
使用markdow-it渲染md文件为html页面
前言:最近在写一些新闻资讯详情的页面,header组件、footer组件、目录组件都是固定的,只有新闻的内容是变化的。为了不去写重复的代码(有句话怎么说来着:战略上偷懒,战术上勤奋,就是这个意思),准备采用md文件渲染为html文件这个思路,如果后续追加新的新闻资讯页面,只需新增对应得md文件即可。
整体思路:把每个新闻资讯页面共有的的部分固定写好作为模板,变化的内容部分写在md文件里面,利用NodeJS读取md文件,转换成html之后,替换模板中变化的内容。
相关技术栈:ReactNext.jsNodeJSmarkdown-it
其他解决方案:这个问题是很久之前就在摸索的了,试了很多方法。有些可以读可以渲染,但是不是最终想要的,不过还是顺便总结一下。
1.使用react-markdown处理
使用参考:
react-markdown 使用总结,这篇非常不错,推荐看
- github参考链接
思路:这个之前尝试过一次,确实能读取md文件的内容,也能把内容作为组件的属性,但是这样做并不符合我的思路,只是把变化的内容放到了md文件里,再读出来放到了组件属性里面操作。不过可以通过这个方法,传递到高阶组件里面处理。
2.使用loader处理
markdown-loaderReact Markdown- ...
都是利用webpack在打包的时候去解析md文件,这个我没有采用,因为我的项目是基于Next.js的,配置文件不知道如何去写比较好。
NodeJS文件处理操作
fs文件模块
1.使用fs模块需手动导入
const fs = require('fs')2.查看文件状态
fs.stat(path[, options], callback) 异步方法
fs.statSync(path[, options]) 同步方法
callback的函数里的err,在文件路径出错的时候会打印错误,文件路径不出错则err打印null;stats打印当前文件的一些状态。birthtime: 文件的创建时间mtime: 文件中内容发生变化,文件的修改时间
- 给
fs.stat()的path传递__filename时可用.isFile()判断当前路径对应的是否是一个文件。 - 给
fs.stat()的path传递__dirname时可用.isDirectory()判断当前路径对应的是否是一个文件夹。
fs.stat(filedir, word">function (eror, stats) {if (eror) {
console.warn('获取文件stats失败')
} else {
var isFile = stats.isFile() //是文件
var isDir = stats.isDirectory() //是文件夹
if (isFile) {
//是文件将如何操作
}
if (isDir) {
//是文件夹将如何操作
}
}
}
3.文件读取与写入
fs.readFile(path[, options], callback) 异步读取
fs.readFileSync(path[, options]) 同步读取
fs.writeFile(file, data[, options], callback) 异步写入
fs.writeFileSync(file, data[, options]) 同步写入
path路径模块
path.join([...paths]):用于拼接路径
如果参数中没有添加/,那么该方法会自动添加
如果参数中有..,那么会自动根据前面的参数生成的路径,去到上一级路径
let str = path.join("/a/b", "c"); // /a/b/clet str = path.join("/a/b", "/c"); // /a/b/c (不添加/会自动添加)
let str = path.join("/a/b", "/c", "../"); // /a/b/c --> /a/b
let str = path.join("/a/b", "/c", "../../"); // /a/b/c --> /a
console.log(str);
path.resolve([...paths]):用于解析路径
如果后面的参数是绝对路径,那么前面的参数就会被忽略
let res = path.resolve('/foo/bar', './baz'); // /foo/bar/bazlet res = path.resolve('/foo/bar', '../baz'); // /foo/baz(上一级)
let res = path.resolve('/foo/bar', '/baz'); // /baz(绝对路径)
console.log(res);
循环文件夹
1.根据文件路径读取文件,返回文件列表
2.遍历读取到的文件列表
3.获取当前文件的绝对路径
4.根据文件路径获取文件信息,返回一个fs.Stats对象
5.根据fs.Stats对象判断当前文件是文件还是文件夹
6.如果是文件夹,就继续遍历该文件夹下面的文件
let mdPath = path.join(__dirname, '/src/md')fileDisplay(mdPath)
function fileDisplay(mdPath) {
//根据文件路径读取文件,返回文件列表
fs.readdir(mdPath, function (err, files) {
if (err) {
console.warn(err)
} else {
//遍历读取到的文件列表
files.forEach(function (filename) {
//获取当前文件的绝对路径
var filedir = path.join(mdPath, filename)
//根据文件路径获取文件信息,返回一个fs.Stats对象
