过程中的细节
- 双方在运输层面是基于完整的 TCP 报文(或称“包”)进行数据交互的。 Sender 会一次性从滑动窗口中取出一大段连续的字节序列(数据量不超过接收方发送的 Win,上限为 MSS )封装到一个 TCP 包后再发送。 Sender 方会维护一个表,来记录每次发送的 TCP 包的起始序列号以及此 TCP 包数据部分的长度,以便于后续为 Receiver 重发数据,直到根据对方回执的 ack 判断出这个包已经没有问题了为止。(参考超时重传)
- Receiver 的接收窗口会接收源源不断的来自 Sender 的字节序列,但是不会马上给予回复。(参考延迟确认)
- 在复杂的网络中难免会有部分数据延迟到达的现象。 Receiver 如果收到了重复的字节序列,将会丢弃它。
- TCP 协议本身没有保证 Sender 发送的 TCP 报文一定会按时序到达,因此 Receiver 会使用接收窗口进行缓冲,等待字节流中缺少的字节收到之后再交付给上层。
- Receiver 的 ack 号代表着 ack - 1 号及之前的序列是连续有序的。即使 Receiver 收到了后面的几个不连续的字节序列,它仍然会将之前有序字节序列的最后一个序号+1发送给 Sender 。(参考快重传)
超时重传
TCP 协议中规定 Sender 必须要对自己每个发送的 TCP 包负责,因此 Sender 除了记录这个包发送的内容之外,还会为每个 TCP 包设定一个重传计时器。重传计时器以一个 RTO 为时间单位,如果在这个时间单位内收不到对应的 ack,则 Sender 会认为这个 TCP 包已经丢失,此刻会主动将这个TCP包重新发送。这个 TCP 包并不一定真的丢失,或许它在很长一段时间后才到达 Receiver 端。 Receiver 如果已经提前收到补发的 TCP 包,则这个多余的 TCP 包会被丢弃。
RTO(Retransmission Timeout),指一个包从刚发送完的一刻起到接收到对应 ack 的这段时间,它很大程度决定了超时重传机制的效率。如果 RTO 被设置的过小,则会造成不必要的重传;如果 RTO 设置的过大, Receiver 方缺失的字节序列又迟迟得不到补充。RTO 一般都会设置的要比采样得到得平均 RTT 时间要大一些。
TCP 的重传歧义问题
TCP 超时重传机制其实存在一些漏洞。假设某一个 TCP 包的 seq = x,发送方无论是第一次发送它和重传它,这个数据包的 seq 都是 x。假设现在已经收到了确认包的 ack = x+1,那么这个确认是对正常发送的包的确认呢?还是对重传的包的确认呢?
Sender 对这个包的 RTT 采样就变得模糊了: 它区分不出来这个 ack 是对哪个包的确认, 因为这两个包的 seq 是一样的。
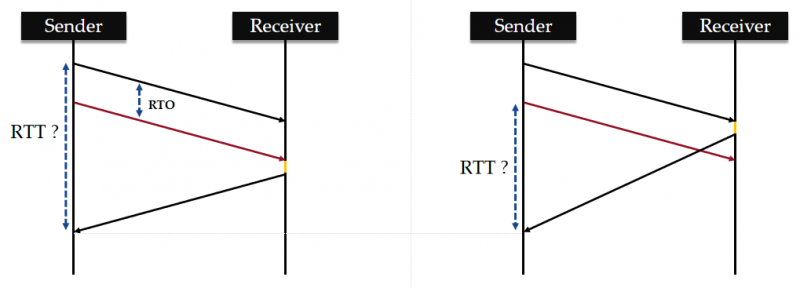
上图展示了两个情况 1 和 2 。 Receiver 受延迟确认机制的影响,因此接收和发送确认会存在一个时间差(已用橙色线段标注出)。
- 如果发送方判断的情况为 1 ,而实际情况为 2 ,则这个 RTT 的估计值会偏大。
- 如果发送方判断的情况为 2 ,而实际情况为 1 ,则这个 RTT 的估计值会偏小。
上述的两种结果都会影响 Sender 对实际 RTO 的判断。因为 RTO 是通过采样最近所发包的 RTT 时间计算出来的,重传歧义会导致 Sender 设置的 RTO 偏高或偏低。
快重传
快重传机制提高了 Sender 的响应能力,使其不用再完全等待 RTO 时间来判断一个 TCP 包是否丢失。在”数据传输过程中的细节“中我们提到过, Receiver 只会发送有序字节序列的最后一个序号+1。假定 Sender 已经发送了:
- 📦包 1(含101~120字节序列)
- 📦包 2(含121~140字节序列)
- 📦包 3(含141~160字节序列)
在 Receiver 后续的响应报文中,有连续三次的 ack 一直都是 101, Sender 就会判断包 1 疑似丢失,此时就不会再等待包1的重传计时器结束,而是立刻重新将包 1 发送出去。
注:快重传属于拥塞控制的一种方式。
延迟确认
Receiver 不需要对每次收到的字节序列都回执一个 ack 。这里 TCP 提供了两个策略:
- 累计确认: Receiver 在一个时间窗口内只接收数据,并在这个时间窗口结束时检查最新的 ack 确认。TCP 协议规定 Receiver 不可以过分推迟确认,以免 Sender 触发超时重传机制。这个时间窗口设定不会超过 500 ms。
- 捎带确认: Receiver 需要给 Sender 发送一些数据的时候,顺带着回送最新的 ack 序号。
延迟确认所带来好处是:极大地降低了网络流量。 Receiver 发送的这个 ack 确认号意味着: Receiver 确定ack号及其之前的所有字节序列也完全没有问题。
拥塞控制
流量控制是 Sender 和 Receiver 之间需要考虑的事情,通过滑动窗口来实现。而拥塞控制考虑到了网络的整体情况。在早期,TCP 对拥塞的判断很简单:”丢包即拥塞;一旦拥塞,就减少数据发送量“。
拥塞控制使用拥塞窗口来实现,并根据拥塞程度控制大小。设 Receiver 计算出的滑动窗口大小为 rwnd,而目前综合网络状态所计算出的拥塞窗口大小为 cwnd,则 Receiver 方实际的 Win = Min { rwnd, cwnd }。
拥塞控制算法包括了慢开始,拥塞避免,快重传(刚才介绍过),快恢复:
- 慢开始:在开始,发送方的拥塞窗口的容量极小,但是在一段时间内 cwnd 会以指数形式快速增加。
- 拥塞避免:在慢开始过程中, cwnd 到达一定的阈值
thresh时, cwnd 线性稳定增加。 - 快恢复:如果1,2过程中发生丢包现象,那么 cwnd 则立刻折半。如果折半后小于
thresh,则进行慢开始,否则继续按照拥塞避免执行。
注:在初期的 TCP Tahoe版本中,一旦丢包,则 cwnd 立刻会降低到最开始的极小值,而不是折半。由于此算法效率过低,因此随后被废弃了。
TCP 传输过程
下面是一个连贯的 TCP 收发流程的演示,这里忽略一些细节,假定每次服务器发送的 TCP 包固定只包含 100 B 的数据部分。

为什么 HTTP 当初选择了 TCP 协议?
下面逐渐步入正题。 HTTP 是一个应用层的协议,其实它本身并不关心底层到底是如何发送的。
HTTP 协议有两个选择:UDP,或者是 TCP。但为什么早期的 HTTP 协议选择了后者呢?我们先举两个例子来说 TCP 和 UDP 。
- TCP:好比你通过电话的方式 soulmate 打电话约会。你首先要拨号,其次TA要接听,一个双向的通讯才建立完成了。在通话的这段时间,你们可以无所不聊。当然,电话联络需要一点等待的时间,因为你需要等待对方的接听。
- UDP:好比你通过手机短信的方式和 soulmate 约会。这种方式不需要等待时间,直接把短信发送出去就可以了。当然, TA 也许会看到这个短信,也许会不小心忽略了它(丢包了)。
如果你仅仅要发一句简单的问候:“你吃饭了吗?”,那么发一条短信完全没有问题。如果你真的很想念你的 soulmate ,还是给 TA 打一个电话吧。😏
起初, HTTP 选择 TCP 的动机很明确,无非是想要求运输层保证通讯质量,否则浏览器时不时就出现文字乱码,图片丢失, CSS 样式失效的问题,对用户体验的打击是巨大的。但是随着 HTTP/2 的诞生,人们似乎发现了 TCP 在某些网络情况的性能问题......
TCP 真的是万全之策吗?
TCP 协议和它的好哥们 IP 协议通常被人们统称为 TCP/IP 协议。在1973年,它们就已经被两位年轻的科学家:温顿·瑟夫和罗伯特卡恩构思出来,并在1980年左右, TCP/IP 协议投入到了用于“异构”网络环境中,使得不同硬件和操作系统的计算机一起工作,互连网才成为了真正意义上的互联网 internet。
直到现在, TCP 都可以称之为”可靠“的代名词,因为 TCP 使用了相当复杂的机制来保证数据传输的可靠性。
TCP/IP 协议也经历了风风雨雨。对于 IP 协议来说, 43 亿个 IPv4 地址在 2019 年已经分配完毕,下一代互联网建设正式(不得不)向 IPv6 过渡。
而 TCP 这边也有点大麻烦:在 TCP 的设计之初,计算机基本都通过有线网络连接,出现网络不稳定的可能性也比较低,所以当时 TCP 协议的设计者认为:丢包即网络出现拥塞,一旦发生丢包, TCP 的拥塞控制就会主动降低吞吐量。
现在,无线网络的引入导致部分场景下的网络不稳定成了常态,比如说在地铁、车站等场景中,因为丢包率较高,客户端在网络环境较差的情况下很难与服务端快速完成三次通信并建立 TCP 连接。
TCP 协议中拥塞控制以及对丢包的处理引发了文章后续有关"HTTP/2真的解决队头阻塞了吗?"的探讨。
一次经典的 HTTP 连接过程
HTTP 是基于 TCP/IP 基础之上的协议。浏览器打开一个连接发送请求,然后等待服务器将相应的资源返回。是无状态的连接协议(这也是为什么我们后续需要使用 Cookie , Session 来保持会话状态)。
笔者默认 TCP 的第三次握手不携带数据。在全文中,Client 均指代浏览器,笔者有时也会称之为客户端;而 Server 则指代服务器一方。

在建立 HTTP 连接之前,双方会率先通过三次握手建立 TCP 连接。对于 HTTP/1.0 协议来讲,客户端和服务器进行一次请求/响应之后连接就会断开,或者通过Connection:keep-alive主动保持一段时间的连接。而在 HTTP/1.1 协议中,默认允许连接会保持一段时间,直到有一方主动发送Connection:close。
当然,在此之前还有很多的准备工作。比如说浏览器会率先检查 URL 是否合法(见URL编码规则);基于ARP 协议获取网关的 MAC 地址;按照以下顺序进行 DNS 域名解析:本地 Host 文件 -> ISP 提供的本地 DNS 服务器 -> 权威域名服务器 ->根域名服务器......经过一系列的步骤,浏览器获悉了域名实际的 IP 地址,并最终建立起 TCP 连接,建立 Socket 通信......
算上 TCP 连接所消耗的时间,一个 HTTP 请求响应需要等待 2.5 个 RTT 时延。
HTTP/1.1报文结构
目前 HTTP 协议中的报文可分为两种:请求报文(浏览器发送),响应报文(服务器发送)。这两种报文结构有些差异。大致来看, HTTP 报文可分为头和体两个部分。
头部总共分为四种:通用头部,响应头部,请求头部,实体头部。一个 HTTP 报文中会包含多个头部,HTTP 请求/响应报文均适用通用头部,实体头部。
通用头部
通用头部主要包含了此连接的基本信息(比如告知连接时间,是否保持长连接等),以及缓存相关的内容。这里仅介绍常用头部的常用值。我们也可以自定义一些头部,比如自定义一个 token 作为用户凭据,但是这要求前后端都能够理解它的含义并正确处理。
下面是 4 个常见头部:
Cache-Control:no-cache:强制对重复的请求发送到服务器进行验证,若未过期则返回缓存内容,否则返回新的内容。no-store:不缓存。
Date:Tue, 23 Jun 2020 07:59:00 GMT:表示发出请求/响应的时间,由浏览器或者服务器自动生成,满足RFC822定义的格式。缓存机制使用请求的Date来判断是否可以直接响应缓存内容。
Connetion:Close:在本次请求完毕后,立刻关闭连接。keep-alive:在本次请求完毕之后,保持一段时间的连接。常和Keep-alive头一同使用。
Keep-alive(若Connection头为keep-alive):n:这个n代表秒数。指在多少秒内保持连接不会关闭。
这里笔者额外提一下缓存机制。其过程大概是:如果同样的请求已经保存到缓存中,且没有过期,则直接获取缓存的内容。Cache-Control头其实远不止no-cache和no-store两项,实际上 HTTP 提供了相当多的头部来进行灵活控制。由于缓存机制的存在,浏览器能够快速加载我们曾访问过的站点页面。
打开 Chrome 浏览器进行时延,我们刷新同一个页面,并打开 Network 分析观察:大部分文件都是来自于本地缓存。
🌎了解更多有关浏览器的缓存机制。
实体头部
HTTP协议的全称:Hyper Text Transfer Protocol,即超文本传输协议——它表示什么类型的文件都可以通过这个协议传输。这个文件会作为实体装入到 HTTP 请求/响应头中进行传输。
为了保证双方都能理解对方发送的实体是何种文件类型,因此我们需要使用实体头部对传输的内容加以描述。下面仅展示常见的实体头部。
如果我们打开来自服务器的页面或者文件却显示乱码,则多半是双方所采用的字符集设定不一致所导致的问题。
| 头部 | 作用 |
|---|---|
Allow | 服务器对于非法的方法请求,会返回 405 错误。此时服务器设置此头部告知此 URL 允许的请求方法。 |
Content-Length | 实体内容的大小,按字节计。 |
Content-Encoding | 服务器端告知实体的压缩方法,比如 gzip , deflate 等,大文件一般都会选择先压缩再发送。 |
Content-Type | 实体的媒体类型。可指定charset字符集编码类型,分号隔开。 |
Content-Language | 实体内容的自然语言,如中文为 zn-CN 。 |
Expires | 表示该资源的过期时间。浏览器会结合Etag检查缓存的文件是否过期。 |
Etag | 返回文件的签名,用来判断文件是否被修改过。如果文件发生变更,浏览器会重新向服务器中请求一份更新过的资源。 |
其中Expires/Etag头的缓存功能,使用cache-control同样可以实现。两者同时存在的情况下,浏览器优先选择cache-control。
Spring Boot 对 Allow 头部的处理
Spring Boot 框架对指定映射的方法限制十分简单,只需要在@RequestMappping中添加 method 值就可以了。method是一个RequestMethod[]类型的变量,因此可以使用{}涵盖多个允许的请求方法。
@RequestMapping(value = "/hi",method = {RequestMethod.GET,RequestMethod.HEAD})public@ResponseBodyString get(){
//TODO ...
