[译]This is strictly a violation of the TCP specification
阅读原文:
0xfe.com.cn/post/d44c8d…
本文翻译自cloudflare的一篇文章,描述了服务端socker泄漏停留在CLOSE-WAIT状态,但客户端的FIN-WAIT2状态超时回收并使用该socket新建立连接,导致出现Connection TIme Out的情况。因现象和backlog溢出现象有点类似,遂将本文的翻译转载到本博客中,和读者一起进步。
补充,我在最后补充了自己的测试复现,在测试中,没有复现出文中的现象,最终测试的现象和tcpdump trace在最后一部分,供读者参考。
This is strictly a violation of the TCP specification
"自动关闭FIN_WAIT_2严格来说违反了TCP规范"
我被要求调试网络上另一个奇怪的问题。显然,通过CloudFlare的连接有时会因522 HTTP错误而超时。
CloudFlare上的522错误表明我们的边缘服务器和原始服务器之间存在连接问题。最常见的罪魁祸首是源服务器端:源服务器速度慢,脱机或出现高数据包丢失。问题很少出现在我们这边。
在我调试的情况下,两者都不是。CloudFlare与原始服务器之间的互联网连接非常完美。没有数据包丢失,延迟平坦。那么为什么我们看到522错误呢?
此问题的根本原因非常复杂。经过大量调试后,我们发现了一个重要现象:有时,在数千次运行中,我们的测试程序无法在同一台计算机上的两个守护进程之间建立连接。确切地说,NGINX实例正在尝试与本地主机上的内部加速服务建立TCP连接,发生超时错误。
一旦我们知道要寻找什么,我们就可以用旧的方式重现这一点netcat。经过几十次运行,这是我们看到的:
$ nc 127.0.0.1 5000 -vnc: connect to 127.0.0.1 port 5000 (tcp) failed: Connection timed out
来自的视图strace:
socket(PF_INET, SOCK_STREAM, IPPROTO_TCP) = 3connect(3, {sa_family=AF_INET, sin_port=htons(5000), sin_addr=inet_addr("127.0.0.1")}, 16) = -110 ETIMEDOUT
netcat调用connect()以建立与本地主机的连接。这需要很长时间,最终会因ETIMEDOUT错误而失败。Tcpdump确认connect()确实通过环回发送了SYN数据包,但从未收到任何SYN + ACK:
$ sudo tcpdump -ni lo port 5000 -ttttt -S00:00:02.405887 IP 127.0.0.12.59220 > 127.0.0.1.5000: Flags [S], seq 220451580, win 43690, options [mss 65495,sackOK,TS val 15971607 ecr 0,nop,wscale 7], length 0
00:00:03.406625 IP 127.0.0.12.59220 > 127.0.0.1.5000: Flags [S], seq 220451580, win 43690, options [mss 65495,sackOK,TS val 15971857 ecr 0,nop,wscale 7], length 0
... 5 more ...
继续,稍等。刚刚发生什么事了?
好吧,我们调用connect()了localhost,并且超时。SYN数据包通过环回本地主机关闭,但从未得到答复。
环回拥塞
首先想到的是互联网的稳定性。也许SYN数据包丢失了?一个鲜为人知的事实是,在环回接口上不可能有任何数据包丢失或拥塞。当应用程序将数据包发送给它,马上,仍然是内部send的系统调用处理,被传递到合适的目标。没有回送缓冲。调用send回送会触发iptables,网络堆栈传递机制,并将数据包传递到目标应用程序的适当队列。假设目标应用程序的缓冲区中有一些空间,则无法通过环回丢失数据包。
也许是监听应用程序的异常?
在正常情况下,与localhost的连接不应超时。有一种极端的情况可能会发生,即监听应用程序的调用accept()速度不够快时。
发生这种情况时,默认行为是丢弃新的SYN数据包。如果侦听套接字具有完整的接受队列,则新的SYN数据包将被丢弃。目的是引起后退,以减慢传入连接的速率。对等端最终应重新发送SYN数据包,并希望到那时,接受队列将被释放。此行为由tcp_abort_on_overflow 控制。
译者注:这个基本是连接超时应用程序很常见的问题,即连接队列满导致队列溢出从而丢弃SYN,客户端也是在重传SYN后仍未被响应后出现连接超时的报错,可以见博客中的其他几篇文章:
但是在我们的案例中,这种接受队列溢出并未发生。我们的监听应用程序的接收队列为空。我们使用以下ss命令对此进行了检查:
$ ss -n4lt 'sport = :5000'State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:5000 *:*
该Send-Q列显示给listen()syscall 的积压/接受队列大小 -在本例中为128。在Recv-Q对未完成的连接的数目报告接受队列-0。
问题
回顾一下:我们正在建立与localhost的连接。他们大多数工作正常,但有时connect()syscall超时。SYN数据包通过环回发送。因为它是环回,他们都被传递到监听套接字。侦听套接字接受队列为空,但没有看到SYN + ACK。
进一步的调查显示出一些奇怪的现象。我们注意到数百个CLOSE_WAIT套接字:
$ ss -n4t | headState Recv-Q Send-Q Local Address:Port Peer Address:Port
CLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:36599
CLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:36467
CLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:36154
CLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:36412
CLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:36536
...