fs.stat(filedir, function (eror, stats) {
if (eror) {
console.warn('获取文件stats失败')
} else {
var isFile = stats.isFile() //是文件
var isDir = stats.isDirectory() //是文件夹
if (isFile) {
//对文件的相关操作
}
if (isDir) {
fileDisplay(filedir) //递归,如果是文件夹,就继续遍历该文件夹下面的文件
}
}
})
})
}
})
}
拷贝文件的几种方式
readFile & writeFile
fs.readFile(filedir, 'utf8', (err, data) => {if (err) console.log(err)
else {
// 读取之后的其他操作
fs.writeFile(writePath, tplData, 'utf8', (err) => {
// 写入操作
})
}
})
createReadStream&createWriteStream
// 1.生成读取和写入的路径letreadPath = path.join(__dirname, "test.mp4");
let writePath = path.join(__dirname, "abc.mp4");
// 2.创建一个读取流
letreadStream = fs.createReadStream(readPath);
// 3.创建一个写入流
let writeStream = fs.createWriteStream(writePath);
// 4.监听读取流事件
readStream.on("open", function () {
console.log("表示数据流和文件建立关系成功");
});
readStream.on("error", function () {
console.log("表示数据流和文件建立关系失败");
});
readStream.on("data", function (data) {
// console.log("表示通过读取流从文件中读取到了数据", data);
writeStream.write(data);
});
readStream.on("close", function () {
console.log("表示数据流断开了和文件的关系, 并且数据已经读取完毕了");
writeStream.end();
});
// 5.监听写入流的事件
writeStream.on("open", function () {
console.log("表示数据流和文件建立关系成功");
});
writeStream.on("error", function () {
console.log("表示数据流和文件建立关系失败");
});
writeStream.on("close", function () {
console.log("表示数据流断开了和文件的关系");
});
pipe()读取流的管道方法
// 1.生成读取和写入的路径letreadPath = path.join(__dirname, "test.mp4");
let writePath = path.join(__dirname, "abc.mp4");
// 2.创建一个读取流
letreadStream = fs.createReadStream(readPath);
// 3.创建一个写入流
let writeStream = fs.createWriteStream(writePath);
// 利用读取流的管道方法来快速的实现文件拷贝
readStream.pipe(writeStream);
markdown-it处理文件
markdown-it中文文档
安装
npm install markdown-it --save用法
//导入const md = require('markdown-it')
//使用
let result = md.render('# markdown-it rulezz!');
具体使用
1.循环读md文件夹下的所有md文件
2.利用markdown-it处理读到的内容
3.读取模板页面的内容
4.处理读取到的文件名称、组件名称转换等(短线转驼峰)
5.替换模板页面中变化的部分为,处理之后的md内容
// md文件路径let mdPath = path.join(__dirname, '/src/md')
// 模板路径
let tplPath = path.join(__dirname, '/src/template.txt')
// filedir其实是循环读取的,这里仅做参考一下
let filedir = path.join(mdPath, filename)
// 读取md文件
fs.readFile(filedir, 'utf8', (err, data) => {
if (err) console.log(err)
else {
let result = md.render(data)
// console.log('md文件读取的结果' + result)
// 读取模板页面
fs.readFile(tplPath, 'utf-8', (err, tplData) => {
if (err) console.log(err)
else {
// 处理md文件名,去掉前面的路径和文件类型后缀
let filename = filedir.replace(__dirname, '')
let startIndex = filename.lastIndexOf('\\')
let endIndex = filename.indexOf('.')