}
常用的 Content-Type 类型
| 值 | 作用 |
|---|---|
text/plain | 纯文本格式。 |
text/html | 返回 html 文件。 |
image/gif | gif 图片格式。 |
image/jpeg | jpg 图片格式。 |
image/png | png 图片格式。 |
application/x-www-form-urlencoded | 上传内容仅为k-v键值对的表单。 |
multipart/form-data | 当在表单时上传二进制文件(图像,视频,压缩包)等时。 |
application/xml | 以xml文件格式进行数据交互,不过笔者基本没使用过这种方式。 |
application/json | 以json文件格式进行数据交互。目前的前后端分离项目中,页面与服务器沟通的常见形式。 |
对于application/json的数据类型,Spring Boot 可以使用@RequestBody很容易地提取出前端所提交的 json 内容,也可以通过@ResponseBody将一个对象转换成json格式返回给前端。
笔者顺便在文末准备了一个简单实战:基于 Spring Boot 接收文件,并发送到 Nginx 代理服务器。感兴趣的同学可以见文章末尾,或者选择跳过此部分。
HTTP 请求报文
一个 HTTP 请求报文由以下几部分组成:请求行,通用头部,实体头部,请求头部,请求体。
请求行
我们平时在浏览器中只需要输入www.baidu.com就可访问到百度页面了。而实际上,一个完整的请求行包括了请求方法,目标服务器URL,以及HTTP版本号。
CONNECT www.baidu.com:443 HTTP/1.18种请求方法
请求方法,我们最熟悉的就是 GET 和 POST 方法了。而实际上,请求方法包含了 8 种。
HTTP/1.0 版本为止,支持三种请求方法:
| 方法 | 作用 |
|---|---|
GET | 从指定的URL当中获取数据。 |
POST | 向指定的URL提交数据,比如提交一个form表单。 |
HEAD | 从指定的URL当中获取数据,但只需要HTTP报文头。 |
HTTP/1.1版本额外规定了5种请求方法:
| 方法 | 作用 |
|---|---|
OPTIONS | 返回服务器所支持的HTTP方法,出现在预检请求当中。 |
PUT | 向指定的资源位置上传最新的内容。 |
DELETE | 请求服务器删除指定资源位置上的内容。 |
TRACE | 回显服务器收到的请求,用于测试与判断。 |
CONNECT | 将请求连接转换到透明的TCP/IP连接当中。 |
注:OPTIONS 方法用于发起非简单的跨域请求,它与CORS有一定的关系。
GET 与 POST 方法的区别
- GET 在浏览器回退时是无害的。但是 POST 会再次提交请求。
- GET 请求只能进行 URL 编码,但是 POST 可以设置多种格式。
- 受限于 URL 的长度限制,导致 GET 请求中的参数也有长度限制。
- GET 的参数直接暴露在 URL 上,不可以用来传输敏感数据。
- 一般情况下, GET 参数不需要请求体,而 POST 参数放在请求体当中。
浏览器如何处理 GET 和 POST 方法
由于 POST 会携带更多的数据,所以在一般情况下,浏览器可能对 POST 请求会做两步操作。
对于 GET 方式的请求,浏览器会将 HTTP Header 和参数一同发送出去,服务器返回一个 200(表示OK)。
对于 POST 方式的请求,绝大部分浏览器会先发送 Header ,服务器响应 100(表示continue),浏览器再发送内部的请求体,服务器再返回 200(表示OK)。这其实取决于浏览器的策略,主要是为了防止浪费网络资源,尤其是提交大量数据的时候。
无论浏览器会将一个 POST 请求一次发送还是分批发送,对于服务器来说没有区别,日志只会记录一行 POST 记录,这点要注意。
GET 与 POST 的界限
GET 与 POST 是语义上的区别。GET 请求也可以携带请求体; POST 请求也可以在请求 URL 带上少量的参数。但是服务器一般不会对这些多余的内容进行处理。
- 对于获取资源的行为,我们使用 GET 请求。
- 对于提交 form 表单的行为,或称提交资源的行为,一般都采取 POST 请求。
详情见此文章:Get与Post的区别?(面试官最想听到的答案)
URL 编码规则
目前的浏览器普遍使用 UTF-8 对 URL 进行编码,而老版 IE 会对根据系统的默认设置对 URL 进行编码。另外顺带一提,我们平时所说的 Unicode 是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。像 UTF-8 ,UTF-16 都是对 Unicode 进行存储的实现形式。
笔者浏览器中输入了:
localhost:8080/test/hi?name=你好但是我们通过抓包工具可以发现,实际上这个URL被编译成了这个样子:
localhost:8080/test/hi?name=%E4%BD%A0%E5%A5%BD实际上E4 BD A0是你汉字对应 UTF-8 编码的十六进制表示,一个汉字需要 3 个字节来存储。(汉字在Unicode字符集中用2个字节来表示,但是 UTF-8 用3个字节来存储它)
另外,URL规定,仅允许出现这些字符:
ASCII字母,数字,~, ! ,@, #, $, & ,*, ( ), =,: ,/,, ,;, ?, +, '(注:这是单引号,若果双引号"会被编码 %22)
对于URL编码的详细解读可以参考:URL编码规则
请求头部
请求头部表明了这个请求发起者的身份,以及要向哪里发出请求,客户端对信息的处理能力等等。服务端可以根据用户的需求来提供更人性化的服务:比如说服务器可以根据请求的Accept-Language来推断出客户的国家/地区,并将网页内容翻译对应国家/地区的语言。(即国际化)
在之前我们介绍过Expires和Etag实体头部,浏览器缓存机制使得浏览器尽可能不去向服务器访问资源,来节省网络连接带来的时延。在 HTTP/1.1 协议中,增加了许多IF头部,使得浏览器缓存策略变得更加灵活。
下面介绍主要的请求头部。
| 头部 | 作用 |
|---|---|
Accept | 告知服务器该请求希望接收的文件类型,和Content-Type对应。*/*表示允许接收任何类型的反应。 |
Accept-Charset | 告知服务器自己接收的字符集编码。 |
Accept-Encoding | 告知服务器客户端支持的压缩方法,和Content-Encoding对应。 |
Accept-Language | 告知服务器客户端希望被提供的自然语言服务,比如中文,日文,英文。 |
If-Match | 如果请求对象的Etag没有变化,则重新请求一份资源。 |
If-None-Match | 如果对象的Etag没有变化,则重新请求一份新的资源。 |
If-Modified-Sinze | 如果请求的资源在指定的格林威治时间之后发生更改,则重新请求一份新的资源。 |
If-Unmodified-Since | 如果请求的资源在指定的格林威治时间之后都没修改,则重新请求一份资源。 |
Host | 客户端指定要请求的WEB服务器域名,IP地址以及它的端口号。 |
Refer | 客户端表明自己是从哪个网页的URL发起的请求,可用于跨域检查。 |
User-Agent | 客户端表明自己使用的浏览器型号。 |
HTTP 响应报文
HTTP响应报文包括以下部分:状态行,通用头部,实体头部,响应头部,响应实体。
状态行
下面就是一个HTTP响应报文的状态行:
HTTP/1.1 200 OK状态行包括了HTTP协议号,状态码,以及一个简要的文本描述。200是我们最希望得到的结果。当发生了预料之外的错误时,服务器会设置不同的状态码提示客户端发生了什么错误。
大体上我们可以将状态码归为5类:
| 状态码 | 含义 |
|---|---|
1xx | 请求已收到,会继续处理。 |
2xx | 请求已经被成功接收,理解。 |
3xx | 请求的资源被重定向了。 |
4xx | 客户端发生了错误。 |
5xx | 服务端发生了错误。 |
下面列出常见的状态码:
| 状态码 | Phrase | 含义 |
|---|---|---|
| 200 | OK | 客户端请求成功 |
| 304 | Not Modified | 请求的资源服务器端未修改,客户端可继续使用缓存上的资源。 |
| 400 | Bad Request | 客户端的请求不合法,通常是没有按要求填写URL的参数。 |
| 403 | Forbidden | 服务器理解客户端请求,但是拒绝提供服务,如权限不足。 |
| 404 | Not Found | 资源不存在。 |
| 415 | Unsupported Media Type | 服务器无法处理请求方发送实体的Content-Type格式。 |
| 500 | Internal Server Error | 服务器发生了内部错误。出于安全考虑,需要开发者主动对客户端隐藏出错的细节。 |
| 502 | Bad Gateway | 代理服务器未得到远端(上游)服务器的正确响应,常见于 Nginx 等代理服务器。此时需要检查上游服务器的状态。 |
| 503 | Server Unavailable | 客户端当前不能处理客户端的请求。通常是服务器无法承受大量的请求所导致的。 |
| 504 | Gateway Timeout | 代理服务器没有及时从上游服务器中收到响应。常见于 Nginx 等代理服务器。 |
响应头部(基本)
| 响应头 | 作用 |
|---|---|
Refresh | 指定时间和新的URL(分号分隔),指示浏览器进行重定向。如 4;https://www.baidu.com 。 |
Server | 处理此请求的服务器名称。如Server :nginx/1.6.3。 |
Set-Cookie | 设置 HTTP 的 Cookie 。每一个 k-v 对占一个单独的响应头。 |
Accept-Ranges | 服务器表明是否接收某个文件/实体的一部分。bytes表示接受,none表示不接受。 |
Vary | 用此头部告知缓存服务器,在什么情况下使用本次返回的实体响应后续的相同请求。[1] |
[1]:假定现在有WEB服务器S1(可以将实体内容进行 gzip 压缩),另有 Cache 服务器 S2 。客服端使用两个浏览器 B1,B2;其中仅 B1 支持对 gzip 压缩的实体进行解码。
Web 服务器 S1 考虑到当用户使用浏览器 B2 时,无法处理缓存服务器 S2 返回的被 gzip 压缩的实体内容,于是 S1 的响应头中有两项:Content-Encoding:gzip;Vary:Content-Encoding,即告诉缓存服务器 S2:只有后续的请求允许 gzip 解码,才会将缓存的内容发给它。
因此当用户使用浏览器 B2 访问该资源时,由于浏览器 B2 本身就不支持 gzip 编码,它发出的请求头自然不会包含Accept-Encoding:gzip。该请求在缓存服务器 S2 验证不通过,浏览器 B2 最后只能直接向 Web 服务器请求未经 gzip 压缩的实体内容。
响应头部(跨域)
下面的响应头专门用于处理跨域情况。检查跨域是浏览器行为,浏览器会检查服务器的响应头判断这个跨域请求是否是合法的。
笔者之前也通过网络资源整理过跨域的文章,并决定将那篇文章合并到这来。你可以选择在浏览完后面的跨域章节之后再回来了解这些请求头。
| 响应头 | 作用 |
|---|---|
Access-Control-Allow-Origin | 设置允许的跨域网站(源)。在某些情况[1]不允许设置为*。 |
Access-Control-Allow-Method | 允许的请求方法,即 HTTP/1.0/1.1 中介绍的8种方法。 |
Access-Control-Allow-Header | 允许携带的请求头。 |
Access-Control-Allow-Credentials | 设置是否允许浏览器读取跨域请求的响应的内容。 |
Access-Control-Max-Age | 对于非简单跨域请求,如果得到了允许,则在此规定时间内无需再次发送预检请求。 |
Access-Control-Expose-Headers | Ajax 使用 XMLHttpRequest 对象获取响应头时,只被允许获取基本的头部[2]。因此需要设置允许额外暴露的响应头。 |
[1]:"某些情况"指需要携带Cookie进行身份验证的请求,CORS机制不允许服务器将Origin草率地设置为*(代表允许所有的跨域源),这是出于避免 CSRF 跨域攻击的角度考虑的。
[2]:表格中“基本的头部”是指:Cache-Control,Content-Language,Content-Type,Expires。
HTTP 的进化史
1991年诞生了最早版本的 HTTP/0.9 协议。在当时规定,客户端只支持发送 GET 请求,服务器只能返回 <HTML> 标签构造的超文本内容。服务器在做出响应之后,会立刻关闭TCP连接。
| 版本 | 时间 | 内容 |
|---|---|---|
| HTTP/0.9 | 1991年 | 只能通过 GET 方法向服务器发起简单请求。 |
| HTTP/1.0 | 1996年 | 增加了 Status Code 和 Header 。 |
| HTTP/1.1 | 1997年 | 持久连接,新增管道机制,分块传输文件。 |
| HTTP/2 | 2015年 | 多路复用,服务器推送,头信息压缩,二进制协议等。 |
| HTTP/3 | 2018年 | 基于 UDP ,快速握手,升级的多路复用,优化拥塞控制等。 |
HTTP/1.0
在 1996 年推行的 HTTP/1.0 协议中才算实现了真正意义上的"超文本"——即支持任何 MIME-Type 类型的文件。另外,新增了 POST 和 GET 命令,极大的丰富了客户端和服务器交互的方式,即客户端也可以通过表单的方式提交数据了。
在 1996 年的 HTTP/1.0 报文推行之后,请求报文和响应报文还要带上各自的头部描述请求/响应的信息,如客户端需要表明自己的身份user-Agent,允许接受的响应类型Accept。响应报文则用状态码表明响应状态,服务器类型Server和返回实体的类型Content-Type等等。
局限性
HTTP/1.0 版本的局限性在于:一次 TCP 仍然只能一个请求-响应。如果客户端要请求其它资源,则必须重新新建连接。TCP 的连接成本并不低,除了新建连接需要 1.5 个 RTT 时间之外,另外由于拥塞控制的慢启动机制,在开始时的传输速率比较慢。
人们觉得“一问一答”之后即关闭 HTTP 网络连接的方式有点浪费得之不易的 TCP 连接资源。在当时就有人提出:使用一个Connection:keep-alive让这个连接再保持一小段时间,直到浏览器和服务器方有一个主动关闭了连接。
HTTP/1.1
在 HTTP/1.0 发布的不到半年,1.1 版本就紧随其后,并且在相当长一段时间内都是最通用的版本,原因就在 于 HTTP/1.1 除了增加 PUT ,OPTIONS 等5个新的请求方法之外,还做出了以下重大更新:
持久化连接
在这里要强调一点,持久化连接不意味着长连接。 HTML5 发展出一个单独的技术来维持长连接,那就是 WebSocket 协议。这个协议目前基于 HTTP 协议建立连接,我们在后续的篇章会介绍它。
HTTP/1.1 默认 TCP 不会立即关闭,一个持久连接能够传输多次请求响应,不用声明Connection:keep-alive。直到消息发送完毕时有一方主动发送Connection:close来主动关闭连接。对于同一个域名,浏览器允许同时建立6个持久连接。举个通俗的例子,就是一个超市有 6 个收银口供顾客结账,顾客可以在任意一个收银口排队等待。
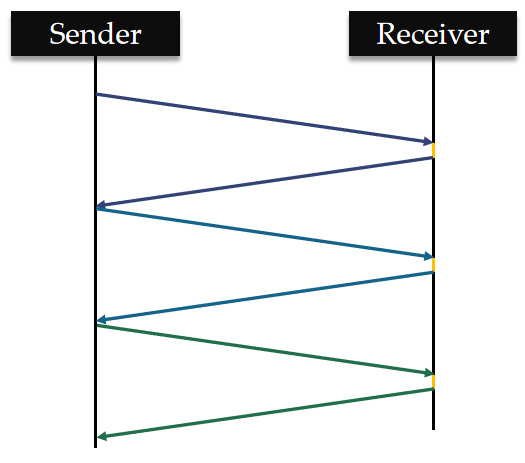
管道机制(Pipeline)
同一个 TCP 连接里,客户端可以发送多个请求。客户端会以串行形式依次发送请求并等待接受响应:先发送请求Request1,在得到 Response1 之后,再发送 Request2 ,收到 Response2 之后再发送 Request3 .......
Content-Length
由于一个 TCP 连接支持了多个请求响应,因此服务器每次发送完一个响应都要额外附加Content-Length头部表明本次响应已经结束,下一次发送的数据是下一次请求的响应了。
Chunked
使用Content-Length字段意味着,**服务器要事先一次性处理并分析完响应数据,才会知道响应的长度。**对于耗时的操作,服务器要先将所有的操作都完成,才能将数据发送出去,这样的效率并不高。
因此 HTTP/1.1 还规定,可以使用分块传输编码机制(chunked transfer encoding),如果一个 HTTP 报文头部包含Transfer-Encoding:chunked,它就表示这是一个完整实体块的其中一部分。每个非空数据块前面都会有 16 进制数表示该块的长度。最后发送大小为 0 的数据块表示“本批货物已经发送完毕”了。
队头阻塞问题
尽管 HTTP/1.1 采纳了管道方式连接,但是注意,这是串行操作。所有的请求就相当于在一个队列当中按照 FIFO 的规则处理。如果说队头的某个请求处理速度非常慢,则会导致后续的请求全部积压到队列中处于等待状态。这种现象称之为"队头阻塞"(Head-of-Line Blocking)。
有相当长的一段时间里,队头阻塞都是 HTTP 协议优化部分的心头之患,这个问题直到 HTTP/2 也没有得到彻底解决。
重复的头部信息
在 HTTP/1.0 协议之后的版本,几乎每个请求后面都会携带大量的 ASCII 编码的头部,或者是大量的 Cookie 内容。如果一个页面的大部分资源都来自于同一个服务器,则在大批量的请求中,这些大量重复的请求头会对本就拥挤的网络带来了更多的负担。
HTTP/2的诞生
从 HTTP/1.1 到 HTTP/2.0 版本又是一个大步的跨越。 HTTP/2 做了以下更新:
二进制协议
在 HTTP/2 协议中,头和体被分别包装到了以二进制为基础的帧(frame)单位中。
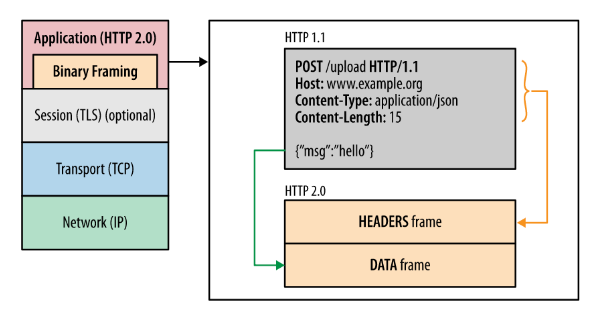
注:TLS 层和 HTTPS 协议有关,我们稍后就会提到它。
头部信息压缩
我们刚才在 HTTP/1.1 协议的介绍当中介绍了重复的头部信息所带来的麻烦,当然这实属无奈之举,因为 HTTP 协议本身是无记忆的,这也是我们为什么使用 Cookie 和 Session 来维持 HTTP 连接的记忆。
HTTP/2 协议如何优化的呢?首先,大量的头信息会经过 gzip 或者是 compress 压缩,除此之外,浏览器和服务器同时维护一个头信息表。一个索引存储着一个头部集合。这样,双方的头部信息只需要相互告知索引号就可以解决了。
服务器推送
HTTP/2 允许服务器在响应对应的请求时向客户端推送额外的资源。这个动作称之为 push 。
下面用一个情景来类比:客户在某个商家购买了电脑。正常情况下,商家只需要按部就班地将电脑发货即可。可是考虑到用户以后可能还会需要其它服务,商家就顺带着将维修站点,配件商店的联系地址一同发给了用户。这样,用户在有需求的时候就不用再额外联系店家了。从出发点来看这个功能是很好的,因为服务器推送功能既提高了 TCP 连接利用率,又方便了客户端。
❓但是相比其它几个特性来说,这个描述似乎让人觉得模棱两可——什么样的数据算是额外的数据,服务器又怎么确定客户端一定会需要它呢?
这个特性是存在一些争议的。它打破了 HTTP 传统的“一问一答”模式,使得客户端在并没有明确需要的时候,服务器就推送额外的数据。这种做法难以保证不会被滥用(比如现实生活中烦人的广告推销)。同时,服务端也可能不顾客户端的缓存,执意重复推送,造成带宽浪费。
多路复用
首先需要了解HTTP/2协议中的四个层次:
- 帧(frame):是最小的数据单位,无论它内部装载的是传输 HTTP 首部,或者是实体内容。
- 消息(message):多个帧所组成的一个完整的请求/响应。
- 流(stream):每一个请求和对应响应的帧都会加上一个共同的 ID 进行分组,每个组从逻辑上被称之为流。比如说客户端对同一个服务器同时请求了 a.html , b.css , c.js 三个文件,则对每个文件的请求和响应分别在三个流当中进行,流和流之间互不干扰。
- 连接(Connection):指一个 TCP 连接。大多数HTTP连接的时间都非常短,并且具备突发性。按理来说,我们一次性传的数据越多,TCP 连接的效率越高;否则颇有杀鸡用宰牛刀之嫌。
那么何为多路复用呢?通俗的解释就是对相同目标服务器的多对请求/响应变成了单独的流,这几股流全部合并到一个 TCP 连接当中。因为每个帧有流进行标识,双方在 HTTP 层面上可以乱序方式发送帧数据,然后各自通过标记将同一个流的响应/请求进行组装。
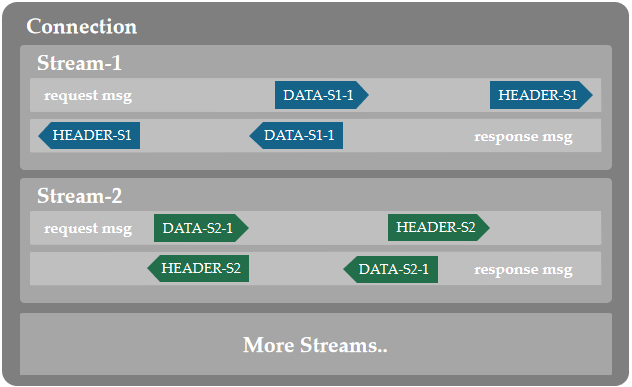
HTTP/1.1 协议中,如果一个请求的响应非常耗时,则后续的整个请求都被阻塞。HTTP/2 协议改善了这个问题,使得各个请求/响应在 HTTP 的层面上变得并行了,因此极大提高了传输效率。至于快到什么程度呢?可以参考下面的例子。
直观对比HTTP/1.x vs HTTP/2
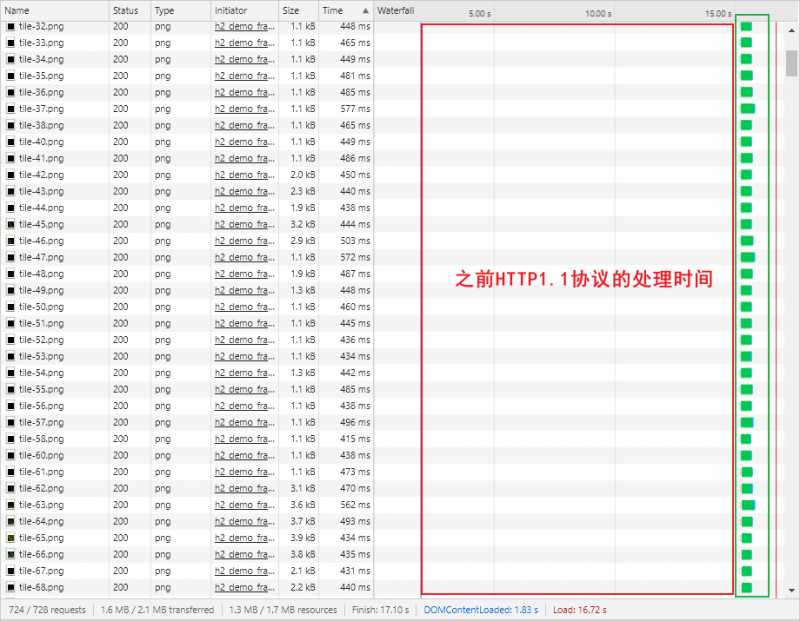
大家可以去Akamai的网站体会 HTTP/1.1 和 HTTP/2.0 的传输速率差距,这个网站会分别基于 HTTP/1.1 协议和 HTTP/2 协议向服务器请求 350 多张零散的图片组合成一个“地球”:

打开 Chrome 调试模式,查看请求的瀑布流:(Waterfall)
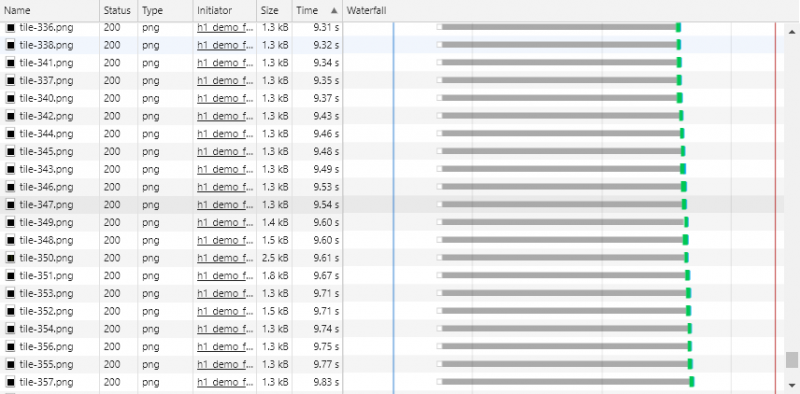
由于页面同时请求的资源过多,HTTP/1.1 允许开放的 6 个连接全部都发生了队头阻塞的问题。我们点开其中一个请求,如下图所示,发现每个请求的 Stalled 状态占了绝大部分时间,但真正建立连接并下载资源的时间却微乎其微。
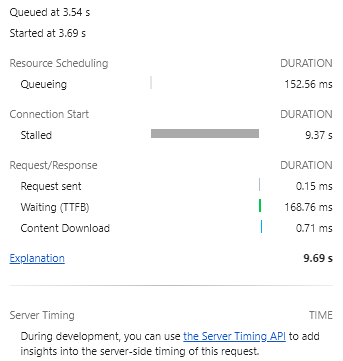
而在 HTTP2.0 协议下,由于引入了多路复用机制,因此几乎所有的图片都在同一时间加载完成。当然,这个前提条件是:与服务器端的 TCP 连接是整体稳定的。
🌎若想进一步了解 Chrome 浏览器 Waterfall 内容,可参阅以下文章:
- 前端性能之Chrome的Waterfall
- 分析Chrome的瀑布流
🌎想了解更多 HTTP/2 的细则,可参阅以下文章:
- HTTP/2 十分中速知
HTTP/2 真的解决队头阻塞了吗?