CLOSE_WAIT是什么?
CLOSE_WAIT-表示服务器已从客户端收到第一个FIN信号,并且连接正在关闭中。这意味着套接字正在等待应用程序执行close()。套接字可以无限期处于CLOSE_WAIT状态,直到应用程序将其关闭为止。错误的情况就像文件描述符泄漏:服务器未在套接字上执行close(),导致CLOSE_WAIT套接字堆积。
这是有道理的。确实,我们能够确认监听应用程序是否泄漏了套接字。
泄漏的套接字虽然不能解释所有问题。
通常,Linux进程最多可以打开1,024个文件描述符。如果我们的应用程序确实用完了文件描述符,则acceptsyscall将返回EMFILE错误。如果应用程序进一步处理了这种错误情况,则可能导致丢失传入的SYN数据包。失败的accept调用不会使套接字从接受队列中退出,从而导致接受队列增加。接受队列不会耗尽,最终将溢出。接收队列溢出可能会导致SYN数据包丢失和连接尝试失败。
但这不是这里发生的事情。我们的应用程序还没有用完文件描述符。这可以通过计算目录中的文件描述符来验证/proc/<pid>/fd:
$ ls /proc/` pidof listener `/fd | wc -l517
517个文件描述符远远少于1,024个文件描述符的限制。此外,我们之前还显示ss了接受队列为空。那为什么我们的连接超时呢?
到底发生了什么
问题的根本原因肯定是我们的应用程序泄漏了套接字。
但是连接超时后,现象仍然无法解释。
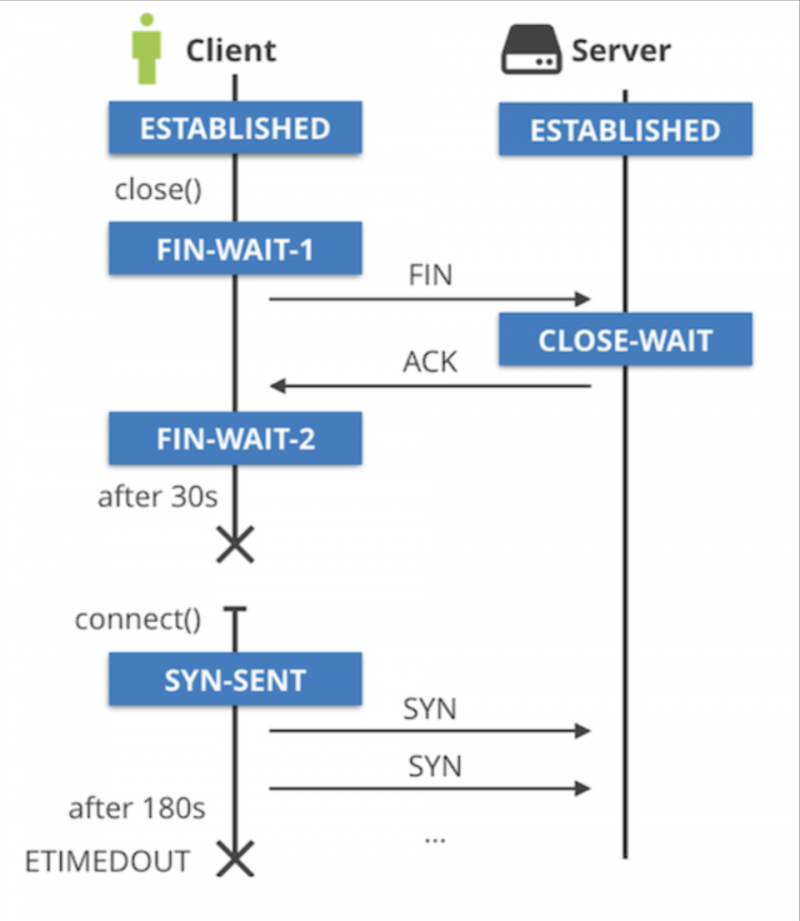
正在监听的应用程序会泄漏套接字,它们永远都处于CLOSE_WAIT TCP状态。这些套接字看起来像(127.0.0.1:5000,127.0.0.1:some-port)。连接另一端的客户端套接字为(127.0.0.1:some-port,127.0.0.1:5000),并已正确关闭并清理。
客户端应用程序退出时,(127.0.0.1:some-port,127.0.0.1:5000)套接字进入FIN_WAIT_1状态,然后快速过渡到FIN_WAIT_2。如果客户端收到FIN数据包,则FIN_WAIT_2状态应转到TIME_WAIT,但这永远不会发生。FIN_WAIT_2最终超时。在Linux上,这是60秒,由net.ipv4.tcp_fin_timeoutsysctl 控制。
这就是问题开始的地方。(127.0.0.1:5000,127.0.0.1:some-port)套接字仍处于CLOSE_WAIT状态,而(127.0.0.1:some-port,127.0.0.1:5000)已被清理并准备重用。发生这种情况时,结果将是一团糟:
套接字的一部分将无法从SYN_SENT状态前进,而另一部分则处于CLOSE_WAIT状态。SYN_SENT套接字最终将因ETIMEDOUT而失败。
如何复现
这一切都开始于一个监听应用程序,该应用程序会泄漏套接字并忘记调用close()。这种错误确实在复杂的应用程序发生中。下面提供一个错误的应用程序代码。
// This is a trivial TCP server leaking sockets.// listener.go
package main
import (
"fmt"
"net"
"time"
)
funchandle(conn net.Conn) {
defer conn.Close()
for {
time.Sleep(time.Second)
}
}
funcmain() {
IP := ""
Port := 5000