filename = filename.substring(startIndex + 1, endIndex)
// console.log(filename)
// 处理组件名称首字母大写
// A-coder-beauty应为ACoderBeauty
// 模板数据替换
tplData = tplData
.replace('<%componentName%>', componentName)
.replace('<%template%>', result)
.replace('<%componentName%>', componentName)
let writePath = path.join(
__dirname,
'/src/pages',
filename + '.js'
)
// 写入新的文件中
fs.writeFile(writePath, tplData, 'utf8', (err) => {
// console.log(err)
})
}
})
}
})
template.txt文件参考
import React from 'react'import { observer } from 'mobx-react'
// 组件导入
import Head from '../components/head'
import Header from '../components/header'
import Footer from '../components/footer'
import '../styles/common.less' // 通用样式
@observer
class <%componentName%> extends React.Component {
render() {
return (
<div className='article-container'>
<Head></Head>
<Header></Header>
<div className='article-body-container'>
<div className='article-detail-container'>
<%template%>
</div>
</div>
<Footer></Footer>
</div>
)
}
}
export default <%componentName%>
存在问题
markdown-it在处理md文件中的图片时,不能正确转义<img>标签,缺少结束符号,在文档中并没有处理此类问题的解决方法,并且应该是渲染机制的关系。
解决方案一:把源码下载下来,做了些处理,在配置文件中相应的引入了修改后的源码文件。在处理标签的返回结果处增加一个判断,如果是<img>标签,进入上面那个判断即可。
const md = require('./src/utils/markdown-it')()

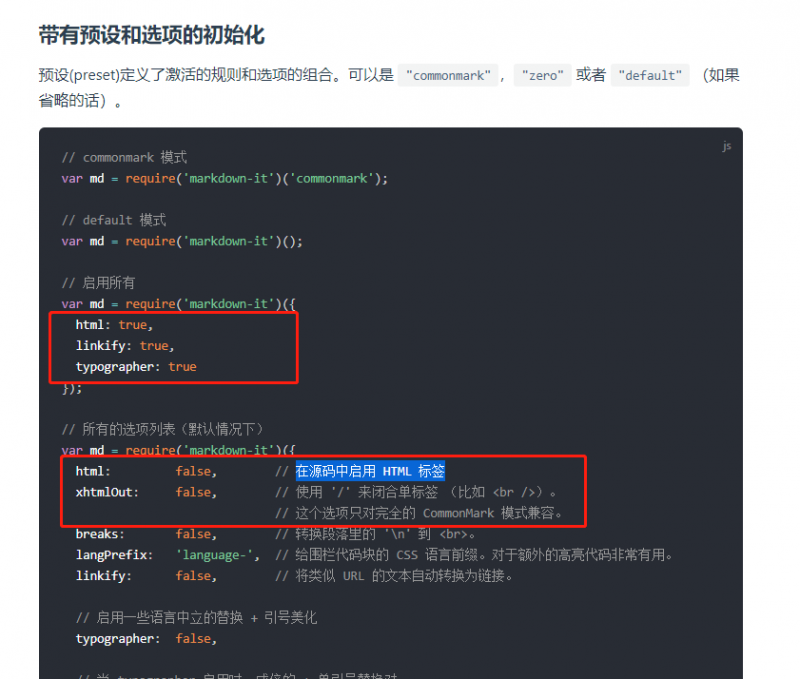
解决方案二:在引入的时候打开启用在源码中启用 HTML 标签即可,有点尴尬(今天才发现这个可以这么解决)
小结
以上所有文件处理代码都是在配置文件next.config.js里面写的,个人对Next.js的使用停留在基础层面,不过webpack.config.js能做的,写在next.config.js里面一样能行。
以上是 使用markdow-it渲染md文件为html页面 的全部内容, 来源链接: utcz.com/a/34039.html