并没有彻底解决。因为从 TCP 发送窗口的角度来看,无论哪个流的帧,它们仍然需要在发送窗口中排序等待发送。如果发生了丢包现象,则整个发送窗口都要等待丢包重传,直到将丢失的包补齐为止。
另外,我们之前介绍过的 TCP 拥塞控制:慢启动,快恢复等,这些机制导致 TCP 协议在弱网环境下的表现并不佳,且会直接影响到上层 HTTP 通信的效率,哪怕它们使用的是 HTTP/2.0 协议。
TCP 协议栈通常由操作系统实现,换句话说它已经植入到 Linux 、 Windows 内核或者其他移动设备操作系统内根深蒂固。修改 TCP 协议是一项浩大的工程,还要让广大的用户进行升级,因此对 TCP 进行大刀阔斧的改造并不现实。正因如此,后来的 Google,IETF 等团队和组织将下一代 HTTP 建设的希望寄托在了UDP 协议上,QUIC 就是这样诞生的。
HTTPS
HTTP协议传输方式是:HTTP->TCP。而 HTTPS 协议的传输方式是:HTTP->TSL->TCP。
HTTPS利用了非对称密钥交换协议,保证了在不安全的数据通道中,产生只有通信双方才知道的对称加密密钥。
HTTPS的交互可以分为两个阶段:
- 客户端基于非对称加密方式进行身份验证,双方互相交换随机数。
- 身份验证通过后,双方基于交换得到的随机数各自在本地用事先协商好的加密算法生成对称密钥,之后的双方通讯将是对称加密方式。
这么做的原因是,非对称方式的安全性高,但是计算量大,数据交互的效率远不及对称加密方式,所以双方在 TLS 握手之后采用对称加密进行通讯。
在网络上,安全的网络通讯需要保证两点:
对方的身份首先是可信的,否则加密通讯本身就失去了意义。
- 保证用于生成密钥的关键数据不会泄露。
为了顺利地介绍 HTTPS 的工作流程,因此我们有必要先聊一聊有关加密的基础知识,尤其是非对称加密。
非对称加密技术
如何证明“你”是“你”呢?无非向大家证明一件只有你能做到的事情,“你”便是“你”。
HTTPS 需要非对称加密技术来实现安全。非对称加密最早可以追溯到锁的发明:
锁头所在门外,谁都可以看到,但是钥匙只在房子主人的手上。
在计算机中,**有这样一对钥匙,其中一把是公用的,我们称之为公钥;其中一把只有某个人持有,我们称之为私钥。**它们有这样的特性:
- 若消息被公钥加密,则只有对应的私钥能解开。——(1)
- 若消息被私钥加密,则只有对应的公钥能解开。——(2)
当然,公钥私钥的概念和现实中的锁还是有区别的——毕竟没有哪个锁配有两个锁芯。注意,这里的“非对称”指“无法根据公钥推断私钥”(笔者稍后会给解释),而不是"私钥加密,公钥无法解密"。
HTTPS 协议当中,RSA 算法和 ECC 算法是常用的非对称加密技术的实现。在 TLSv1.3 章节之前,笔者暂时默认使用 RSA 算法进行介绍。
首先假设现在有两个主人公A和B。A有一对公钥私钥,称之为public key A和private key A;B有一对公钥私钥,称之为public key B和private key B。基于上述两个特性,我们可以有两个用途:
公钥加密,私钥解密
若 A 想发给 B 私密消息,则 A 会利用特性(1),用public key B对私密消息进行加密。这样,因为只有 B 持有private key B,因此这个消息只有对 B 来说是有意义的。
私钥签名,公钥验证
若 A 想要和 B 签署一份合同,B 要求证明这是 A 本人同意以上条款并签的字,且保证这个合同将来不会被 A 篡改(不可抵赖性),A 这时就会用到特性(2)了。因为只有 A 拥有private key A,这个专属私钥代表了 A 的身份。
如果说有个信息 message 可以用public key A解密,则根据性质(2),可以推断出一定是 A 本人对它加密的,因为只有 A 才持有private key A。
我们也可以发现,当利用性质(2)时,是不对 message 本身的机密性保证的,因为任何人都可以拿到public key A去解密。它的作用是证明这个 message 确实是 A 发出来的,而非用于保证此消息的机密性。此时,这种加密/解密从语义上称之为签名/验签。
如果需要保证 message 的机密性,A 自然会想到利用性质(1),使用对方的公钥进行加密并传输,所以性质(1)和性质(2)并不矛盾。
实际上的签名/验签,或者说 A 和 B 之前要签署一份合同,除了要证明 A 本人同意并签字之外,还要保证 A 事后不能篡改(或称拒绝承认)当时所发的消息,即我们要保证合同的不可抵赖性质。
下面用一份伪代码叙述这个过程。假定 A 和 B 在事先约定好了某个摘要算法 Hash(·),合同内容为 contract ,它经摘要算法得到的结果称之为 digest:
# A加密消息发送给BHash(contract) -> digest;
签名(private_key_A, digest) -> signature;
加密(public_key_B,(contract,signature)) -> encrypted_data;
# 因为B使用了自己的私钥解密,因此这个过程也证明了B自己的身份。
解密(private_key_B,encrypted_data) -> (contract,signature);
# B收到A的消息,验签通过,则说明是A本人签的字。
验签(public_key_A,signature) -> digest
# B自己再用与A协商好的Hash算法亲自计算它所得到的contract的摘要digest',并与A声称的digest对比。
Hash(contract) ->digest'
if(digest'==digest) -> 得证contract没有被篡改。
摘要算法正是对文件的不可篡改(不可抵赖)性质做出了保证。
先有公钥还是先有私钥?
这里涉及到有关哈希函数的一个重要性质:
- Hiding: Hash 函数的计算是单向的,设 H(·) 是 Hash 函数,H(x) = y。这个特性描述了:只需要一次验证,就可以得到 H(x) 是否等于 y;但反过来只知道 y,不存在有效的手段推测哪个x'会使得H(x') = y。
所以基于这个特性,我们选取 x 作为私钥,选取 y 作为公钥。公钥 y 需要向大家公布,而哈希函数的 Hiding 特性保证了任何企图根据公钥 y 推导其私钥 x 的做法都是不可行的,除非使用效率极其低下的蛮力枚举。
因此,用户会首先自己设定私钥 x (或者是用户本人的生日,或者是程序随机生成的字符串),然后再根据此私钥 x 生成公钥 y ,将公钥 y 放入SSL证书当中。私钥 x 只保存在用户手里,仅当签名或解密密文时用到,不会体现在任何其它地方,更不会写入到 SSL 证书内部。
私钥一旦泄露(或有这种可能),则这一个公私钥对都应该作废处理。出于安全性考虑,保存公钥的 SSL证书存在有效日期,以强迫用户定期更换自己的公私钥。
CA认证机构——抵御 MITM 攻击
在HTTPS加密过程当中,有一个专门保管公钥的机构:CA(Certificate Authority)。仅仅是使用非对称加密技术难道不够用吗?笔者刚才提到了一点:对方的身份首先是可信的,否则加密通讯本身就失去了意义。
我们暂且不提 CA,列出理想状态下的非对称加密通讯过程。注意,下面不是 HTTPS 交互过程,只是为了说明 CA 机构存在的意义。
- Client 先向 Server 索要它的公钥。
- Server 向 Client 提供自己的公钥。
- Client 使用提供的公钥加密,发送给 Server 。
- Server 收到了加密信息,并使用自己私钥解密。
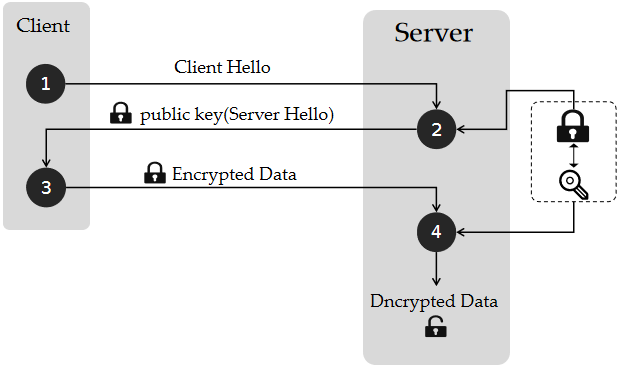
如果第一步和第二步没有发生意外,保证了 Client 拿到的一定是对应 Server 的公钥,那么这个信息交互没有问题。
但这有一个致命的缺陷:如果第二步中, Server 的公钥被某个中间人截获的话,那么 Client 发送的加密信息对 Server 就是无效的。重点是,中间人在截获 Client 的加密信息之后可以拿自己的私钥取出客户所发送的私人信息。这种方式的攻击称之为 MITM(Man-In-The-Middle)——中间人攻击。
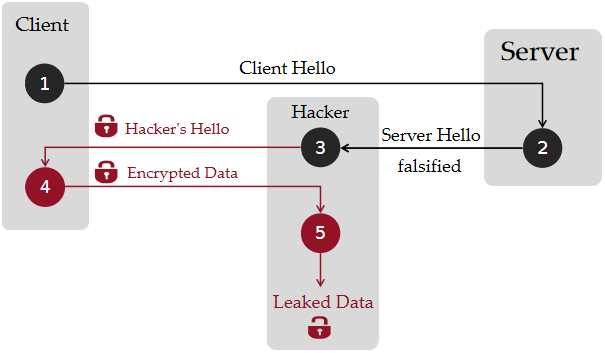
因此在整个 HTTPS 传输的过程中,我们还需要权威的 CA 机构来做公证人,代替验证某个公钥和某服务器的一对一对应关系。
权威 CA 机构也需要有用于”自证权威性“的证书,包括 CA 机构的公钥。世界上所有权威 CA 认证机构的证书已经内置在了各大主流浏览器中。
SSL 证书
首先, Server 服务器会向签发人(issuer)提交自己的公钥,组织信息,个人信息,域名信息等信息,签发人会通过线上联络或线下调查的方式考证其真实性。
审核通过,签发人向 Server 签发认证文件,即我们所说的证书。它包含了以下主要信息:证书有效时间,证书序列号,签发人所在域名 DN(DNS Name,指有效的DNS域名。下同), Server 的公钥, Server 的其它组织信息,证书摘要信息,以及签发人的私钥签名。
有些证书没有签发人,那么这个证书就是自签名证书。只有浏览器无条件信任的权威 CA 机构才有权签发自签名证书,否则就是非法的证书,不被浏览器认可。
HTTPS 的加密工作由 TLS 来完成,我们稍后就会提到它。而 TLS 的前身则是 SSL 标准技术,因此我们习惯称这个证书为 SSL 证书。另外,有些人习惯还根据选择的加密方式不同,称 SSL 证书称为 RSA 证书,ECC 证书, DSA 证书等等。下文中提到的证书如果没有特指,均指代广义上的 SSL 证书。
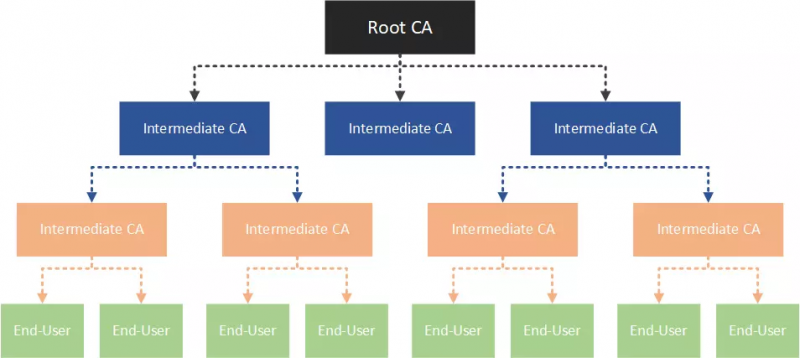
证书链
在真正签发证书的过程中,签发人 Issuer 未必就是浏览器直接认证的权威 CA 机构,也有可能是某个中介机构 B。那中介机构怎么证明自己的权威性呢?中介机构 B 可能又声称自己是经过中介机构 A 认证的......
简单来说,签发人可能会经过很多个级别。那么验证的过程中,要对整个链条中涉及的机构进行认证,这个链条就是证书链。其在 root 位置的签发人一定是浏览器所信任的权威 CA 机构,整个证书链才是合法的。
服务器需要提供完整的证书链:
- 根据此证书的签发人机构DN,向上一级签发人请求证书,放入到证书链中。
- 如果这个 CA 机构的证书内部还有签发人机构 DN,就递归第一步,否则就是自签名证书,返回这个证书后结束递归。
浏览器先从 Server 获取这个证书链,从"最底层"的证书开始一个循环过程:
尝试从上一级证书中提取公钥,来验证本级证书的签名。检查通过,则继续检查上一级证书,否则判断该证书链不合法,退出判断。
如果本级证书没有再上一级的证书了,就说明这应当是一个 root CA 机构的自签名证书,对于浏览器认可的 root CA,返回它的公钥(浏览器内置合法CA的根证书,无条件信任这个公钥的合法性)。如果该 root CA 不被认可或者验签失败,则最终判断该证书链不合法,退出判断。
如果证书链还有等待验签的证书,继续这个循环。
长话短说,服务器会不断地 Get certificate 并返回,而浏览器拿到这些证书后会逐层地 verify signature。
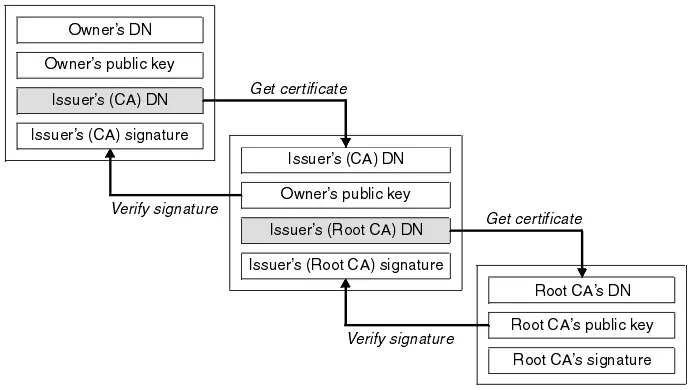
🌎这部分知识点的"签发者"来源于这个链接。
SSL 与 TLS
HTTP 只专注于消息传输,验证身份和生成随机密钥等工作,是计算机的TLS层来完成的。
HTTPS 协议最初是使用 Netscape 公司打造的 **SSL(Secure Socket Layer)**进行加密的。SSL 作为 HTTP 和 TCP 的中间层,将所有过往的 HTTP 报文进行加密。
互联网标准化组织 IETF 认为:SSL 协议可以有更广泛的用途,而不仅限于 HTTP 协议。因此 IETF 在 SSL 基础上又加了一个 Application Protocol 类型字段,希望 SSL 能在更多的场合发挥作用,随后 SSL 发展为了当下的 **TLS(Transport Layer Secure)**协议。
可以将 TLS 理解成是 SSL 协议的升级版,也有些人将它们统称为TLS/SSL。
TLSv1.0 基于 SSLv3.1 发展,最新的版本是 TLSv1.3 。使用 Wireshark 工具进行抓包的话,我们可以从端口号和协议类型TLSv1.x判断出这是一个经加密处理的 HTTP 报文。
题外话:区分 SSL 和 SSH
SSH(Secure Shell),先说什么是 Shell 呢?Shell 在 Linux 系统中指面向用户的命令接口。
SSH,就是“安全地传输 Shell 命令”,设计初衷是提供一个更加安全的Telnet服务。
SSH 提供两个方式的验证:
- 口令验证,即通俗的设置 user 和 password ,类似于 QQ 号和 QQ 密码。
- 公私钥验证。
如果是人为地登录远程登录服务器进行维护,一般用第一种方式设定用户和密码,并根据维护人员的职责调整用户的权限。我们使用 Xshell 工具时,经常以这种方式登录。
笔者在配置 Hadoop 集群时,使用了第二种方法来让节点互相认证(使用软件进行批量认证),免去了人工输入密码的校验环节,使得各个节点能保持联络畅通。
SSH 是专门为 Shell 设计的,只有 SSH 客户端和 SSH 服务器才支持使用此协议。 SSL 是一个已被广泛接受的 Web 安全协议,后来升级为更加通用的 TLS 协议。
至少 CentOS 发行版(笔者常用的版本)默认是安装 OpenSSH 的,默认端口号 22 。SSH 还可提供与 FTP 近乎相同,但安全性更高的文件传输服务,即 SFTP。
🌎想额外了解 SSH 的细节,可以了解这篇文章,下面我们继续专注于介绍 HTTPS 协议中的 TLS 验证部分。
TLSv1.2 单向验证过程
笔者在这里特意强调了单向验证:客户端会检查服务器的身份,但是服务器对来访的客户端身份不做限制。
如果服务器开启了双向验证,那么客户端需要在握手过程中顺带着将自己的证书也发送到服务器进行验证,一般用于机密性要求很高的金融服务机构等,为认证客户提供服务。在这里仅介绍单向验证过程。
总体来看,HTTPS = TCP + TLS。在 TLSv1.2 版本及之前,连接需要四次握手(无论是单向还是双向验证)。所以 HTTPS 通讯的往返时延 = 1.5 RTT( TCP 握手) + 2RTT( TLS 握手)+ 1RTT( HTTP 一次请求响应) = 4.5 RTT。
HTTPS 协议是一个时延大户。因此 TLSv1.3 协议为了尽可能减少 RTT 时延,采取了更加高效(且激进的方法)将验证过程的 RTT 时延控制到了 1 甚至是 0 。我们稍后会单独谈谈 TLSv1.3 的方案是怎么做的。
为了看懂下面的四步握手过程,是基于私钥签名,公钥验证的。
客户端向服务端发送 Client Hello 消息,花费 0.5 RTT 时延。其中包含了:
- 携带客户端支持的协议版本、加密算法、压缩算法以及客户端生成的随机数" client_random ";
服务端随后会发送一个 Server Hello 信息,花费 0.5 RTT 时延。其中包含了:
- 特定的协议版本、加密方法、会话 ID ;
Certificate,即服务端的证书链,其中包含证书支持的域名、发行方和有效期等信息;Server Key Exchange,消息内容对于不同的协商算法套件都会存在差异。在基于RSA的密钥交换过程中,**服务端生成的随机数 “server_random” **需要在这里发送。在某些场景中,服务器不需要发送这个字段。Certificate Request,验证客户端的证书(如果是双向验证);Server Hello Done,通知服务端已经发送了全部的相关信息;
客户端(浏览器)如果验证了 CA 机构颁发的服务器证书为可靠的,则发送 Change Cipher Spec 消息,示意服务器使用密钥通信,花费了 0.5 RTT 时延。其中包含了:
Client Key Exchange,包含使用服务端公钥加密后的随机字符串——预主密钥Pre Master Secret;Finished,其中包含加密后的握手信息;
服务端向客户端发送 Change Cipher Spec 消息,通知客户端后面的数据段会使用密钥加密传输,花费了0.5 RTT 时延,其中包含了:
Finished,验证客户端的 Finished 消息并完成 TLS 握手;
三个重要随机数
上述的过程中提到了三个随机数:
- client_random:在 Client Hello 消息中出现的,由客户端生成的随机数。
- server_random:在 Server Hello 消息中出现的,由服务器生成的随机数。
- Pre Master Secret:客户端在第三次握手中发送的随机数。
下面是基于 RSA 方式的密钥协商过程:
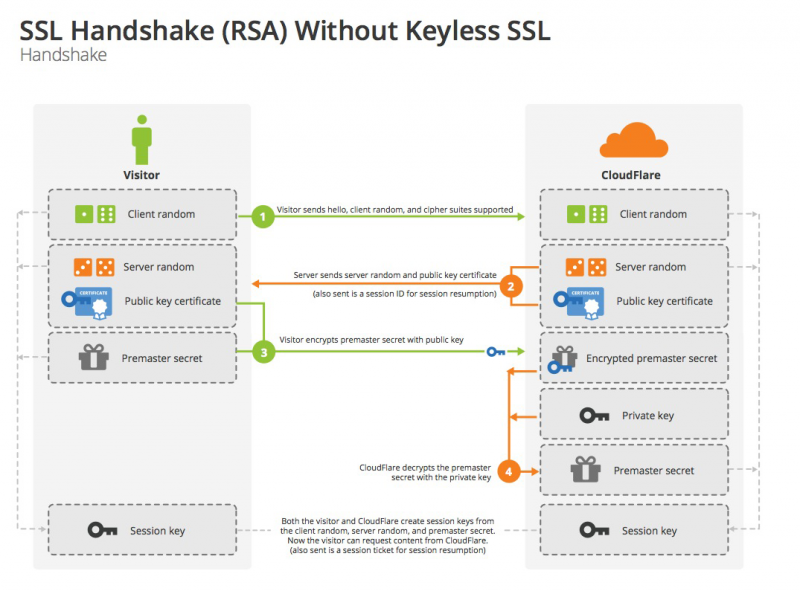
在前两次握手当中,双方通过 Hello 消息互相交换了各自生成的随机数。第三次握手当中,客户端又生成了第二个随机数,称之为 Pre Master Secret ,用服务器端的公钥加密并发送。
为什么需要 Pre Master Secret 呢?因为在 TLSv1.2 协议及之前,握手过程是不进行加密的,中间人可能会同时截获 Client random 和 Server random 导致密钥泄露。客户端需要再生成 Pre Master Key 并用公钥加密发送,一方面是为了安全的生成一个密钥,令一方面也能检验对方是否持有对应的私钥。
这样,双方最后都将具备相同的 Client random , Server random , Pre Master Secret 。双方通过事先协商好的统一算法根据这三个参数算出 Session key 。由于双方持有的三个随机数一样,算法也一样,因此就保证了双方最后得到的 Session Key 也一样。
最后,这个 Session Key 就作为双方沟通的对称密钥,用于加密通讯。
这个对称密钥基于双方的随机数生成,是因为 SSL 的协议默认不信任每个主机都能产生完全随机的数,如果只使用一方生成的伪随机数来生成秘钥,就很容易被猜中。
在浏览器中判断安全连接
在以下三种情况下,此网站会被判定为不安全:
- 网站本身不支持 HTTPS 协议。用户是无法使用 HTTPS 协议对这样的网站进行访问的。
- 网站本身支持 HTTPS 协议,但是网站内部有部分链接(
src,a标签)仍然基于 HTTP 协议请求资源。 - 网站用于 HTTPS 连接的安全证书不是浏览器所认定的权威CA颁布的。
如何直观地判断一个网站是否是安全的?浏览器会对不安全的网站标注 Not secure , 不安全 等标签。对于上述的后两种情况,即使在浏览器中人为敲上 https:// 访问,也会被警告为不安全。
检查某个网站时,可以 F12 打开调试模式观察里面是否有 http协议的链接。如果有,则这个网站一定不是安全的。
直观对比 HTTP vs HTTPS
我们使用 Wireshark 软件对 HTTP 和 HTTPS 的数据包进行追踪。我们追踪一个 HTTP 报文的 TCP 流:
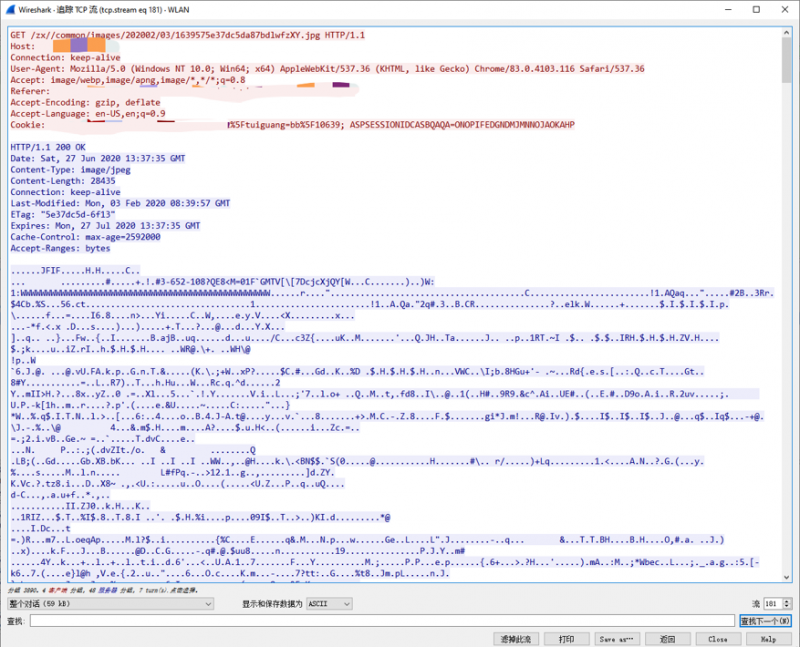
