ShardingSphere分布式数据库中间件
当有一天我们的数据库存储了海量的数据时,查询出来就会变慢了,这时我们就要分库分表了。所以就出现了数据库中间件。
下面举个例子说明一下:
本来你所在的城市里是只有一条道路的,每天大概有200辆车通过这里,还不算堵,突然有一天,车辆增加到了5000辆,这时这条道路一整天都在堵着了,这时政府部门开始行动起来了,增加了两条道路,把你所在的城市的一条道路变成了三条道路,每条道路只能通过不一样的车辆,这样就解决了堵的问题了。我这么说有没有理解了呢,如果理解了就给我点赞吧。
安装并启动
java环境
首先配置好java环境:
cmd 命令下执行 java -version:
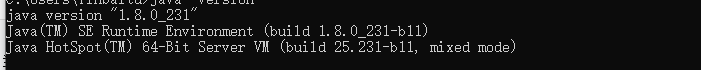
链接:pan.baidu.com/s/1ofb6h2k4…
提取码:v36b
mysql
我采用的mysql版本是:8.0.12
下载sharding-proxy4.1.1
官方网站
sharding-proxy4.1.1下载地扯
如果后端连接MySQL数据库,需要下载mysql-connector-java-5.1.47 解压缩后,将mysql-connector-java-5.1.47.jar拷贝到${sharding-proxy}lib目录。
你也可以在mvnrepository.com/进行搜索mysql-connector-java,然后下载8.0.12的jar包。这两个jar包我都试过,可以正常运行。
启动sharding-proxy4.1.1
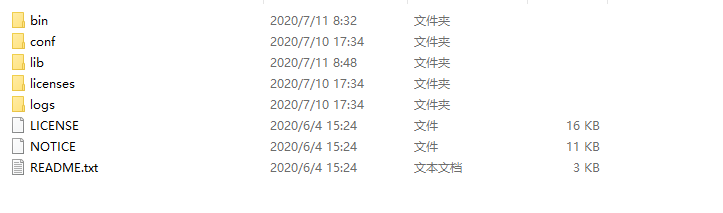
首先解压apache-shardingsphere-4.1.1-sharding-proxy-bin.tar.gz,解压后会看到有以下目录结构:
第一步:修改conf/server.yaml
authentication: users:
root:
password:root# sharding-proxy数据库的root密码为root
sharding:
password:sharding
authorizedSchemas:sharding_db
props:
max.connections.size.per.query:1
acceptor.size:16# 用于设置接收客户端请求的工作线程个数,默认为CPU核数*2
executor.size:16# 工作线程数量,默认值: CPU核数
proxy.frontend.flush.threshold:128# The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy.transaction.type:LOCAL
proxy.opentracing.enabled:false# 是否开启事务, 目前仅支持XA事务,默认为不开启
proxy.opentracing.enabled:false# 是否开启链路追踪功能,默认为不开启
query.with.cipher.column:true
sql.show:false# 是否开启SQL显示,默认值: false
第二步:修改逻辑数据源-分库分表 : conf/config-sharding.yaml
schemaName:sharding_db# 逻辑库名称# 数据源配置
dataSources:
ds_0:
url:jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username:root# 所对应的数据库账号
password:123123# 对应的有数据库密码
connectionTimeoutMilliseconds:30000
idleTimeoutMilliseconds:60000
maxLifetimeMilliseconds:1800000
maxPoolSize:50
shardingRule:
tables:
t_order:
actualDataNodes:ds_${0}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn:order_id
algorithmExpression:t_order_${order_id%2}
keyGenerator:
type:SNOWFLAKE
column:order_id
bindingTables:
-t_order
defaultDatabaseStrategy:
inline:
shardingColumn:user_id
algorithmExpression:ds_${0}
defaultTableStrategy:
none:
注意: 数据库的话,记得自己创建好了。
上面采用的是:单库两张表的分法。奇数分一张表,偶数分一张表。
actualDataNodes :
ds_${0}.t_order_${0..1}这个会分成两张表:t_order_0,t_order_1如果是
ds_${0}.t_order_${0..2}就会分成三张表:t_order_0,t_order_1,t_order_2
最后一步:执行 bin/start文件
windows系统就执行start.bat, linux系统就执行start.sh。
sharding-proxy
sharding-proxy中间件默认采用的数据库端口是:3307。
在上面conf/config-sharding.yaml 我采用的是mysql进行链接,所以我们可以通过mysqlcmd进行操作:
mysql -uroot -P3307 -p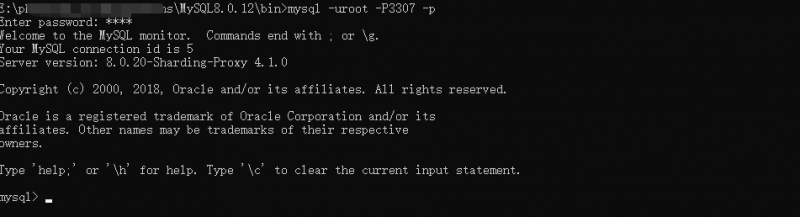
查看当前sharding-proxy的库
show databases;
创建一张表为:t_order
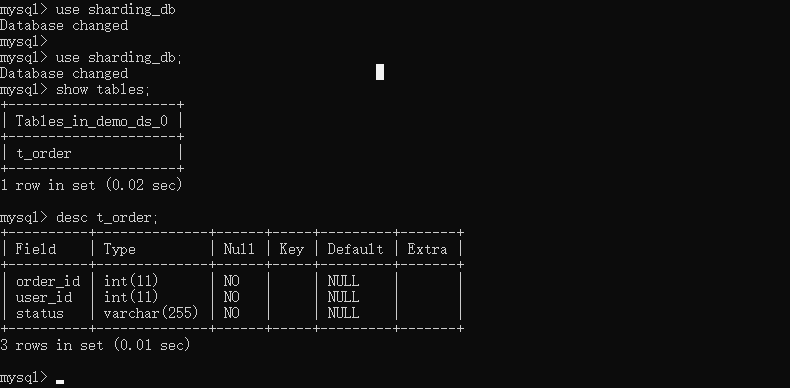
然后往这张表里加入不同的数据,然后再连接上conf/config-sharding.yaml里配置的数据库。可以看到如下:
t_order_0 表的数据

t_order_1 表的数据

通过上面的两张表可以看到来,是通过order_id进行划分的,采用奇偶分表法。
sharding-Proxy 分库
以上是 ShardingSphere分布式数据库中间件 的全部内容, 来源链接: utcz.com/a/31868.html