listener, err := net.Listen("tcp4", fmt.Sprintf("%s:%d", IP, Port))
if err != nil {
panic(err)
}
i := 0
for {
if conn, err := listener.Accept(); err == nil {
i += 1
if i < 800 {
go handle(conn)
} else {
conn.Close()
}
} else {
panic(err)
}
}
}
运行时,最初不会发生任何事情。ss将显示一个通常的监听套接字:
$ go build listener.go && ./listener &$ ss -n4tpl 'sport = :5000'
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 65535 *:5000 *:* users:(("listener",pid=28443,fd=3))
然后,我们有一个客户端应用程序。客户端行为正确-建立连接并在一段时间后关闭连接。我们可以用nc:
$ nc -4 localhost 5000 &$ ss -n4tp '( dport = :5000 or sport = :5000 )'
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 127.0.0.1:5000 127.0.0.1:25136 users:(("listener",pid=28443,fd=4))
ESTAB 0 0 127.0.0.1:25136 127.0.0.1:5000 users:(("nc",pid=28880,fd=3))
下一步是正常关闭客户端连接:
$kill `pidof nc`State Recv-Q Send-Q Local Address:Port Peer Address:PortCLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:25136 users:(("listener",pid=28443,fd=4))
FIN-WAIT-2 0 0 127.0.0.1:25136 127.0.0.1:5000
一段时间后FIN_WAIT_2将过期:
State Recv-Q Send-Q Local Address:Port Peer Address:PortCLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:25314 users:(("listener",pid=28443,fd=6)) timer:(keepalive,2.076ms,0)
但是CLOSE_WAIT套接字仍然存在!由于listener程序中的文件描述符泄漏,因此不允许内核将其移动到FIN_WAIT状态。它会无限期地停留在CLOSE_WAIT中。如果从不重复使用同一对端口,则这种遗留的CLOSE_WAIT将不会成为问题。不幸的是,它发生并导致问题。
但是CLOSE_WAIT套接字仍然存在!由于listener程序中的文件描述符泄漏,因此不允许内核将其移动到FIN_WAIT状态。它会无限期地停留在CLOSE_WAIT中。如果从不重复使用同一对端口,则这种CLOSE_WAIT流浪将不会成为问题。不幸的是,它发生并导致问题。
要看到这一点,我们需要启动数百个nc实例,并希望内核将冲突端口号分配给其中一个。受影响的人nc将停留connect()一段时间:
$ nc -v -4 localhost 5000 -w0...