客户端是红色字体,服务器是蓝色字体。除去响应中的二进制码(Content-Type表明这个实体是个图片),我们观察到了熟悉的请求报文头,和响应报文头,完全没有问题。
现在追踪一个 TLS 加密过的 TCP 流:

内部的内容完全被扰乱了。因此在HTTPS协议中,即使我们中途截获了报文,也得不到任何有用的信息,因为只有消息的接收者才能使用密钥解开消息。
在 Spring 项目中搭建 HTTPS 服务
为了实现 HTTPS 的效果,我们首先要准备一个证书。如果有云服务器,我们可以从厂商那里申请到权威的证书。不过在这里我们仅通过 Java 的 keytool 工具生成一个模拟的自签名证书(只有权威 CA 机构有权利签发自签名证书。换句话说,我们的自签名证书不被浏览器所认可)。
keytool -genkey -alias myKey -keyalg RSA -keysize 2048 -keystore D:\myKey.p12 -validity 365其参数含义为:
| 参数 | 含义 |
|---|---|
-genkey | 生成一个新的公钥。 |
-alias | 表示这个证书的别名。 |
-keyalg | 选用的加密算法。这里选取RSA非对称加密算法。 |
-keysize | 公钥长度。 |
-keystore | 证书的存放位置,或者说输出路径。 |
-validity | 证书的有效时间,按天数计算。 |
我们需要牢记所设置密钥的口令。在执行完毕之后,把myKey.p12拷贝到Spring Boot项目中的resource文件夹下,并在application.properties中做以下配置:
# 生成的证书所在路径。server.ssl.key-store=classpath:myKey.p12
# 生成这个证书时的别名。
server.ssl.key-alias=myKey
# 生成这个证书时所设置的口令,等效于私钥。
server.ssl.key-store-password=12345678
启动服务,我们这次在浏览器中输入并访问http://localhost:8080/test/hi,将提示服务器端没有对这个请求做出及时响应,调试模式下能看到504错误。
在浏览器中输入https://localhost:8080/test/hi并访问,我们就可以得到响应了。当然,由于我们是自己生成的 HTTPS 证书,并不会被浏览器认可,因此浏览器会发出警告。在实际部署环境中,我们会将这个虚拟的证书替换成被浏览器所认可的,由权威 CA 机构所颁发的证书。
TLSv1.3 新特性
TLSv1.3 在 2018 年发布。和之前 TLSv1.2 版本相比,总体来说是更加高效且安全的,并摒弃了之前版本中存在安全漏洞的算法,包括了 CBC,RC4 等算法。
非对称密钥交换的更多选择
我们在前文提到的都是基于 RSA 方式的非对称加密交换。在 TLSv1.3 中,使用 ECC 算法代替了之前的 RSA 算法,原因如下:
256 位 ECC Key 在安全性上等同于 3072 位 RSA Key, ECC 证书文件体积比 RSA 证书要小一些。客户端可以在不牺牲安全性的条件下实现更快速的验证。
CA 机构已经在 2008 年正式储备 ECC 根证书,国内在 2015 年左右也开始逐渐接受 ECC 证书。
优化的握手策略
除了使用更优化的加密算法之外,TLSv1.3 还更改了握手策略:
在 TLSv1.3 协议中,服务器在第二次握手中除了发送证书链之外,还会对这条消息进行私钥签名,表示“我的证书不仅是合法的,而且这条消息是我亲自发送的”,以此打消客户端对中间人攻击的顾虑。
如果浏览器能够使用公钥对收到的消息验签,且验证的证书内容合法,则可在收到 Server Hello 消息后就推断服务器身份合法,因此就没有必要再用公钥加密一个 Pre Master Secret 来“试探”对方了。我们现在可以在1个 RTT 内确认对方的身份,并规避 MITM 攻击。
接下来的问题是,我们如何在1个RTT内就能安全地交换随机数,并生成密钥呢?带着这个疑问,我们引出 ECDH 密钥交换协议。
浅谈 ECDH 的原理
ECDH 基于 ECC 算法和 Diffie-Hellman 密钥交换协议。 DH 使得双方在完全缺乏对方(私有)信息的前提条件下通过不安全的信道达成一个共享的密钥,利用了离散数学难题 DLP 保证安全性。
而 ECC 算法负责利用椭圆曲线(它并非高中阶段所学的椭圆曲线方程)制造一个 DLP 难题,就像 RSA 算法制造了一个大数分解难题一样。
笔者通过一篇大牛的解释并参考了 wiki 百科,对原来的模运算进行了简化,以此简述 ECDH 的过程。给定一个式子:
Q = k * P,设 P 是已知条件,或者 P 可以对外公开。
- 给定一个 k,则很容易能算出 Q。——性质1
- 给定另一点 P,很难求出 k。——性质2 ( 它本质上是个DLP难题)。
假如 P 事先已知,则双方使用 G = a * P * b 作为交互的密钥。其中 a 和 b 是通讯双方各自生成的随机数,相当于式子里的 k。
双方怎么通过安全的方式交换随机数呢?首先基于性质1:
- 假设客户端生成的随机数为 a,则它会向服务器发送 Q1 = a * P。
- 假设服务器端生成的随机数为 b,则它向客户端发送 Q2 = b * P。
双方交换了 Q1/Q2 之后,只需用自己本地生成的随机数 b/a 进行运算就可以同时算出 G 了。类似于交换律:
(客户端)Q2 * a = (b * P)* a = (服务器端)Q1 * b = (a * P)* b = (a * P * b) = G。
根据性质2,即便他捕获了这两条信息 G1 和 G2,由于他很难推导出来内部的数 a 和 b ,因此 G 自然就无从知晓。
在这个协商的过程中,客户端和服务器其实也不知道对方的生成随机数 a,b 是什么——但它们只需要将交换得到的 Q1(Q2) 与自己生成的随机数 b(a)进行模运算,就可以获得一模一样的密钥了。这正好印证了上文所描述的 DH 协商的特性:互相都不知道对方的秘密,却生成了同一个密钥。
实际上的 ECC 和 Diffie-Hellman 协商的具体细节要比这个复杂的多。想要了解更多细节,可以阅读这篇文章。
TLSv1.3 基于 ECDH 将密钥协商过程整合在了 1 个 RTT 内。双方只需要各自发送一次 Hello 消息,一个安全的通讯建立起来了:和 TLSv1.2 的 2 RTT 相比直接降低了一半的时延。
1-RTT的建立过程
如果你已经理解了笔者在上文中想表达的意思,那么下面就很容易理解 TLSv1.3 中 1-RTT 连接建立过程。
客户端发送 Client Hello 消息,花费 0.5 RTT。该消息包括:
Key_share:DH 密钥交换参数列表 (前文提到的Q1和P)。- 客户端支持的协议版本,加密套件等。
服务端回复 Server Hello 消息,花费 0.5 RTT。该消息包括:
Key_share:选用客户端提供的参数(P)生成的 ECDH 临时公钥(相当于前文提到的Q2)Finish:表示服务器端已经准备建立连接。- 选定的加密套件,包括签名算法等;
- 服务器证书链;
- 对此次对握手消息的私钥签名。
此外,服务器端根据客户端发送的
Key_share计算出了会话的共享密钥。(相当于G)客户端接收到 Server Hello 消息后,使用证书公钥对消息进行签名验证。验证通过后用对方发送的
Key Share获取服务器端的 ECDH 临时公钥(Q2),同样生成会话所需要的共享密钥(G);双方使用生成的共享密钥对消息加密传输,保证消息安全。客户端第一次发送 HTTP 请求时,会捎带上
Finished,表示 TLSv1.3 握手建立完毕。(此时已经发送应用数据了,因此不计入 RTT 时延)
基于Pre-Shared Key实现0-RTT重建连接
Pre-Shared Key(简称 PSK ),预共享密钥。顾名思义:就是双方在上一次的连接使用的密钥,会在下一次连接中复用,并免去之前 1-RTT 握手中的验证过程。笔者目前掌握的知识和精力有限,因此只阐述宏观上的流程,不去深究其细节。
双方在第一次连接时,服务器可以随时向客户端发送共享密钥导出的 PSK 标识。
当客户端再次向这个服务器建立连接时,会带上这个 PSK 标识,与服务器协商使用这个 PSK 。另外,客户端会在 Client Hello 消息中带上early_data扩展,以附带 HTTP 请求等应用数据。正因为在第一次握手中就发送了有效数据,因此称之为0-RTT。
下面两种情况会使得 TLS 连接从 0-RTT 连接降级到 1-RTT :
- 客户端使用的 PSK 标识过期。
- 服务器不打算处理客户端提前发送的
early_data信息。
0-RTT 连接为了追求极致的性能提升,是付出了一定代价的:比如 0-RTT 握手不具备前向安全性,消息可能被重放攻击等。因此在默认情况下,服务器不会主动采用0-RTT连接的策略。
QUIC => HTTP/3
QUIC(读法: Quick ,全称为:Quick UDP Internet Connections),最初由 Google 团队开发,整体基于 UDP 协议运行,并在最上层提供一层 HTTP/2.0 的接口。经过多年的验证,这个协议被 IETF 纳入为标准协议。在许多机构和个人的合作下,IETF对原先 Google 的 QUIC 做了许多完善和改进,以至于可称之为一个全新的协议。为表示区分, Google 版本的QUIC又称之为 gQUIC。
2018年,IETF 组织正式宣布将自家的 HTTP over QUIC 协议更名为HTTP/3协议。
HTTP/3 的诞生,Google 的贡献功不可没。Google 团队已经宣布,会逐步把 IETF 的规范纳入自己的协议版本,实现相同的规范。
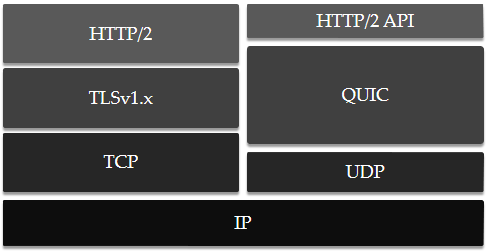
QUIC 底层通过 UDP 协议替代了 TCP,上层只需要一层用于和远程服务器交互的 HTTP/2 API。这是因为 QUIC 协议已经包含了多路复用和连接管理,HTTP/2 API 只需要完成 HTTP/2协议的解析即可。
QUIC 被设计为在 UDP 数据报的顶端进行传输,实现“插拔式”的部署。因此,浏览器将能够随时更新更加高效的协议,并投入到应用中,而不必等待操作系统层次的更新(这个代价往往是比较大的)。
当 QUIC 在实验室进行测试的时候,TLSv1.3 协议还未诞生,因此 QUIC 的安全性由自己来实现。 QUIC 协议的作者曾明确表示:未来的 QUIC 协议将由 TLSv1.3 协议提供安全性保障。
下面是 QUIC 协议的几大特性:
- 0-RTT 建立连接
- 多路复用
- 前向纠错
- 连接迁移
除此之外,QUIC 协议还对做了许多改进,比如在 TCP 的拥塞控制的基础上进行了优化,以及用严格递增的包序列号消除了前文提到了重传歧义问题,并用一个新的 Offset 变量来保证内部数据的有序性等等。
在 0~1 个 RTT 内快速建立连接
我们在之前介绍协议的时候都有意地提到了各个协议的时延 RTT 。如果再考虑到 DNS 解析所需要的时间,则还需要1个 RTT 的时延:
- TCP = 1.5 RTT(也有人认为它是 1 个 RTT )
- HTTP = 1.5 RTT + 1 RTT = 2.5 RTT
- HTTPS = HTTP + TLSv1.2 = 2.5RTT + 2 RTT = 4.5 RTT
- TLSv1.3 + TCP = 0 + 1.5 RTT = 1.5 RTT(0-RTT 连接情况)
在 QUIC 中,仅需要 1 个 RTT 就可以实现与一个新服务器的连接,原因就是 QUIC 协议通过 Diffie-Hellman 算法交换密钥,这个过程和 TLSv1.3 的 key_share 交换有着异曲同工之妙。 DH 算法的思路之前我们介绍过,这里不再展开叙述。另外, QUIC 天生就节省了 TCP 的 1.5 RTT 时延的开支,因为它基于 UDP 协议。
在第一次连接时,服务器端会给客户端发送 Server Reject 消息(类似于TLS的 Server Hello),内部的server config记录了与服务器有关的信息。在下一次连接时,客户端直接根据server config计算出与服务器的密钥信息。因此在理论上,客户端与服务器端的后续连接没有 RTT 时延,客户端可以直接发送数据,且功能上等效于TLS + TCP。
连接迁移
一个TCP连接通过四元组来唯一标识:源IP地址、目的IP地址、源端口、目的端口。
当这四元组的任何一个发生变化时,都将认为是一个崭新的连接。而源端口,源IP地址一般都不会变,比如www.baidu.com:443。
客户端经常会因为网络环境的变化而导致源 IP 地址和源端口发生一些变化。比如我们的手机在 WIFI 和 4G 之间切换时,源 IP 地址一定会发生变化,因为我们的网关从原先的路由器切换到了手机基站。
再或者,大家公用 NAT 出口时,由于连接竞争需要重新绑定源端口。而无论是四元组的哪一个发生了变化,都需要重建 TCP 连接。
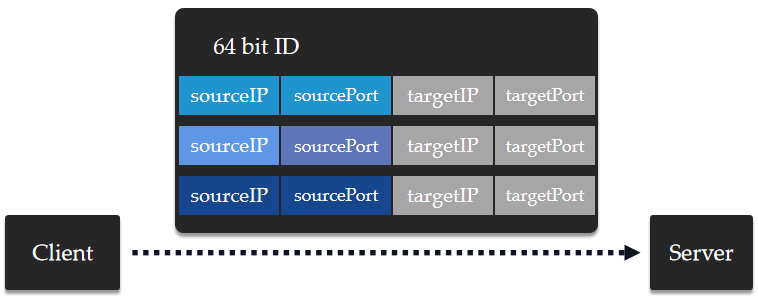
QUIC 对一个连接做了一个更高级别的抽象:任何一个 QUIC 不会再依赖一个四元组进行判断,而是以一个64位的 ID 号来描述一个连接。这样即使是客户端的 IP 或者端口发生了变化,但是只要这个 ID 号不变,则这个连接仍然不会被中断。
同时,64位的 ID 号保证了其发生冲突的可能性微乎其微。而这一切对于上层的业务逻辑来说,这个连接迁移的过程是透明的。
队头阻塞 Again
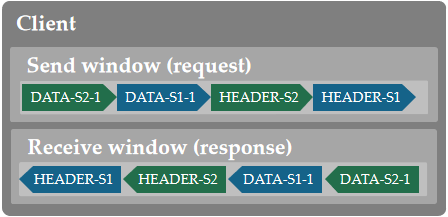
QUIC 中的改进版多路复用对这个顽疾做了更加彻底的处理。在 HTTP/2.0 协议中,无论在一个 Connection 中创建了几个 Stream ,由于它们共用一个TCP的发送/接收窗口,因此它们之间的关系可以简单描述为:
而在 QUIC 中,每个 Stream 拥有自己独立的收发窗口,一个 Connection 的收发窗口大小是这几个 Stream 的收发窗口大小之和:
虽然乍一看好像只是将等号两边进行了互换,但是意义是完全不同的:在 HTTP/2.0 协议中,即使是其中一个Stream 发生了阻塞现象,也会影响到剩下的 N-1 个流。而在 QUIC 中,其中一个 Stream 发生阻塞时,不会影响其它的 N-1 个流,因为每个流有自己独立的窗口大小。
另外在 QUIC 协议中,在一个 Stream 内,滑动窗口的移动取决于接受到的最大字节偏移量,不管中间是否缺失了部分字节序列。这和 TCP 协议是不同的: TCP 的接收窗口必须要等到前面的字节序列完全有序之后才会向后移动,这也是 TCP 容易发生阻塞的一个原因。
前向纠错与重传
QUIC 协议对待丢包的态度是:如果能主动恢复,就不需要重传。如果能快重传,那就不等到超时重传。 QUIC 使用前向纠错码(Forward-Error Correction,简称 FEC )来减少包丢失的现象。
每 N 个包计为一组 butch,则每发送一组 butch 的数据,就会额外附带上 1 个 FEC 包。分组中丢失其中任意一个包丢失,都可用剩下的 N - 1 个包来恢复。
对于重要的数据包,比如初始密钥协商的数据包,对于 QUIC 连接至关重要,因为如果无法建立连接,则整个数据流都会被阻塞。对这类数据包, QUIC 在确认丢失之前就会不断地尝试重传,这样在网络中有多个相同的包同时进行传输,只要有一个到达对方,则这个连接就会建立成功。
QUIC 面临的挑战
另起炉灶的代价是很大的。尽管 QUIC 向着拥抱 UDP 迈出了勇敢的一步,并且事实证明, QUIC 的确是一个更高效的连接方式,但是带来的问题也同样不少,首当其冲的就是使用UDP协议本身带来的问题,以及对目前网络设备的兼容问题等等:
- 目前绝大多数的网络设备对 TCP 和 UDP 的策略都是固定的,目前可能只有少数端口(比如 DNS 服务的53端口)允许通过 UDP 数据。防火墙不会轻易允许443端口(QUIC 使用的协议端口)放行 UDP 数据。
- UDP 包过多的话可能会被服务器误以为是**dos (全称:Denial of Service,拒绝服务) **攻击。
- 在经典的 HTTP 技术栈中,每一层都有响应的调试工具,比如 IP 层有 ping 和 traceroute ,传输层有 telnet ,应用层有 curl 等等。而 QUIC 带来了巨大的变更,如果没有相应的调试和支持的工具,则 QUIC 的推行会受到阻碍。
- QUIC 保留了 HTTP/2 协议中的服务器推送功能,并做了一点妥协:客户端要先同意推送,服务器端才允许有相应动作。可即便如此,目前对”如何能妥善利用推送功能“似乎仍然没有一个明确的答案。
因此客观地说,QUIC 的普及,路漫漫而其修远兮。
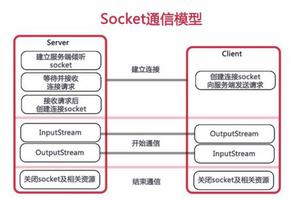
Socket
首先我们需要明确一点: Socket 不是一门编程语言,也不是一个协议,而是用于进程间相互通讯的编程接口 API 。可以将它理解成是对 TCP/IP 协议的封装,使得程序开发人员可以利用 Socket 提供的函数轻松实现 TCP/UDP 编程,而不用为协议本身的内容而操心。

Socket 的英译为“插座”,官方名叫:“套接字”。在很早以前,处在两地的两个人想要联络,必须要依赖电话,这个电话提供了拨号,接听,挂断等逻辑功能,这部电话就相当于是 Socket 。另外,想要联系对方,则必须要知道对方的区号和电话号才行。
所有主机和主机间的端到端沟通的实现,或者说所有依赖 TCP/UDP 通讯的上层网络协议,都是由 Socket 在背后默默提供支持。像一些聊天室软件应用也都是基于 Socket 来实现的。
对于主机来说,它们用什么作为互相联络的“电话号”呢?答案是 IP 地址 + Port 端口号。在正式介绍 Socket 之前,我们需要对端口有一个基本的认识。
端口
端口是 Socket 编程中一个基本且重要的概念,即便你不属于后端开发人员,也应当对端口有一个基本的认识。我们目前所说的端口特指TCP/IP协议的逻辑端口。逻辑端口分为三类:
- 0 - 1023 是周知端口。比如:端口 22 用于 SSH 远程登录协议,或是SFTP服务;端口20,21用于 FTP 传输服务等。这些都是通用的服务,因此不允许其它进程来占用。
- 1024 - 49151 是注册端口。这些允许用户程序来使用,比如 Tomcat 服务器的默认端口是 8080 ; MySQL 服务器的默认端口为 3306 。
- 49152 - 65535 是动态端口,用于在需要时随机分配一个用于网络通讯的端口。
一台主机可以通过暴露自己的 IP 地址(或域名)对外提供多种服务,而外部正是通过端口号来区分不同的服务进程。对于通用的服务,我们往往在固定端口的范围内做约定。
比如,你要想基于 HTTPS 协议访问页面,那么你应该选择访问对方的 443 端口,而非 80 端口。而作为服务器的开发者,也应当遵守这个约定,不应该随意地令 Web 服务器监听 81 端口,以免用户无法正常请求服务。
切记,在我们访问别人的端口号时,我们自己也需要打开动态端口去连接。这个道理也很简单:你想要进别人家的门,首先要打开自己家的门才能走出去。
端口,连接,进程与应用
先理解这些问题,我们等会才能更高效地理解后续 Socket 的工作机理。
Q1:一个端口可以建立几个连接?
从实践经验来看可知:一个端口可以建立很多个连接。比如说同一时间内可以有成千上万个客户同时向服务器的 8080, 443 或是 80 端口的 Web 服务建立请求,在 HTTP/1.1 中一个客户端甚至可以同时发起 6 个连接。当然,客户端需要开启 6 个端口。对于服务器端而言,它将要考虑如何并发地处理这些请求。
一个主机最多同时只能建立 65535 个连接的认识是错误的。只要发起连接的客户端 IP 或者端口不同,则它就是一个全新的连接。
Q2:一个端口可以被几个进程监听?(惊群效应)*
一个端口只能被一个独立进程监听,因为我们已经对端口占用问题见怪不怪了。
然而,一个进程可以先 bind 一个端口号,然后该父进程再 fork 出多个子进程,这样,父进程,及其下面的子进程都会 accept 一个相同的端口号。但是这诱发了惊群效应:当父进程获取一个资源时,所有的子进程全部被唤醒(多线程也会引发这个问题)。
笔者在 Nginx 的介绍当中曾说过: Worker 之间通过竞争的方式获取一个新的连接。这种方式同样会引发惊群效应:它导致系统在一瞬间占用大量的系统资源,可最后只有一个 Worker 竞争成功。
Nginx 对此给出的策略是:提供一个 accept_mutex 锁,保证同一个时刻只有一个 Worker 监听着端口。这样当外部有一个新的连接时,只会有一个 Worker 来处理。它是一个可控选项,并默认这个锁是开着的。我们可以手动移除这个锁。
先启动的进程提前声明了对端口的占有,后启动的进程不能占用之前进程使用的端口。
Q3:一个进程可以监听几个端口?
一般情况下是一个进程监听一个端口:比如 Tomcat 为部署在其下的多个 servlet 分配线程池,但是对外仅提供一个 8080 端口。
我们也有一些手段实现一个进程监听多个端口:比如通过创建多线程的方式在一个进程内创建多个源端口号不同的 Socket 。
一个进程确实可以监听多个端口,但不能监听已被占用的端口。另外,只有需要网络通讯的进程会使用端口,换句话说进程也可以选择不监听端口。
Q4:一个应用程序可以有几个进程?
一个应用程序可以有多个进程。拿 IntelliJ IDEA 来说,我们每 run 一个 Java 主程序,IDEA 都会主动替我们打开一或多个进程来保证程序的运行。因此,一个应用程序有可能打开多个端口,或者不打开端口。
Socket 三元组与五元组
TCP协议使用一个四元组标识一个唯一的连接,即:[源地址,源端口号,目的地址,目的端口号] 。 Socket 在此基础之上又添加了一个:[ 协议 ]。通常情况下,这个协议有两个选择: TCP 或者是 UDP 。
这样一个五元组,称之为是一个相关( association )。另外,还有一个概念是三元组,即 [本机地址,本地端口号,协议] 。显然,这个三元组是五元组的一半部分,故又称半相关。在网络中,可以通过三元组唯一确定一个运行在指定主机上的指定进程。
我们平时所说的生成一个 Socket ,实际上就是相当于生成一个对五元组的描述。
通信双方都需要创建一个 Socket 用于读写对方的消息,双方 Socket 所选择协议必须是统一的,不可能一方使用 TCP 协议, 而另一方使用 UDP 协议。
Windows 下的用户可以通过netstat -an查看本机所有正在运作的端口状态。
有了 Socket 编程为什么还需要 HTTP 协议呢?
Socket 和 HTTP 都能用于网络上的通信。那为什么我们还需要上层的 HTTP 协议呢?
Socket 一般用于即时通讯,或者消息推送的情况,比如说 QQ ,微信这类软件不可能等着客户主动发起请求的时候才去刷新消息。另外,通过 Socket 建立的连接是长连接,对于手机来讲,手机网络状况比较复杂,需要频繁的重传,长连接一方面会占用内存,一方面会加速电量消耗。笔者通过检查手机电池使用量发现:基本都是 QQ,微信等即时通讯软件耗电量占比最多。
HTTP 用于实时性要求不高的情形,比如说资讯网站等允许有分钟级别的延迟,讲究”即用即看,看完就走“。它本身就被设计为是短连接的——短到真正传输数据的时间可能远远不及三次握手四次挥手的时间。
因此从业务角度分析, Socket 一般用在“更对等的全双工通信”,如聊天室应用中,通讯双方的身份是“对等”的。而 HTTP 协议中,客户端和服务端更倾向于“一问一答”关系。
我们在前文讨论 HTTP 的时候完全没有感觉到 Socket 的存在,Socket 到底运行在哪里呢?
Socket的运行层次
Socket 运行在应用层和运输层之间。Socket 的工作职责其实可以延申到 23 个设计模式中的其一——外观模式/门面模式。
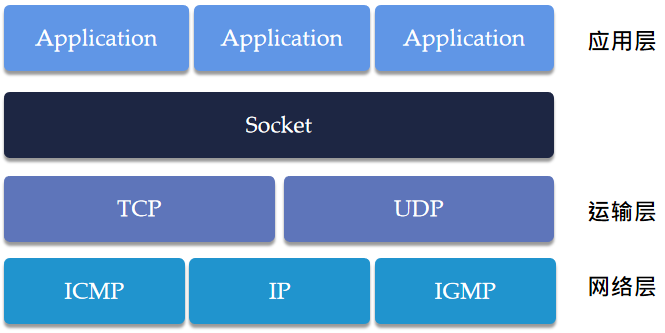
对于应用程序员,他们不必再去了解 TCP / UDP 所有的细节。Socket 为程序员提供了一些现成的逻辑:建立 Socket ,监听端口,接受连接,发送消息,断开资源......而想要实现这些功能,程序员只需根据他选择的网络协议提供对应参数即可——剩下的一切都交付给 Socket 。
从逻辑上, Socket 将复杂的 TCP/UDP 连接具象化成了一个个函数,程序员可以轻松地在上层设计基于网络协议的通讯应用。
Socket 工作流程(TCP)
下面从 Socket 的层次去介绍客户端和服务器端建立起连接沟通的流程,以及用到的函数原型。这里只介绍和 TCP 协议相关的部分。
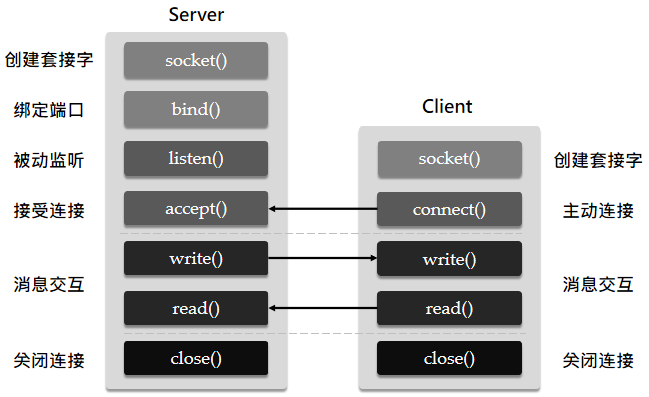
Socket 的设计理念源自于 Unix:一切都是文件,包括网络连接。在 Unix/Linux 环境下,我们使用 socket() 函数打开一个网络连接时,该函数返回的是一个文件描述符(File Descriptor)。
我们对这个“网络文件” 的读 read() 和写 write() 其实就是被抽象了的消息接收和发送的过程。在 Unix/Linux 环境下,Socket 网络编程可以看作对文件的 I/O 操作。(当然,Socket 本身并不是文件,只是 Unix 提供了看待问题的统一视角。)
在 Windows 系统中,Socket 会被当做单纯的网络连接来对待,而不是文件。因此消息接收和发送被替换为了recv()和send(),但是功能上来看是一样的。
创建三元组
无论是服务器还是客户端都需要使用 socket() 方法创建套接字。函数原型如下:
intsocket(int af, int type, int protocol)参数 af ,全称为 Address Family,即地址族。我们通用的就是 Internet 地址族的 IPv4 和 IPv6。使用 AF_INET表示 IPv4 ,使用 AF_INET6表示 IPv6 地址。
参数 type , 表示此 Socket 采用的数据传输方式,其中最具有代表性的是 SOCK_STREAM (面向流方式,基于TCP)和 SOCK_DGRAM (面向数据报方式,基于UDP),这两种方式都秉承了 TCP 和 UDP 各自的特点。
参数 protocol,表示此 Socket 采用的网络协议。通常情况下,我们填写 type 参数的时候就已经表述了潜在的协议类型,比如 SOCK_STREAM 对应的是 TCP 协议。如果试图使用不兼容的组合创建 Socket,则 Socket 将引发 Socket Exception。因此,我们在更多的时候会选择赋 protocol = 0 ,表示忽略它。
socket() 函数会返回一个 int 值,它是笔者刚才提到的 Socket 描述符,下文称 Socketfd,用于描述一个 Socket 连接。
两类套接字
对于服务器,通过 socket() 函数创建的 Socket 是用于监听和接受客户端请求的,又称之为监听套接字。它在服务器进程的生命周期内会持续存在,且只会有一个,需要主动调用bind()函数绑定一个固定端口号,以便外界能够访问。
另外一点需要注意。在bind()之后,该服务进程就已经相当于向系统声明了对该端口的占有。其它独立的服务进程将不能够再将它的套接字绑定到这个被占用的端口上。(承接问题Q2)
intbind(int sock, struct sockaddr *addr, socklen_t addrlen)其中 sockaddr 是一个复合的结构体,要求描述选定地址族 af 的地址号和端口号。 socklen_t 是addr内容的长度,通常由sizeof来计算。
对于客户端,通过 socket() 函数创建的 Socket 用来与对方进行消息传输,又称为连接套接字。它不需要使用bind()函数提前绑定自己的端口号,只需要connect() 函数向服务器端的监听套接字发起连接,客户端的系统会随机选取一个空闲的随机端口分配给它。
intconnect(int sock, struct sockaddr *serv_addr, socklen_t addrlen);这里的sock是客户端生成的 Socket 文件描述符号,而serv_addr是服务器端的地址族,地址号和端口信息。
为什么要区分这两类套接字?监听套接字唯一的任务就是“耳听八方”。它在 listen 到请求之前并不知道对方的身份,也没有与任何客户端建立实质性连接。而连接套接字,我们能用五元组来形容唯一一个端对端的连接。
服务器进程监听请求并接受
服务进程在调用socket()和bind()函数创建一个绑定端口的监听套接字之后,需调用listen()函数进入监听状态。
intlisten(int sock, int backlog)在高并发访问情况下,导致服务进程不能立刻调用accept()接受外来请求时,服务进程只能暂时将后续的请求搁置到套接字队列当中。
backlog参数用于设定队列大小,而该值的设置取决于业务量和服务器性能。也可以设置为SOMAXCONN,让系统来决定缓冲区的大小。
在服务进程调用 listen() 进入监听状态之后,我们可以调用 accept() 函数接收外部的连接请求:
intaccept(int sock, struct sockaddr *addr, socklen_t *addrlen);其中,参数sock是描述服务器端的监听套接字描述符,而参数addr的结构体用来描述客户端的协议,IP 地址,端口号等信息。服务器很少会主动对客户端的地址和端口号设限制,后两项一般为 NULL 。accept()函数会返回一个新的连接套接字专门与这个客户端进行消息传输。
可以简单理解为:服务器将 1 个监听套接字作为服务入口的门面。每连入一个新的连接,则新创建一个连接套接字专门用于与该客户端消息交互。一个端口可以流通很多个套接字。
这些套接字"复用"服务器进程先前通过bind()函数绑定的端口,服务器进程通过套接字五元组来区分不同客户端(因为客户端的 IP 和端口必定是不一样的)。
等等,连接套接字和监听套接字的工作方式不是有点像 Nginx 的 “ Master 和 Worker ” 的套路吗?读者们眉头一皱,想起笔者刚才在端口章节提到过的惊群效应。在早期,accept()函数确实会引发这个问题。不过 Linux 2.6 版本的内核进行了针对性优化,解决了该函数引发的惊群效应。知乎的一篇帖子详细的介绍了 Linux 对 accept 惊群效应的解决方案。
📣如果等待队列内已经没有需要处理的连接,accept()会使执行它的线程陷入阻塞状态。
服务器与客户端进行数据数据
Linux 在明面上不区分套接字和一般文件,因此我们可以通过read()和write()直接"从套接字中读写数据",表示数据的接收和发送(形式上是这样)。
其write()和read()的原型为:
ssize_t write(int fd, constvoid *buf, size_t nbytes); //向 socketfd 写入消息,即代表发送。ssize_t read(int fd, void *buf, size_t nbytes); //向 socketfd 发送消息,即代表接收。
其中,fd为本地与对端进行连接的 Socketfd,buf为收发消息的数据缓冲区地址,nbytes为消息的字节数。其返回值为成功发送/接收的字节数,否则返回-1。
每建立一个 Socket ,主机就会在内存的用户空间内为其分配两个缓冲区分别用于接收消息和发送消息。尤其是对于write()而言,只要数据被写入缓冲区,那么函数就会直接成功返回,因为消息的可靠传输将由底层的 TCP 协议负责,而 Socket 并不会干预这个过程。
TCP 协议独立于write()/read()函数,数据可能刚写入缓存区就被发送,也有可能在缓存区积压到一定程度之后才发送,同时还需要考虑到网络状况等,因此 TCP 协议的数据收发不受程序员的控制。
其它功能相同的send()/recv()函数原理和write()与read()类似。
探讨服务器如何处理并发 Socket
假如某一时刻有 10k 个用户端通过connect()方法发起连接,则服务器端将有 10k 个连接套接字处于并发状态。为了理解服务器的并发操作,我们必须再深入到操作系统的层次中寻找原因。在此之前,我们首先需要有以下基本的认识:
首先是 CPU 和 I/O 设备的分工:
- CPU 主要是用来计算,执行指令的。在早期,CPU 还需要兼顾 I/O 操作。人们希望将 CPU 与 I/O 操作尽可能分离,于是后来发展了各种 I/O 控制方式(详见后续的 DMA )。
- 需要大量 CPU 计算的任务称 CPU 密集型任务,需要大量 I/O 操作的又称 I/O 密集型任务。高并发 Web 应用属于后者。
- CPU 只对内存的数据和指令进行读,写。而大部分数据保存在外存(指磁盘等介质),需要时由 I/O 操作将这些数据从外存调进内存。
进程与线程的关系:
- 在进程的层面看,CPU 的调度由操作系统通过调度算法来完成。进程是资源分配的最小单位。
- 在一个时间片内,一个 CPU 只会被一个进程所占用。线程是 CPU 执行任务的最小单位。
- 在一个时刻,一个 CPU 只能处理一个线程。如果进程内部开启了多线程,则需要进程自己调度 CPU 应如何分配。
- 在以下几个状态当中,进程仅在 Running 状态持有 CPU 使用权。
- 进程不会直接从 Waiting (等待,或称阻塞)状态转入 Running 状态。在进程需要的 I/O 操作执行完毕时,会转入 Ready(就绪)状态,等待操作系统下一次重新将 CPU 分配给该进程。
- CPU 数量 ≥ 线程数,则这些线程处于并行(Parallel)状态,否则多线程就需要竞争 CPU ,这是通常的境况,也就是我们常说的**并发(Concurrency)**状态。
下面是进程的几种状态:
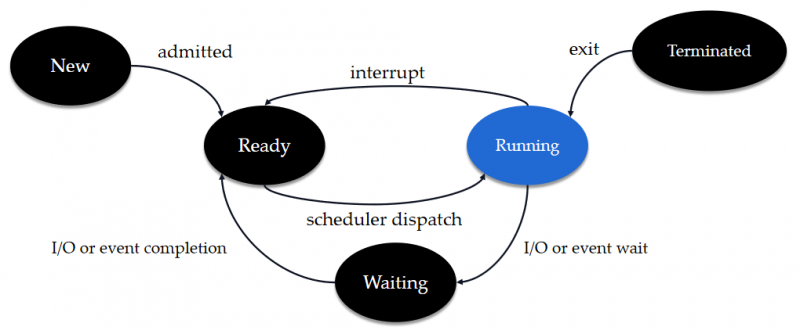
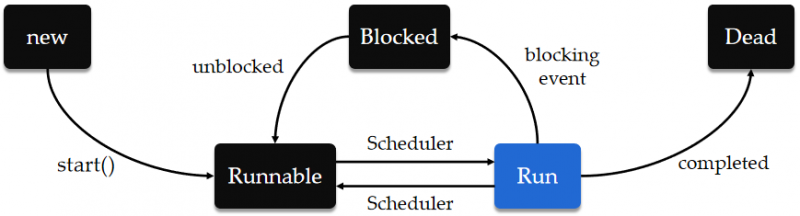
在进程处于 Running 期间,其内部的多线程又处于以下状态,只有处于 Run 状态的线程才真正获取了 CPU。
内核态与用户态
内核态与用户态形容了 CPU 的两种执行级别。
- 内核态:CPU 可以访问内存所有数据,包括访问外围设备,例如磁盘,网卡等,允许执行特权指令。
- 用户态:CPU 只能访问有限的内存,不允许访问外围设备,只能执行非特权指令。
为什么要划分用户态和内核态?诸如进程调度,I/O 操作,内存分配,乃至关闭计算机电源等核心功能,操作系统并不希望用户进程能够直接调用这些它们,而是将这些指令保管于内核空间中,用户进程无权直接访问,只有系统内核有权限进行操作。这种严格的权限控制提高了系统安全性和稳定性。
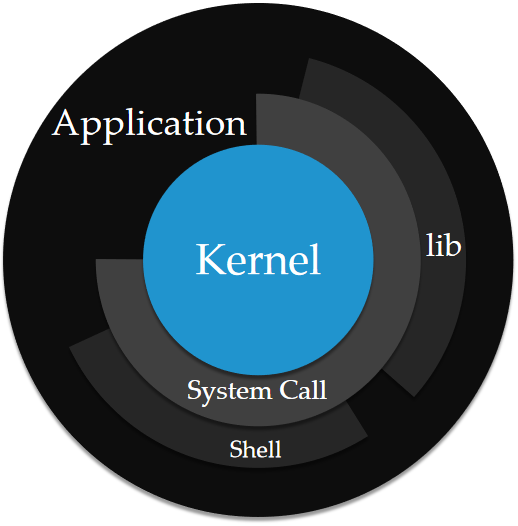
应用进程在执行状态时,CPU 大部分都处于用户态当中。但是当用户进程涉及到“特权”操作时,则需要进行系统调用( System call )将 CPU 使用权暂时交给系统内核,系统内核将指派一个内核线程来对应处理。CPU 寄存器会暂时保存原用户态的指令位置,随后 CPU 切换为内核态,更新到内核态(特权)指令的新位置运行内核任务。系统调用结束之后, CPU 寄存器恢复到原来的上下文,用户进程重获 CPU,CPU 重新处于用户态。
内核态到用户态的切换是靠 CPU 来实现的。频繁地切换会降低 CPU 任务执行效率。
系统调用的两种情况
系统调用实际上分为快系统调用和慢系统调用。
快系统调用指:一些系统调用可以即刻间返回,或者只需要微观的时间。如果只是读取系统状态的一些调用(比如查看进程号),或者对系统状态进行修改(kill 某个进程),这些都属于快系统调用,或者说不会引发阻塞。
慢系统调用指:有些系统调用取决于外部事件的发生,并在得到外部事件的结果之前都要处于阻塞状态。比如说读取来自管道,终端和网络设备的数据,数据有可能并不存在,因为对方还没有发消息。或者说主动调用了pause()和wait()函数,让进程陷入暂停或者等待状态。
从底层看待 Socket 数据的传输过程
操作系统从内存中为内核操作划分出了一小部分空间,这块内存称之为内核空间。内核空间的内容是受保护的,只有 CPU 处于内核态时才能访问它们。在 Socket 通信时,消息收发都是在暂存在用户空间中。因此消息需要经历从内核空间到用户空间的拷贝,这涉及到了系统调用。
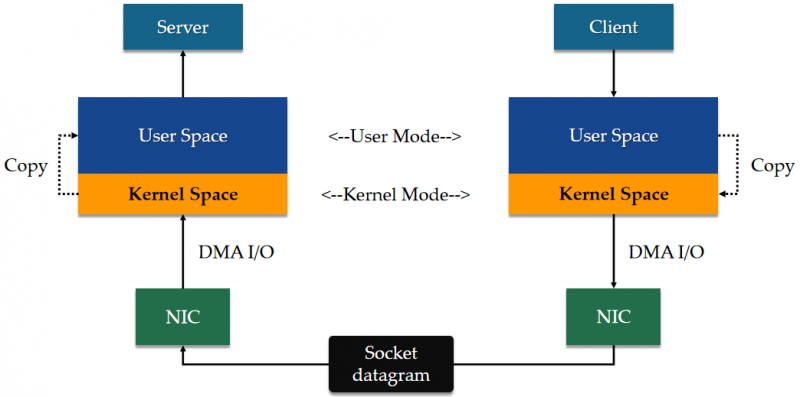
如上图所示。当发送数据时,服务端用户程序切换到内核态,通过系统调用将消息从用户空间拷贝到内核空间,再将消息通过网卡口发送到对方。
数据到达对方的网卡口之后,其驱动程序将消息写入到内存的内核空间中,随后向它的 CPU 发出中断请求,表示有新数据到达。当对方的客户端进程要读取数据时,通过系统调用将数据从内核空间拷贝到用户空间。
数据在用户空间和内核空间的拷贝是纯粹的值拷贝。
内核线程与用户线程
一个进程内的线程会不会阻塞呢?如果会阻塞,线程阻塞会对进程有什么影响呢?