我们可以使用ss来确认端口确实发生冲突:
SYN-SENT 0 1 127.0.0.1:36613 127.0.0.1:5000 users:(("nc",89908,3))CLOSE-WAIT 1 0 127.0.0.1:5000 127.0.0.1:36613 users:(("listener",81425,5))
在我们的示例中,内核为nc进程分配了源地址(127.0.0.1:36613)。此TCP流可以用于连接到侦听器应用程序的连接。但是,由于仍使用先前连接的(127.0.0.1:5000,127.0.0.1:36613),并且保持CLOSE_WAIT状态,因此侦听器将无法反向分配流。
内核感到困惑。它重试SYN数据包,但是将永远不会响应,因为另一个TCP套接字处于CLOSE_WAIT状态。最终,我们受影响的人netcat将因不幸的ETIMEDOUT错误消息而死亡:
...nc: connect to localhost port 5000 (tcp) failed: Connection timed out
一个鲜为人知的事实是,除非您手动选择源IP,否则内核自动分配的源端口是增量端口。在这种情况下,源端口是随机的。此bash脚本将创建一个CLOSE_WAIT套接字的雷区,它们随机分布在临时端口范围内。
翻译完。
译者测试现象
抓包复现,可见当重用端口后,服务端close_wait存在时,返回的仅ACK报文,客户端收到后发送RST然后客户端进行1s重试,可能会导致1s超时,未复现出文中的“close_wait常在,且忽略SYN报文”的结论。
17:01:33.137496 IP 127.0.0.1.15002 > 127.0.0.1.5000: Flags [S], seq 1328732168, win 43690, options [mss 65495,sackOK,TS val 345354005 ecr 345351540,nop,wscale 7], length 017:01:33.137504 IP 127.0.0.1.5000 > 127.0.0.1.15002: Flags [.], ack 2, win 342, options [nop,nop,TS val 345354005 ecr 345351539], length 0
17:01:33.137510 IP 127.0.0.1.15002 > 127.0.0.1.5000: Flags [R], seq 1328666631, win 0, length 0 // 1s后重传
17:01:34.139662 IP 127.0.0.1.15002 > 127.0.0.1.5000: Flags [S], seq 1328732168, win 43690, options [mss 65495,sackOK,TS val 345355008 ecr 345351540,nop,wscale 7], length 0
00:34:26.925663 IP 127.0.0.1.5000 > 127.0.0.1.15002: Flags [S.], seq 1570436073, ack 1328732169, win 43690, options [mss 65495,sackOK,TS val 345355008 ecr 345355008,nop,wscale 7], length 0
17:01:34.139699 IP 127.0.0.1.15002 > 127.0.0.1.5000: Flags [.], ack 1, win 342, options [nop,nop,TS val 345355008 ecr 345355008], length 0
17:01:37.270318 IP 127.0.0.1.15002 > 127.0.0.1.5000: Flags [F.], seq 1, ack 1, win 342, options [nop,nop,TS val 345358138 ecr 345355008], length 0
17:01:37.270649 IP 127.0.0.1.5000 > 127.0.0.1.15002: Flags [.], ack 2, win 342, options [nop,nop,TS val 345358139 ecr 345358138], length 0
Whatever,cloudfare的这个case旨在关注close_wait的问题,当服务端未正常处理关闭的连接,可能会导致各种超时问题。
另外看原文中的评论,也有其他人测试现象和我的相同:
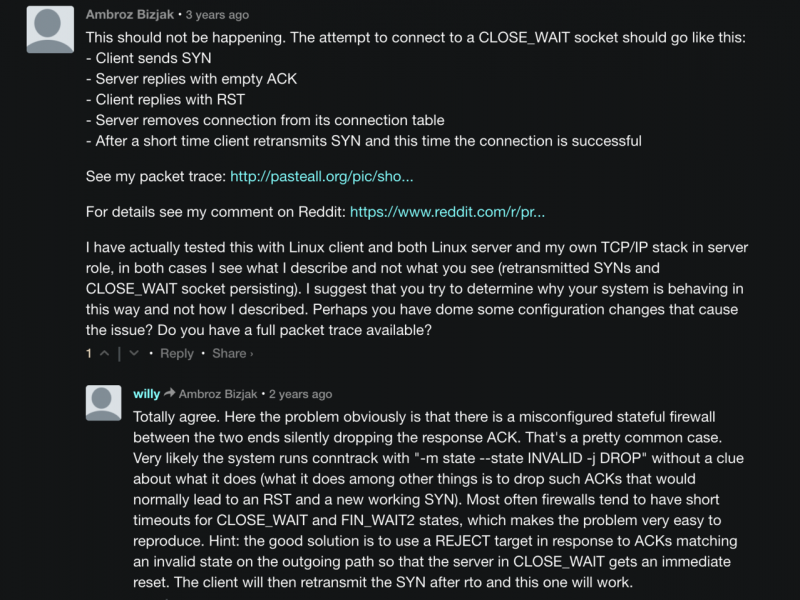
文中的现象可能是中间有防火墙拦住了不关联的ACK,导致客户端未发送RST重置连接?
读者可以自行测试,有不同结论可以邮箱私信我。
以上是 [译]This is strictly a violation of the TCP specification 的全部内容, 来源链接: utcz.com/a/35215.html