从线程的角度,我们可以划分出用户线程和内核线程。
用户线程位于内核之上,每个用户进程自行管理用户线程。而内核线程由操作系统直接管理。用户线程和内核线程之间存在着三种模型:多对一模型,一对一模型,一对多模型。
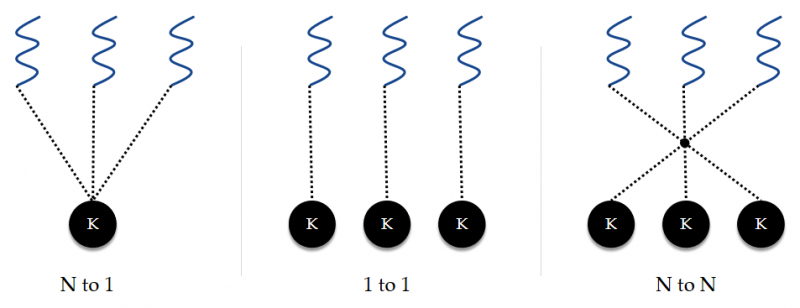
在多对一模型中,仅有一个内核线程与用户线程相关联(不管该线程属于哪个进程)。如果有一个线程调用了阻塞的系统调用,则会进而导致整个进程被阻塞。在多个线程都发起系统调用的情况,由于只有一个内核线程可用,因此用户多线程并没有提高并发性。现在几乎没有操作系统再沿用此模型了。
而一对一模型能够提供更好的并发性能,唯一的缺点是:创建与用户线程等量的内核线程,开销太大。因此操作系统大多都会主动限制线程数量。Linux 和 Windows 操作系统均实现了一对一模型。
多对多模型通过复用内核线程改进了一对一模型中的线程“浪费”现象,节省了资源开销。
综上所述,线程阻塞是否会引起进程阻塞,取决于系统采用的是何种线程模型。另外,如果是单进程且单线程的的服务,那线程阻塞必定导致进程阻塞。
DMA
I/O 控制有很多控制方式,这里笔者介绍通常情况下的 DMA 控制方式,因为它是微型机(即我们使用的笔记本)常用的 I/O 控制方式;大型计算机一般使用 I/O 通道模式。
在早前, I/O 操作需首先向 CPU 发送中断信号,CPU 会设立中断点,暂停正在运行的线程转而去处理 I/O 操作,处理完毕后再返回到刚才被暂停的工作。这种方式仅适用于突发,少量的输入(比如键盘输入),需要频繁断点和现场的保护和恢复。
在传输大量数据时,CPU 会被迫花费较长的时间去处理 I/O 操作,而导致原线程的处理效率变低。因此人们希望尽可能将 I/O 操作和 CPU 独立开来,DMA (Direct Memory Access,直接存储器访问) 就是其中一种方式。
在 DMA 控制方式中,内存, CPU , DMA 控制器都接在控制总线上,因而 DMA 设备可以在不需要 CPU 介入的情况下直接与内存进行交互。当需要执行 I/O 操作时,CPU 仅负责做一些简单的预处理,**随后 DMA控制器短暂从 CPU 那里获得总线控制权,并负责实际的数据运输,**并在执行完毕后向 CPU 发送中断请求。 CPU 此时会再执行中断服务程序做一些结束处理:包括检验传输到内存的数据是否正确,传输过程中是否出错,是否要 DMA 处理其它数据块等。
因此,在 DMA 控制方式中,大部分时间 CPU 和读写设备的工作是分离的。这样的好处是:即便一个线程因等待 I/O 结果而被阻塞,但是 CPU 仍然可以被调度给其它就绪的线程所使用。
我们最关心的阻塞发生在何时?
我们经常谈及的阻塞情况,往往是:服务器端线程需要根据客户端发送的数据才能执行操作(比如根据用户发来的字段查数据库表),但对面迟迟没有发送数据。
线程因长时间“读不出来”,或者是“写不出去”,可它又必须要同步地等待执行完这步操作,或者依赖这一步的返回结果,才能继续向下执行逻辑,由此才引发了阻塞问题。
在同步操作中,线程阻塞与否,取决于它发起系统调用之后是否立刻返回:
- 阻塞:线程发起系统调用之后就一直等待 DMA 处理完消息返回结果,线程被挂起,失去 CPU 使用权。
- 非阻塞:线程发起系统调用之后立刻返回,继续使用 CPU 处理其它任务,但是每隔一段时间线程主动通过系统调用进行一次问询 。
基于阻塞和非阻塞,在此引申出服务器并发处理的几个同步处理模型:阻塞 I/O 模型,非阻塞 I/O 模型, I/O 多路复用。
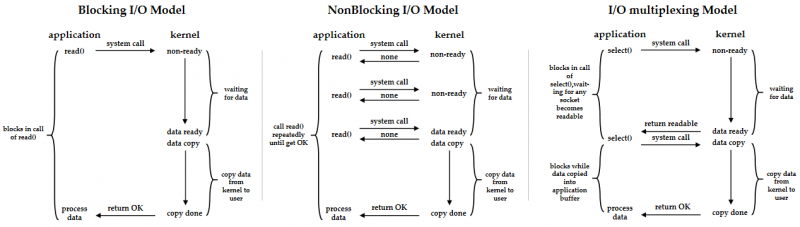
单线程阻塞模型
在探讨三个同步模型之前,我们不妨先从最简单的模型开始:仅有一个主线程来处理请求。这意味着在同一个时段内服务进程只能接受并处理一个连接。处理完上一个连接,服务器才重新等待接受下一个连接。
服务器处理请求的伪代码如下:
while(1){accept(); //接受请求,建立 TCP 连接。没有新连接时,程序会阻塞在此处。
read(); //接受用户的请求内容。
queryData(); //数据库查询。
write(); //发送信息。
}
显然这种流水线处理方式,线程阻塞无法避免。如果该主线程仍滞留在上一个客户的请求响应,则新发起的连接请求会因服务线程无法及时调用accept()函数处理而导致连接失败。
多线程 or 多进程?
只要并发量提高一点点,单线程就难以应付了。我们就想到这样的一个优化方法:每当 accept()获取到一个 Socketfd 之后,就创建一个新的线程或者子进程处理连接。下面是多线程/多进程处理的伪代码:
while(1){skfd = accept();
new Thread(exec(skfd));
# or create a new Process to tackle this new socketfd:
# new Process(exec(skfd));
}
------------------------------
exec(fd) {
read();
queryData();
write();
}
我们有两种选择:
- 如果我们选择多进程,就需要
fork()出一个子进程来处理新的连接。 - 如果我们选择多线程,就需要
new创建一个Thread来处理它。
那么应该选择多进程还是多线程呢?创建一个子进程消耗的系统资源较大,但是各个进程之间资源独立,维护的程本要更低一些。
而一个进程内的所有线程共享相同的全局内存、全局变量等信息。开启一个线程虽然开销比进程小得多,但是相比多进程并发而言,有需要程序员考虑额外的问题:
- 临界资源的访问控制,锁机制的引入不仅加大了程序复杂度,还容易影响性能,甚至发生死锁。
- 另外,如果有一个线程发生了崩溃现象(本质上是内存出错),而其它线程访问了这个错误的内存地址,则会导致其它线程受到影响而一同崩溃,最后的结果就是整个服务进程崩溃。
多线程与多进程的详细区别可以参考这篇文章。至于选择哪一个,仁者见仁智者见智。我们下面讨论的三个模型都基于多线程。
阻塞I/O模型
阻塞 I/O 模型,即服务进程所创建的子线程都按照阻塞式的逻辑来处理每个连接,线程在进行一些系统调用时会被阻塞。不过相比整个服务进程被阻塞,仅仅阻塞一个线程相比而言代价要小的多。另外,当一个线程因没有接收到消息(这个 Socket 连接处于空闲状态)而阻塞时,服务进程可以通过合理的调度方式将 CPU 调度给其它需要的线程。
非阻塞I/O模型
非阻塞 I/O 模型,就是服务进程所创建的子线程都按照非阻塞式的逻辑来处理每个连接。线程在拥有 CPU 的这段时间会做两件事情:
- 每隔一段时间就发起系统调用问询消息是否到达。若消息到达,则返回数据。否则,该系统调用直接返回错误,表示消息未到达。线程需要尝试下一次问询。
- 处理其它的逻辑。
这虽然听起来比阻塞 I/O 模型更加的"聪明",但它带来的开销未必就要比阻塞 I/O 模型就小,因为频繁的进行系统调用意味着 CPU 要频繁地切换上下文。况且,线程应该多长时间去轮询一次呢?这是比较难界定的问题——在多线程环境下,CPU 在这些额外工作上的花销可能更甚,所以非阻塞I/O模型未必比阻塞I/O模型更高效。
I/O 多路复用
多路复用指使用一个主线程充当“哨兵”来检查多个 Socketfd 的状态:当某一个 Socketfd 的消息已经到达内核空间的时候,再另启用一个线程(或者在此主线程内)执行对该 Socketfd 的 read() 方法,将数据从内核空间转移到用户空间,用户程序才得以对消息进行处理。
在前述两个模型中,假设有 10k 个连接,则服务器就创建 10k 个线程。**然而大部分连接并不十分活跃,每个线程大部分时间仍处于空闲状态。**这使得多线程的创建,切换需要额外消耗大量 CPU 资源——但是 CPU 本可以省下切换的时间去做更有意义的事情。
该模型用尽可能少的线程完成并发操作,避免了额外创建大量的线程造成系统资源的浪费,故称之 " 复用 "。I/O 多路复用模型并没有使单个线程的处理速度更快,而是在于开销小,能够支持更多的连接。
具体实现方法有select , poll , epoll 。
这样,整个进程仅在调用 select, poll, epoll 函数的时候才发生阻塞,比如此刻已经没有注册的 Socketfd ,或者没有就绪的 Socketfd 。由于遵循“谁出事了就处理谁”的方式,I/O 多路复用又被称为响应事件模型。
顺带一提,epoll 函数会引发惊群效应,笔者在这里就不再详谈了。
WebSocket
WebSocket 和 Socket 有什么关系?这就好比在问 JavaScript 和 Java 是什么关系?——它们并没有直接的关系。由于 Socket 支持长连接,因此 WebSocket 就顺便借了 Socket 的名号,表示自己是 HTTP 层面上的长连接协议,至少听起来比 WebLongConntectionProtocol 要强很多。
WebSocket ,顾名思义,就是 Web 层面的 Socket 。它于 2008 年诞生,并在 2011 年成为了国际标准。需要基于 WebSocket 开发服务程序的同学,可以通过此页面用来测试你的接口。
既生 Socket,何生 WebSocket ?
既然已经有 Socket API,为什么 HTML5 又单独发展出一个 WebSocket 协议来实现 HTTP 的长连接呢?原因说来也简单:因为浏览器工作在应用层,不支持直接调用系统的 Socket ,每次浏览器发起 HTTP 请求时,底层的 Socket 工作由操作系统来完成,而浏览器真正的用途是接收 HTTP 响应并渲染页面供用户浏览。
浏览器是一个沙盒执行环境,换句话说,浏览器的存在本身就是为了隔离系统环境。如果浏览器涉足 Socket 通信,则它还要额外处理 Socket 通讯的事宜,而这并不是一个应用层的程序应该负责的。
什么是沙盒呢?举个例子,我们可以创建一个虚拟机,并且在这个虚拟机内部做一些破坏性的行为——但这完全不会影响到宿主机,因为这两个系统之间是完全隔离的。这个虚拟机就好比是一个沙盒:你在这个沙盒内部随意作画,涂改,但永远不会影响盒子外部。
况且,直接赋予浏览器以调用原生 Socket 的权限是一个很危险的做法:浏览器有可能通过调用 Socket 隐秘地发送你的私人数据。 Socket 只是一个工具,它不会在乎使用者的意图是否是邪恶的。
因此出于安全的角度,浏览器的权力被 W3C , ECMA 等机构限制在 HTTP 协议体系之内,负责的厂商都会遵循规范。可 HTML5 又希望在 HTTP 的层面上有一个类似 Socket 的全双工通信,因此只好另起门户,WebSocket 就是这样诞生的。
它弥补了 HTTP 协议的哪些不足?
HTTP 协议天生就是为了短连接而设计的,因此并没有考虑到长连接的情况。如果客户端需要在相当长的一段时间内需要时刻获取最新数据, 客户端不得不选择短轮询或长轮轮询的方式来实现:
- 短轮询 - Ajax JSONP Polling:通过 Ajax 每隔一小段时间就发送一个请求到服务器,服务器立刻做响应。
- 长轮询 - Ajax Long Polling:通过 Ajax 发送请求令服务器端长期保持此连接,直到有新数据时才返回。
其中,短轮询会占用大量带宽,而长轮询使得服务器不得不长期保持连接,增大了服务器压力。况且我们在之前介绍过,建立一个 HTTPS 连接甚至会达到 4.5 个 RTT 时延!这对于一些依赖实时性的应用来说,每一次消息通讯都要经历如此高的时延是不可容忍的一件事情。
读者可能会疑问,HTTP/1.1 起已经默认支持“keep-alive”了,难道还不够用吗?服务器确实可以设定时间来延长一些连接时间,但是对于长达数小时的连接来说,仅仅依赖 HTTP 协议的 keep-alive 是不够用的。
还有一个问题:HTTP/2 已经支持服务器推送,为什么不好好利用它呢?HTTP/2.0 的推送主要是为了提前在客户端缓存内容,以达到尽可能减少请求的目的。它并不能用于服务器和客户端间实时的全双工通信。
正如一句真理所言:矛盾是进步的动力。WebSocket 就是为了解决这些问题而诞生的。它天生就支持以下的特性:
- 通过 WebSocket 协议建立通信的双方可以随时互相传输数据,形式上非常接近 Socket 。
- 摒弃了”一问一答“模式,双方基于 WebSocket 定义的四种事件来决定如何通讯,接收到消息时采取何种动作等。
- 与 HTTP 协议有良好的兼容性。
- 拓展性强。
WebSocket 的协议标识符是 ws 。如果是基于 TLS 加密的通讯,则是 wss。(在 Tomcat/Spring Boot 的配置方法和 HTTPS 类似)比如:
ws://websocket.com:8080/endPointwss://secureWebsocket.com:8080/endPoint
WebSocket 打算在既有的基于 HTTP 协议构建的网络设施中保持兼容性,因此仍默认使用 80 或 443 端口,这取决于是使用 ws 还是 wss 进行网络连接。
在 WebSocket 协议中,消息主导方发生了变化。在 HTTP 协议中,服务器端需要被动地等待客户端发送请求以给予相应,而在 WebSocket 协议中,服务器每当有新的消息,就会主动地推送给客户端,客户端不再是绝对占据主动的那一方了。
前端开发人员要使用 WebSocket 协议之前,需要先编写逻辑检查浏览器本身是否支持 ws 或者 wss 连接。因为并不是所有的浏览器和设备都支持它(比如 IE9 以下的浏览器)。不过随着时间的推移,各大浏览器和设备对 WebSocket 的支持度会越来越高。
基于 HTTP 建立 WebSocket 连接
WebSocket 目前基于 HTTP/1.1 协议发起连接。客户端首先发送一个 GET 请求。这个 GET 请求和普通的 HTTP 请求相比增加了以下头部内容:
Upgrade:表示请求升级到 WebSocket 请求。该头部只有一个值:websocket。Connection:表示这是一个包含了升级请求的连接。该头部只有一个值:Upgrade。Sec-WebSocket-Key:由浏览器生成的,用于提供基本的连接保护,防止恶意连接。WebSocket—Version:表示浏览器所支持的 WebSocket 版本号。默认采用 RFC 4655 版本,则该值为13。
当客户端发起 WebSocket 连接请求之后,在得到服务器的正确响应之前,还不能够发送数据。如果服务器同意建立 WebSocket 连接,则返回状态码 101(Switching Protocols),并携带以下头部:
Upgrade:同上。Connection:同上。Sec-WebSocket-Accept:服务器对请求头部中的Sec-WebSocket-Key+258EAFA5-E914-47DA-95CA-C5AB0DC85B11拼接后通过 SHA-1 计算摘要,并转化成的 base64 字符串。Sec-WebSocket-Protocol:浏览器最终采用的 WebSocket 版本号。Access-Control-Allow-Origin:它是一个跨域情况下使用的响应头部,笔者写在这里是为了表示: WebSocket 连接是建立在 CORS 同源策略的相互信任之上的。
WebSocket 用readyState来表示连接状态:
| 字段 | 值 | 含义 |
|---|---|---|
CONNECTING | 0 | 表示正在连接。 |
OPEN | 1 | 连接成功,双方可以进行正常的通信了。 |
CLOSING | 2 | 表示连接正在关闭。 |
CLOSED | 3 | 连接已经关闭,或者表示打开 WebSocket 连接失败。 |
握手成功后,通讯双方可随时发送 ping 信息验证对方是否仍保持连接。当 ping 请求到达另外一方后,对方马上发送 pong 应答消息,通过这种方式确保对方仍然是活跃的,防止一方在断开连接之后,某一方却在不知情的情况下发送大量无用的数据。
帧格式
在建立了一个 WebSocket 通信之后,双方将使用 WebSocket 的数据帧进行数据通信,而不再是传统的 HTTP 数据帧。一个消息可能会拆分成多个帧发送。同时,数据帧支持发送普通文本,或者是二进制格式文件。
0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
下面对标志位做简要介绍。
FIN:表示此帧是否为某个消息的最后一帧。RSV1,RSV2,RSV3:如果没有拓展额外定义这些标志位,则值为0。opencode:用 4 位的十六进制数来表示传输帧的类型。x0:这是一个后续帧。x1:表示这个帧传输的是文本。x2:表示这个帧传输的是二进制内容。x8:表示一个连接关闭。x9:表示一个 ping 。xA:表示一个 pong 。- 其余的值为保留选项。目前,如果该标志位为 x8,x9 或者 xA ,则表示该帧是一个控制帧。
PayLoad Length:代表这个帧的净荷长度。如果长度大于127,则需要有后续的 16 或 64 位拓展位。如果该标志位表示的长度是126,则用后续的 16 位一同表示长度。如果该标志位的值是 127,则用后续的 64 位一同表示长度。因此长度或者小于等于 125,或者是 126 + (16位数) ,或者是 127 + (64位数)。Masking-key:当客户端向服务器端发送帧时,该标志位用于给净荷部分加”掩码“。Payload Data:帧的净荷部分。实际上可以分为Extention Data和Application Data(有先后顺序),但协商若没有做任何扩展,则Extention Data长度为0,不对这两者做区分 。
RFC 6455 制定的部分分帧格式如下:
- 如果不分帧,则
Fin=1且opencode!=0。 - 分帧的消息包含:头帧(
Fin=0,opencode!=0),中间(Fin=0,opencode=0),尾帧(Fin=1,opencode=0)。在仅分两帧的情况下,只有头帧尾帧。 - 消息发送方必须按有序的顺序发送帧。除非协议的拓展规定如何对乱序的帧进行有序处理。
- 为了保证对方能及时对控制帧做出响应,因此控制帧可以插入在一般的消息帧当中发送。
- 控制帧不允许分帧。
- 无论双方如何拓展 WebSocket 协议,双方必须有能力处理接收分帧和不分帧的消息。
- 发送者可以任意的块大小对消息进行分帧。
- 一条消息的所有帧必须全部是一种帧类型,二进制或文本。
WebSocket 事件
WebSocket 定义了消息双方在建立连接,收到消息,出现错误,关闭连接这四个事件发生时应该采取什么样的动作。
onopen:指定当 WebSocket 连接成功之后采取的动作(或称回调函数,下同)。onmessage:指定当从对方接收到消息之后采取的动作。onerror:指定当连接失败之后采取的动作。onclose:指定当连接关闭之后采取的动作。
其具体实现在 JavaScript,Java,Python 等语言中各不相同,且每个事件采取的具体动作取决于应用要实现的业务逻辑,因此笔者在这里就不对其进行过多的描述了。
WebSocket 并不是任何一个技术的替代品
对于任何一个技术,我们都要放在在某个使用场景下来讨论。
经典的 HTTP 协议已经诞生了数十年,各种专门的优化机制体系也很完备了。WebSocket 本质上是一个基于 TCP 的独立协议(仅仅在建立连接时会使用 HTTP 协议):这意味着它要放弃很多原本浏览器支持的服务,需要应用来给出自己的实现。从消息帧当中,我们能发现 WebSocket 在很多地方都进行了"留白"。
很多 Web 服务器及其代理,中间设备都针对于短连接的 HTTP 进行维护 ,而 WebSocket 的设计理念却和 HTTP 大相径庭。长时连接和空闲会话会占用所有中间设备及服务器的内存和套接字资源,开销很大。这对于 WebSocket,SSE ,还是 HTTP/2 都是一项不小的挑战。
另外,并不是所有的客户端都能够支持 WebSocket 协议,甚至说在某些网络中会屏蔽掉 WebSocket 通信。此时作为产品的设计者,需要准备一些备用手段来保证服务的正常进行......比如基于 node.js 的 Socket.io 是一个不错的选择,因为它的库函数提供了在无法使用 WebSocket 协议时”降级通讯“的手段。
总之,我们应该根据自己的实际需求来选择 HTTP, WebSocket,或是其它的 SSE 协议,XHR 技术等 。如果你的 Web 项目并不依赖实时性的消息通讯,那么 HTTP 协议仍然是首要选项。
跨域
跨域问题是 Web 开发当中必须要考虑到的问题,原因就是目前的开发模式已经普遍为前后端分离模式:比如说前端服务是基于 React 框架搭建的,访问URL假设为:A:3000端口。而前端真正的数据源却来自于另一个基于 Tomcat 的 JavaWeb 服务,假设访问URL为B:8080端口。
由于用户在使用浏览器访问页面时,浏览器此刻正在A域下请求页面资源,而前端页面编写 JavaScript 脚本在A域使用 Ajax 来异步访问B域下的资源,由于这个请求被浏览器认定为是跨域请求,因此被拦截下来了。
浏览器为什么会有意拦截跨域请求呢?这和 CSRF 跨域攻击有关系。为了抵御这种攻击,浏览器制定了同源策略,并由此引发了跨域问题。
当然,从 Web 开发人员的角度来看,关注的是以下两点:
- 对信任源发起的 GET 请求,服务器端能够正常返回资源(数据)。
- 服务端需要设立检查机制避免跨域的 POST 请求对数据库的更改/入侵。
🌎本段内的内容主要来源于:HTTP访问控制(CORS)
什么是跨域
产生跨域问题的原因——同源策略
产生跨域问题是出于浏览器的同源策略限制。同源策略(Same Origin Policy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说 Web 是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的 JavaScript 脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面之间具有相同的协议(protocol),主机(host)和端口号(port)。
下面给出了一个表单,来说明哪些请求属于跨域请求。
| 当前页面URL | 被请求页面URL | 是否跨域 | 原因 |
|---|---|---|---|
http://www.test.com/ | http://www.test.com/index.html | 否 | 同源(协议、域名、端口号相同) |
http://www.test.com/ | https://www.test.com/index.html | 跨域 | 协议不同(http/https) |
http://www.test.com/ | http://www.baidu.com/ | 跨域 | 主域名不同(test/baidu) |
http://www.test.com/ | http://blog.test.com/ | 跨域 | 子域名不同(www/blog) |
http://www.test.com:8080/ | http://www.test.com:7001/ | 跨域 | 端口号不同(8080/7001) |
非同源限制
非同源的资源请求,会有以下的限制:
无法读取非同源网页的 Cookie。
无法接触非同源网页的 DOM。
无法向非同源地址发送 Ajax 请求(前后端开发常出现的问题)。
跨域攻击CSRF
CSRF ,即Cross—Site Request Forgery。中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
跟XSS攻击一样, CSRF 存在巨大的危害性,举个例子来说:攻击者盗用了你的身份,以你的名义(Cookies)发送恶意请求,对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。
不过无需太过担心,我们能想到的问题,银行公司早就已经想到并解决了。🤗
用一个实例来讲述跨域攻击的过程
假如说有这样一个请求:
http://bank.example/withdraw?account=bob&amount=1000000&for=bob2这是一个 URL 的 GET 请求。它可以使 Bob 把 1000000 的存款转到 bob2 的账号下。通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,并且该 session 的用户 Bob 已经成功登陆。
黑客 Mallory 自己在该银行也有账户,他知道上文中的 URL 可以把钱进行转帐操作。Mallory 可以自己发送一个请求给银行:
http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory但是这个请求来自 Mallory 而非 Bob,他不能通过安全认证,因此该请求不会起作用。
这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码:
src = "http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory"并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 URL就会从 Bob 的浏览器发向银行,而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。
(重点)大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。这时,悲剧发生了,这个 URL 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。
等以后 Bob 发现账户钱少了,即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。而 Mallory 则可以拿到钱后逍遥法外。
如何抵御 CSRF 攻击
目前防御 CSRF 攻击主要有三种策略:验证 HTTP Refer 头部;在请求地址中添加 token 并验证;在 HTTP 头中自定义属性并验证。
主要针对会引发对数据库进行更新的请求,比如提交表单的POST行为。
对 token 验证形式,这里提供一个简单的思路:
- 【后端】当用户跳转页面的时候,生成一个随机 token ,存放在 session 当中。
- 【页面】form 表单将 token 放在隐藏域中,提交该表单时将 token 放到头部一起提交。
- 【后端】获取头部 token 并校验,与 session 中的 token 一起提交,如果一致则通过,否则不提交。
- 【后端】生成新的 token 并传给前端。
CORS:大可不必因噎废食
在使用 CORS 之前,其实还有一种解决跨域请求的方式:JSONP。不过该方法只支持 GET 请求,对于 POST 等类型的请求存在着诸多局限性,因此在这里就不详细叙述了。
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头部来告诉浏览器:让运行在一个域上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
出于安全原因,浏览器限制从脚本内发起的跨源HTTP请求,除非响应报文包含了正确CORS响应头。
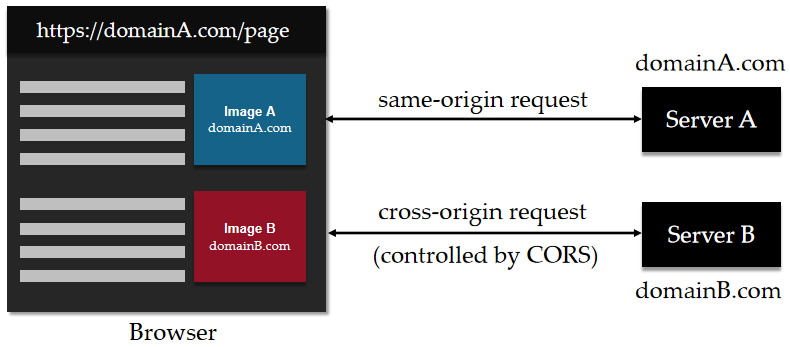
跨域资源共享( CORS )机制允许 Web 应用服务器进行跨域访问控制,从而使跨域数据传输得以安全进行。
简单请求
某些请求不会触发 CORS 预检请求。这样的请求为“简单请求”。若请求满足所有下述条件,则该请求可视为“简单请求”:
使用下列方法之一:
{
GET,HEAD,POST}。仅携带以下请求头的HTTPS会被CORS认为是简单请求:
{
Accept,Accept-Language,Content-Language,Content-Type,DPR,DownLink,Save-Data,Viewport-Width,Width}。Content-Type的值仅限于下列三者之一:{
text/plain,multipart/form-data,application/x-www-form-URLencoded}
客户端和服务器之间使用 CORS 首部字段来处理跨域权限:

预检请求
与前述简单请求不同,“需预检的请求”要求必须首先使用 Options 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。"预检请求“的使用,可以避免跨域客户端传输大量数据却被拒绝的网络资源浪费。
如下是一个需要执行预检请求的HTTP请求:
var invocation = new XMLHttpRequest();var URL = 'http://bar.other/resources/post-here/';
var body = '<?xml version="1.0"?><person><name>Arun</name></person>';
functioncallOtherDomain(){
if(invocation)
{
invocation.open('POST', URL, true);
invocation.setRequestHeader('X-PINGOTHER', 'pingpong');
invocation.setRequestHeader('Content-Type', 'application/xml');
invocation.onreadystatechange = handler;
invocation.send(body);
}
}
上面的代码使用 POST 请求发送一个 XML 文档,该请求包含了一个自定义的请求首部字段(X-PINGOTHER: pingpong)。另外,该请求的 Content-Type 为 application/xml。因此,该请求需要首先发起“预检请求”。

Spring 框架解决跨域请求资源的方式
无论是用什么服务器技术,处理跨域请求的思路基本一致:添加HTTPS响应头,告知浏览器,服务器允许此跨域请求。
对于 Spring 框架,最常用的方法是配置一个WebMvcConfigurer,补充CORS响应头,以便在浏览器端能够通过检查。
import org.springframework.context.annotation.Configuration;import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
publicclassCorsConfigimplementsWebMvcConfigurer{
@Override
publicvoidaddCorsMappings(CorsRegistry registry){
registry.addMapping("/**")
.allowedOrigins("*")
.allowedMethods("GET", "HEAD", "POST", "PUT", "DELETE", "OPTIONS")
.allowCredentials(true)
.maxAge(3600)
.allowedHeaders("*");
}
}
更多的解决方式,点此查看
Cookie
HTTP 是短连接,无记忆性的。因此我们需要一些手段能够让服务器维持它的记忆。在文章的最后两部分,笔者会介绍 Cookie 和 Session 各自的使用用途。
Cookie,属于小型文本文件,一般不超过4K。当你浏览某网站时,网站存储在你机器上的一个小文本文件,它记录了你的用户ID,密码、浏览过的网页、停留的时间等信息,当你再次来到该网站时,网站通过读取Cookie,得知你的相关信息,就可以做出相应的动作,如在页面显示欢迎你的标语,或者记住登录状态等等。
由于Cookie一般都包含加密信息,因此服务器往往会对敏感内容进行加密。
一个Cookie记录着一个k-v键值对。在服务器端做出响应时,这个Cookie会被记录到HTTP报文头中的Set-Cookie当中,其格式为:{name}={value}。每一对k-v都单独放到一个Set-Cookie行。
浏览器会在我们访问站点时自动携带所有可能的 Cookie,因此我们不需要对此过程太过关心。在请求时,浏览器会根据请求的Path把对应Cookies放到请求头中的Cookie,格式为{n1}={v1},{n2}={v2}...。浏览器对同一个域名的 Cookie 数量设有上限,并且该数值不可被设置。同一个站点的 Cookie 超过允许值时,一般的浏览器会采取策略,比如剔除掉最早的 Cookie 。
有一点还要强调一遍:Cookie 是存储在客户端的。不同内核的浏览器之间, Cookie 不能共享,因为每个浏览器内核处理和存储 Cookie 的方式未必相同。
Cookie的结构
在这里列出Cookie的主要内容。
| 属性名 | 描述 |
|---|---|
name | 此Cookie的名称。 |
value | 此Cookie的值。若包含汉字等Unicode字符,则需进行编码。如果是二进制文件,则需BASE64编码。 |
expires | 过期时间。该值若为-1,则该Cookie属于会话Cookie。 |
secure | 如果该值为true,则浏览器仅当通过基于SSL的安全协议(HTTPS)向服务器发送请求时才会携带此Cookie。 |
domain | 设置该Cookie的域名。比如设置.baidu.com,则此Cookie在所有以.baidu.com为后缀的域名内生效。如果服务器是IP地址,则只能指定这个唯一的IP地址。 |
path | 该Cookie的使用路径。如设置为/hello/,则只有以它为前缀的url才携带此Cookie。 |
注:Spring 通过设置maxAge(有效时间),以收到请求的时刻为相对时间,来计算出Cookie Expires 的 GMT 时间。
会话 Cookie
在Spring Boot中,当这个Cookie的maxAge属性被设定为-1时(默认不设定expires),这个Cookie会被认为是会话Cookie。会话Cookie只会保存在客户端内存中,只要用户关闭了浏览器,这个Cookie就会随之消失。
持久 Cookie
设置了过期时间maxAge大于0时,浏览器就会把 Cookie 保存到硬盘上。因此即使浏览器打开之后关闭,这个 Cookie 在“变质”之前仍然有效。
设置 Cookie 所注意的跨域问题
当不对domain作任何设置的时候,domain默认为当前域。
对于IP地址,没有“父IP/子IP”一说。比如请求的是192.168.229.105:8080的 Tomcat 服务,则返回的 Cookie 所属domain就是192.168.229.105。
对于域名,domain还可以(且仅)设置为父域名。如果将 Cookie 的domain设置为二级域名(如taobao.com),则所有在其之下的子域名都可共享。如果将 Cookie 的domain设置为三级域名(如www.taobao.com),则该域则其之下的子域名(pay.www.taobao.com)都可访问,但是其它域名(如buy.taobao.com)是不可以访问的。
值得一提的是,同父域名下的子域名之间属于跨域关系。举例子,客户端通过edu.cookie.com域名访问服务器时,不会携带domain被设置为www.cookie.com的 Cookie ,尽管它们的父域名是一样的。在这种情况下,我们需要 CORS 共享机制来解决这个问题。
如果跨域发起了需要验证身份的请求(如汇款等业务),我们需要在服务器端程序设置响应头的Access-Control-Allow-Credentials 为 true 。同时需要另设置 Access-Control-Allow-Origin 头严格限制允许跨域的域名,不可设置为"*"。
另外,在客户端(前端)发起请求时,XMLHttpRequest.withCredentials同样也要设置为true,表示请求向后端发起一个 Credentials 性质的请求。
在 Spring Boot 下设置Cookie
我们主要需要依赖两个包:
import org.springframework.web.bind.annotation.*;import javax.servlet.http.*;
在此简单演示如何在响应报文中添加 Cookie 。
/*** 一个设置Cookie的简单演示。
* @param response javax.servlet.http.HttpServletResponse.
* @return 返回一个简单文本。
*/
@RequestMapping("/hi")
public@ResponseBody
String setCookie(HttpServletResponse response){
Cookie cookie = new Cookie("name", "value");
//Cookie的所有属性都有对应的set方法。
//以秒计,然后自动转换成格林威治时间。
cookie.setMaxAge(60);
//在响应头添加一个或者多个cookies。
response.addCookie(cookie);
return"hi";
}
在一般情况下,对于 Cookie 的几个值我们都会精确设置,包括domain和path。毕竟作用域越小意味着越安全。如果你需要保证此 Cookie 的传输安全,则可以将secure项设置为 ture。这样,仅当浏览器通过 HTTPS 协议访问此站点时,该 Cookie 才会被携带。
Session
Session 会话其实是描述了一个用户从访问服务到结束访问的一个抽象过程:从用户打开浏览器登录了某一站点,并在一段时间内,在该站点的页面下连续地请求(或提交)了一些资源,到最后以用户关闭浏览器页面表示一个会话的结束。在这个会话期间,用户希望服务器能够记住他的身份,而不至于每一次请求(提交)资源时,都要提交自己的身份认证。

因此我们讨论的 "Session" 其实就是对上述这个需求的实现。大体过程无非就是服务器临时生成一个凭据,并将这个凭据号码发给用户,让用户在一段时间内提交新的请求时只需要附带上这个凭据号码,服务器如果能验证凭据在有效期内且合法,就不需要再让用户额外进行身份验证了。另外,人们还希望能够在这个凭据上写上一些信息,保证服务器能够通过凭据号码找到它们。至于具体的实现方式,我们甚至可以用 JWT (Json Web Token)来达到类似的目的,但是细节有很多不同。在这里我们仅谈论传统意义的 Session 实现方案。
那还有什么方法能够让服务器主动给客户端发送这个凭据号码呢?最有效的方法当然就是 Cookie 无疑了。
以 JavaWeb 的实现举例,每当一个新的请求发送到服务器时,服务器都可以选择生成一个 JSESSIONID (它的名称并不重要,只是代表 "Java 的 SessionID" 而已)作为一个会话的标识符,并以 Cookie 形式返回给用户。现在,我们默许客户端是允许使用 Cookie 的。
在用户保持浏览器页面开启的这段时间,当他下一次发出请求时,浏览器便会携带这个 JSESSIONID 标识号的 Cookie 与服务器端进行交互。服务器会以类似散列表的结构将多个用户的 JSESSIONID 保存至内存当中(为了让服务器能够高速读取);或者写入到文件,数据库中做持久化(一般用于跨服务器 Session 共享)。
Session 典型的应用就是“购物车”案例。由于 HTTP 协议本身并不会存储用户的状态(因为它是无连接的),因此当用户在不同的页面之间切换并浏览商品时,我们需要一个 JSESSIONID 为标识追踪用户状态,当用户向购物车添加商品时,将对应的信息存放在 Session 作用域当中。
Spring Boot 处理 Session 的方式
和处理 Cookie 类似,我们依赖于 java 拓展包 javax.servlet.http下的HttpServletRequest和HttpServletSession来设置 Session 。
比如说这是一个简单地设置 Session 会话属性的 Controller:
import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
@Controller
@RequestMapping("/testSession")
publicclassSessionWaiter{
@RequestMapping("/hi")
public@ResponseBodyString
getSession(HttpServletRequest httpServletRequest){
// 通过getSession()方法获取一个请求的 Session。
// JSESSIONID 原则上保证不重复就可以,框架会替我们自动生成。
HttpSession session = httpServletRequest.getSession();
//设置属性
session.setAttribute("name","tom");
//读取属性
session.getAttribute("name");
//移除属性
session.removeAttribute("name");
//设置有效期,单位为秒,-1代表永不过期
session.setMaxInactiveInterval(1000);
//使其失效
session.invalidate();
return session.getId();
}
}
我们启动这个 Spring Boot 服务并使用 Postman 软件来测试接口,可以捕捉到一个会话 Cookie:

Session 的生存周期
通过上面的例子能发现,记录着 JSESSIONID 的 Cookie 是一个会话 Cookie。这意味着,当用户关闭自己的浏览器页面时,一个会话就结束了。
上句话其实说得并不严谨。用户浏览器关闭与否并不会影响服务器对 Session 有效性的判断。因为服务器感知不到“用户何时关闭了浏览器”并以此来判断会话结束。
服务器实际上会为每一个 Session 设置一个最长不活跃时间(上述代码当中的setMaxInactiveInternal()方法)。如果服务器相当长一段时间内都没有处理附带此 JSESSIONID 凭据号的请求,则服务器会认为客户端单方面结束了会话,从而将这串 JSESSIONID 标识的 Session 以及相关的属性信息及时从内存/文件当中删除以节约空间。
当用户关闭浏览器之后,这个会话 Cookie 将被清除。用户端就再也不会使用此 JSESSIONID 来维持一个会话了(当他下一次重新打开浏览器浏览这个页面时,服务器将会返回一个新的 JSESSIONID 来维持会话),但是这个单方面被遗弃的 JSESSIONID 仍然会在服务器端中保存一段时间,直到setMaxInactiveInternal()函数设置的时间超时。
换一句话说,即使用户不关闭浏览器,当他停留在“购物车”的某个页面当中,并在相当长一段时间内没有再发出任何请求来保持这个会话的活跃性,服务器也仍然会将这个不活跃的 JSESSIONID 清除掉。那多长时间算“相当长一段时间”呢?每个服务器有自己的定义。
我们在某些站点的网页下长时间停留,导致后续的访问遇到了登录信息过期的弹窗,就是因为服务器将 Session 的 MaxInactiveInterval 设置的偏小了一些,以至于我们长时间不做任何操作时,服务器误认为我们已经结束会话了。
那想要长期保存用户的登录状态该如何实现呢?这时笔者推荐更通用的会话 Cookie 形式维持用户的登录状态,并将这个 Cookie 的有效时间设置得稍微久一些。
实现 “ Session ” 的其它方式
然而在有些情况,用户会禁止自己的浏览器存储 Cookie , 因为他们不太喜欢浏览器直接记住他们的敏感信息(当你访问银行网站时,浏览器却已经贴心地帮你填写好了卡号和密码,感觉确实会有点不太舒服)。
禁用 Cookie 意味着自己的登录状态全部无法保存(每次登录一些页面时都要重新输入自己的账号和密码),也意味着 Session 没有办法通过 Cookie 形式跟踪用户会话。作为发开者,我们必须要考虑到这种情况,并且能够保证在客户端禁止使用 Cookie 的条件下仍然能实现 Session 功能。
在 Jsp 时代,我们通常的实现办法就是将返回页面的内部所有超链接全部附加上 SessionId,即 URL 重写方式。
<a href = "www.example.com/subPage">↓在超链接后面追加 SessionID,这样用户下次点击该链接时相当于发送了一个带参的 GET 请求。
<a href = "www.example.com/subPage?JSESSION=1234567">
而在前后端分离兴起之后,前端与后端通过一个 token 令牌形式来交流:比如在接收到用户请求之后,服务器返回一个 token 字符串。在后续的请求当中,前端仅需要将这个 token 放入 HTTP 报文头部,交给后端服务器验证和计算。
包括笔者之前提到的 JWT,就是以” Json 格式实现的 token 交换“。除此之外,JWT 还基于非对称加密方式保证内部信息没有被篡改(但它本身并没有实现对数据的加密)。
另外注:即便浏览器关闭 Cookie 功能,它还是可以通过读取响应报文的Set-Cookie头部接收到 Cookie 信息,但区别就在于此时浏览器不会主动将 Cookie 保存到磁盘。
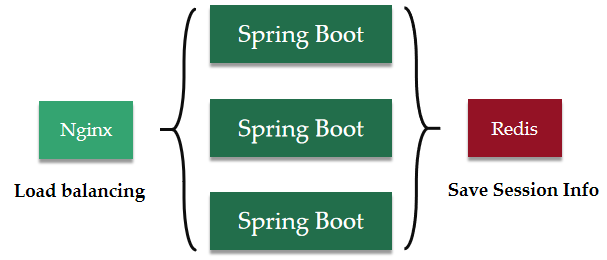
分布式应用保存 Session 的方案
一般情况下,出于读取效率考虑,Session 会直接保存到内存当中。不采取任何共享策略的话,其它服务器是无法获悉某一个服务器内部的 Session 记录的。因此 Nginx 的负载均衡策略当中有一个 ip_hash,它使得访问的用户会被一直导向到记录了对应会话信息的服务器,而不导致会话失效。
但是随着互联网访问量的逐渐增长,分布式应用和集群处理已逐渐成为一种趋势。人们试图让集群下的每一个节点都能够相互共享 Session 。这样一来,负载均衡就不用刻意地将每一个用户引导至固定的服务器节点下了。
实现 Session 共享的方式有很多种,比如说所有节点将 Session 信息保存到一个统一的 Redis 内存数据库当中。像 Java 的 Spring 已经提供了现成的 Spring-Session 解决方案,它在实现 Session 共享的同时还保证了服务的性能,而开发者进行简单的配置即可实现功能。
Cookie or Session ?
从形式和概念来看,Session 和 Cookie 都是独立的两个东西。而有很多人(包括笔者)选择将这两个放到一起作比较,原因可能是 Cookie 和 Session 都能够实现会话跟踪的内容,且在早期,Session 的通用实现是使用会话 Cookie ,因此两者确实有一点关联。但是需要明确一点, Session 未必一定要使用 Cookie 来实现,因为现在有其它的技术和框架能达到相类似的功能。
这段内容主要来源自:Cookies和Session的区别和理解
存取方式
Cookie 是浏览器保存用户信息的一种小型文件。在 Cookie 中,只能保管 ASCII 字符串。如果需要存取 Unicode 字符或者二进制数据,则需要提前进行编码。以 Java 程序为例,我们如果想要以 Cookie 形式保存一个对象实体,则可能需要进行比较复杂的序列化工作。
而 Session 是一个抽象概念,各大语言的 Web 框架对 Session 均给出了自己的实现,因此可以用开发语言各自支持的数据结构保存数据。以 Java 为例,你可以在 Session 中将 Attribute 设置为一个继承于 Object 的实体类型,以便于你的持久层逻辑快速地对这个实体进行操作,而免去了序列化部分。
隐私安全
Cookie 存储在客户端中,或者说存储在电脑磁盘当中。一般情况下我们不会关心 Cookie 存储在那里,但我们是有办法找到它们的,包括在电脑运行的一些其它无意或有意读取 Cookie 内容的应用程序。并且在浏览器发送 HTTP 报文没有被 TLS 层加密保护,且 Cookie 内部的内容也没有进行加密处理,则一些敏感数据和信息可能会被中间人窥探,复制。因此现在一部分的电脑用户不允许浏览器存取 Cookie 信息。
如果将 Cookie 比作是凭据,那么 Session 就相当于仅仅为用户提供了凭据号码,而凭据内部的真正内容保存在服务器方,外部仅仅知道一个 ID 号码,因此从安全性来看,Session 方式要更胜一筹。
有效期不同
虽然 Session 有更好的安全性,但是会话所保存的信息在用户关闭浏览器的一段时间后便不复存在。
而 Cookie 分为会话 Cookie 和持久 Cookie。如果你想长期保存用户信息,只需要针对 Cookie 的 Expires 属性做设置即可。
对服务器的压力不同
Cookie 保管在客户端,因此它的保存不会占用服务器资源。而 Session 的管理和实现均在服务器端,在高并发场景下,由于生成了大量的 Session ,因此会消耗掉大量的内存空间。
对于高并发场景,如果一定要在 Cookie 和 Session 之间抉择的话,笔者会选择前者,以此将一部分存储数据的压力分散到各个客户端中。
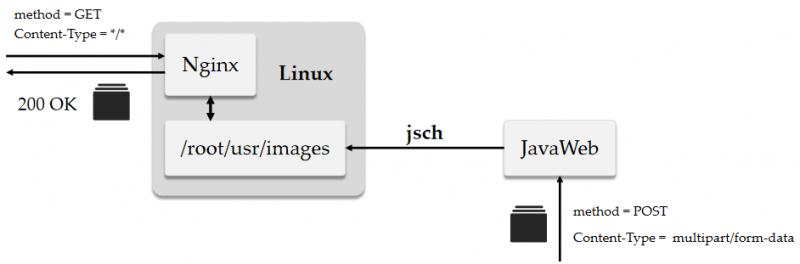
实战:基于 Spring Boot + Nginx 接收文件
需求:用户通过前端页面以 POST 方式将文件发送到 Spring Boot 服务器,Spring Boot 将文件转发到 Nginx 服务器下的/root/images/{data}/目录下。其中data是当天上传的日期,比如 20200624 。
在上传完毕后,我们只需要通过 GET 访问 Nginx 服务器就能访问到静态内容了。
项目唯一的问题就是如何使用 Java 连接远端的centOS主机。因此我们需要引入以下Maven依赖。jcraft主要是用于连接远程的Linux主机,基于 22 端口开启 sftp 连接:
<dependency><groupId>com.jcraft</groupId>
<artifactId>jsch</artifactId>
<version>0.1.54</version>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>2.10.3</version>
</dependency>
Nginx的配置文件有两处需要修改,由于 Nginx 访问了 root 用户下的文件夹,因此我们需要在/etc/nginx/nginx.conf中,将 user 用户由 nginx 修改为 root 。(避免403错误)
+ user root;- user nginx;
work_process 1;
...
在server块中配置location:
# 127.0.0.1/images/a.jpg -> /root/usr/images/a.jpglocation ^~ /images {
expires 1d;
root /root/usr;
autoindex on;
}
我们在项目工程resources目录下另新建一个sftp.properties配置文件,用于连接Nginx服务器:
# 远端的Nginx服务器主机名,或者Ip地址sftp.host = hadoop102
# Nginx服务器的账号密码。
sftp.user = root
sftp.pwd = 123456
# sftp 是隶属于 sshd 的子服务。
sftp.port = 22
# (重要)由于以root身份登录,因此初始目录在/root下。
# 因此资源的实际路径是/root/usr/images。
sftp.rootPath = /usr/images
另外,在application.properties文件中配置 UTF-8 解码方式,一劳永逸地避免文字乱码的问题:
#配置UTF-8解码Unicode字符。spring.http.encoding.charset=UTF-8
spring.http.encoding.enabled=true
spring.http.encoding.force=true
创建一个连接工具,利用@Component注解委托 Spring 根据配置文件自动装配:
package bin.util;import com.jcraft.jsch.Channel;
import com.jcraft.jsch.ChannelSftp;
import com.jcraft.jsch.JSch;
import com.jcraft.jsch.Session;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.PropertySource;
import org.springframework.stereotype.Component;
import java.util.Properties;
/**
* PropertySource=> 手动加载ftp相关的配置文件信息,utf-8字符集。
* Component=> 委托Spring进行自动装配。
*/
@PropertySource(value = "classpath:ftp.properties", encoding = "utf-8")
@Component
publicclassSftpUtil{
@Value("${sftp.host}")
private String host;
@Value("${sftp.user}")
private String user;
@Value("${sftp.pwd}")
private String pwd;
@Value("${sftp.port}")
privateint port;
@Value("${sftp.rootPath}")
private String rootPath;
public ChannelSftp getChannel()throws Exception {
//Create a new session
Session sshSession = new JSch().getSession(user, host, port);
//set session
sshSession.setPassword(pwd);
Properties sshConfig = new Properties();
sshConfig.setProperty("StrictHostKeyChecking", "no");
sshSession.setConfig(sshConfig);
//try connect;
sshSession.connect();
//get channel;
Channel channel = sshSession.openChannel("sftp");
channel.connect();
return (ChannelSftp) channel;
}
//TODO 省略get和set方法。
}
创建一个文件上传的 Service ,使用@Resource 注节解决组件之间的依赖问题。
package bin.service;import bin.util.SftpUtil;
import com.jcraft.jsch.ChannelSftp;
import com.jcraft.jsch.SftpException;
import org.joda.time.DateTime;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
import java.io.IOException;
import java.io.InputStream;
/**
* JavaWeb - - -> (trans2Nginx -> putFile) - - - > Nginx
*/
@Service
publicclassUploadFileService{
@Resource
private SftpUtil sftpUtil;
/**
* 对Controller公开的文件传输方法。
* @param upload 将文件作为参数传递,将由UploadFileService负责传输。
* @return 若传输正常则返回true。
*/
publicbooleantrans2Nginx(MultipartFile upload){
try {
//创建一个日期的dir
String subPath = new DateTime().toString("/yyyyMMdd/");
return putFile(
upload.getInputStream(),
subPath,
upload.getOriginalFilename()
);
} catch (IOException e) {
e.printStackTrace();
}
returnfalse;
}
/**
* 在上传文件之前,首先检测是否有对应的目录。若没有目录,则首先创建目录。
* @param path 需要传入路径。
* @param sftp 传入一个sftp的连接。
* @throws SftpException 可能出现连接异常的问题。
*/
privatevoidcreateDir(String path, ChannelSftp sftp)throws SftpException {
String[] folders = path.split("/");
//mkdir {path} -p
for ( String folder : folders ) {
if ( folder.length() > 0 ) {
try {
sftp.cd( folder );
}
catch ( SftpException e ) {
sftp.mkdir( folder );
sftp.cd( folder );
}
}
}
}
/**
* @param inputStream 将文件转换成输入流传入。
* @param subPath /root/images/下的子目录名称
* @param fileName 传输的文件实际名称
* @return 若传输成功则返回true。
*/
privatebooleanputFile(InputStream inputStream, String subPath, String fileName){
try {
//get Channel
//pwd> /root
ChannelSftp remote = sftpUtil.getChannel();
//put file
String path = sftpUtil.getRootPath() + subPath;
//real path => (/root)/usr/images/20200624/
this.createDir(path,remote);
//补充完整的绝对路径。
remote.put(inputStream,"/"+sftpUtil.getUser() +path + fileName);
//disconnect
remote.quit();
remote.exit();
returntrue;
} catch (Exception e) {
e.printStackTrace();
}
returnfalse;
}
}
在Controller中添加对应的映射方法,通过@RequestParam注解接收multipart/form-data表单中key为file的文件。
@Resourceprivate UploadFileService uploadFileService;
@PostMapping("/postFile")
public@ResponseBody
String postFile(@RequestParam("file") MultipartFile file){
if(uploadFileService.trans2Nginx(file)){
return file.getOriginalFilename() +
" has been uploaded successfully.";
}return"fail";
}
附录:参考资料
感谢以下帖子的发布者为笔者的网络协议复习提供的知识与见解。
HTTP基础
- Spring Boot支持Https有那么难吗?
- 如何在Spring Boot中使用Cookies
- 注解篇@CookieValue
- 关于HTTP协议,一篇就够了
- HTTP请求头,那些你需要记住的基础知识
- HTTP1.0/1.1/2.0的区别
- HTTP协议超级详解
- GET,POST请求,常见的数据编码格式
- HTTP请求/响应报文结构
- 为什么每次请求之前都要发送预检请求?
- 前端面试题之HTTP请求
- HTTP请求方式中8中请求方法
- Spring Boot启动Gzip压缩
- POSTMAN的几种提交方式
- 你还在为Http的这些概念头疼吗?
- Spring开启Gzip压缩
- ContentType以及Spring中的应用
- 详解Http请求中Content-Type
- 在浏览器地址输入一个URL之后回车,背后都会进行哪些步骤?
TCP连接
- 为什么TCP连接需要三次,而不是两次
- 直观明了的总结TCP滑动窗口机制原理
- TCP滑动窗口和拥塞控制机制详解
- TCP的拥塞控制
- 当我们在谈论HTTP队头阻塞时,我们在谈论什么?
- 低延迟与用户体验杂谈
- TCP超时与重传机制
- TCP报文确认送达ACK
- TCP会被UDP取代么?
- TCP 协议快被淘汰了,UDP 协议才是新世代的未来?
- QUIC成为了HTTP/3的标准传输协议!
- 关于QUIC-HTTP/3你需要知道的一切
HTTPS
- Wireshark抓包分析HTTPS和HTTP报文
- HTTP和HTTPS协议,看这一个!
- HTTPS详解《图解HTTP》笔记
CA认证的原理和流程以及https原理✔
- https和ca原理
- https原理及流程
- HTTPS加密(握手)过程
TLS
- TLS1.3规范(RFC文档)
- TLS1.3发展历程
- 7次握手9倍时延
- 转载-HTTPS实战之单向验证和双向验证
- SSL/TLS协议运行机制的概述
- 图解SSL/TLS协议
- 什么是ECDSA公钥私钥加密和签名的基本原理?
- ECC证书和RSA证书
- TLSv1.3详细握手
- TLSv1.3详解
- TLSv1.3 0RTT
- 公钥加密算法那些事 | RSA 与 ECC 系统对比
- 科普TLS1.3
- TLS1.3 vs TLS 1.2
- DH密钥交换简介
HTTP2.0
- HTTP2.0
- 从HTTP/0.9到HTTP/2:一文读懂HTTP协议的历史演变和设计思路
- HTTP2.0新特性
HTTP连接过程
- 客户端浏览器一次http完整请求过程流程图(图文结合诠释请求过程)
- 一次完整的HTTP请求过程
- MDN web docs
跨域 与 Spring 实现
Spring mvc拦截器防御CSRF攻击
Session是怎么实现的?存储在哪里?
SpringBoot自定义 Response Headers
集群环境下使用Spring Session来共享Session
QUIC
- TLS1.3/QUIC 是怎样做到 0-RTT 的
- QUIC协议
- 解读QUIC
- 如何玩转HTTP 3?
- QUIC协议学习3:连接寿命
- QUIC 协议初探- ios实践
- 通往QUIC之路
- 科普:QUIC协议原理分析
- QUIC的五大特性及外网表现
- 如何看待 HTTP/3?
Socket
- 什么是 Socket
- Socket 原理详解
- 创建套接字socket函数的详解(sock_stream和sock_dgram的分析)
- 初识Socket
- 如何确定协议簇?
- SocketType枚举
- 套接字有哪些类型?
- accept产生的端口号是多少?
- socket的accept解析
- 阻塞,非阻塞,异步,同步傻傻分不清楚?
- socket协议 http协议的区别,长短连接,tcp/udp协议区别
- Socket,Websocket,HTTP
- Socket编程到底是什么?
- 什么是 CPU 密集型,什么是 I/O 密集型?
- I/O会一直占用CPU吗?
- 进程调度的时机
- CPU 上下文切换
- 端口占用问题
- 一个进程是否可以拥有多个端口?
- 惊群问题
- Nginx 是以多进程的方式来工作的
- Nginx 中的惊群现象解决办法
- 端口号 & 一个端口号是否可以被多个进程绑定?& 一个进程是否可以bind多个端口号?
- 用户态与内核态
- 多线程模型
- 线程系统调用阻塞是否导致进程阻塞的问题
- 线程崩溃是否造成进程崩溃?
- 进程的基本状态
- 线程,进程,多进程,多线程。并发,并行的区别与关系
- 真正理解阻塞的区别
- Linux 数据包发送过程
- Socket 收发底层原理
- DMA之理解
- 同步阻塞与 I/O 复用
- I/O 阻塞与非阻塞,同步与异步
WebSocket协议
- WebSocket和HTTP2.0
- WebSocket
- WebSocket 数据帧
- 刨根问底HTTP和WebSocket协议(二)
- WebSocket入门到精通
- MDN WebsSocket
- 为什么浏览器不支持调用系统的 Socket ? 而提供了更高层的协议 websocket?
- 为什么不直接使用socket ,还要定义一个新的websocket 的呢?
- 浏览器沙箱(sandBox)到底是什么?
- HTTP/2.0 能替代 websocket 吗?
- 有了 Socket 为什么还要 HTTP ?
Session
- 后端如何生成 Session
- 基于jwt和session的区别和优缺点
- Cookies 和 Session 的区别和理解
实战篇
- 实例详解SpringBoot+nginx实现资源上传功能
- SpringBoot系列——加载自定义配置文件
- 使用jsch远程创建递归目录
以上是 用 4.5 万字,谈一谈网络协议的微缩宇宙 的全部内容, 来源链接: utcz.com/a/35823.html


![ICMP [INTERNET CONTROL MESSAGE PROTOCOL] 网络层协议](/wp-content/uploads/thumbs/268794_thumbnail.jpg)