Go语言学习 - Understanding Lock
Introduction
我们从零开始想象mutex是怎么上锁的, 假设我们规定一种游戏规则: "你必须把这个数字从0变成1". 改成的人算赢, 没改成的人就等着. 等刚刚赢的人再把数字改回0, 这样你就有机会再抢一把了. 这就是mutex上锁的基本原理. 再进一步的, 有如下两个细节:
- 现在有两个线程并行, 他们出手的时候都看到这个是0, 过会儿他们都把这个数字改成1, 这个锁被上了两回, 而且他们都认为自己是对的: "我看到的时候它的确是0呀?我错在哪儿了?"
- 第一个人用完锁了, 其他人如何得知这个锁现在已经可以继续抢了?
并行哄抢的问题
回到问题1, 问题出现的关键就是这个操作并不是原子的,
也就是说是两个人同时抢同时改, 如果我们能让这两个人排一下队, 他抢完了你再抢问题是不是就不会有这种问题了? 说的没错, 但感觉都是废话, 这种并行的东西如何保证让他排队按顺序来呢?
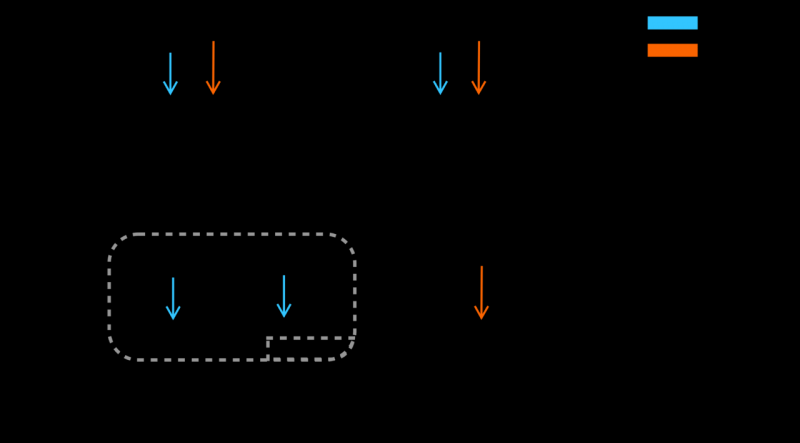
说到底核心就是两个汇编指令: CMPXCHG 与 LOCK, 设想我们在单核心的情况下, 也就是说一次只有一个线程在运行, 这种情况下没有真正的并行, 只有多核心的情况下才会出现真正的并行去抢. 以上两个命令个中, 第一个抢到并且决定上锁的人执行LOCK, 先冷冻住其他核心, 然后CMPXHG负责做比对然后把修改过的数据存回那个内存里
以上, 就是实现锁最核心的一步, 如何让他们排队去修改一个内存, 对应Go里面到处都是的atomic.CompareAndSwap(*addr,old,new), 如果你想要修改*addr里的东西, 从old修改成new, 你必须排队. 这些东西看起来像不像C++里的volatile关键字? 因为二者都使用了类似的冷冻+修改的把戏
沉睡唤醒的问题
我们虽然解决了排队抢锁的问题, 但是这个锁离真正的实用还有一定距离, 比如我们就没解决如何唤醒的问题, 我们都知道有一种东西叫semaphore信号标, 这种东西就能做到沉睡/唤醒G, 比较神奇的是在Go语言里面semaphore的本质上只是一个uint32
type semaRoot struct {treap *sudog
nwait int32
}
funcgetSemaRoot(addr *uint32) *semaRoot {
return &semtable[uintptr(unsafe.Pointer(addr))%semaTableSize]
}
一个数字当然不可能存的下又是沉睡线程又是唤醒这么多功能的, 因此这玩意儿只是一个"index", 只是一个索引, 我们用这个索引召集一个semaphore结构体: 我们有一个全局变量用于存所有的semaphore, 然后用这个数字的地址作为下标, 取出对应真正的结构体, 完成seamphore所有功能的正是这个结构体.
funcsemacquire1(addr) {s := acquireSudog()
root := semroot(addr)
atomic.Xadd(&root.nwait, 1)
for {
if cansemacquire(addr) {
atomic.Xadd(&root.nwait, -1)
break
}
root.queue(addr, s)
goparkunlock(&root.lock)
}
releaseSudog(s)
}
这就是semaphore上锁的过程, 首先我们将当前的G打包成sudog, 然后利用这个uint32获取对应的semaphore, 并将信号标的等待计数+1, 然后进入for沉睡/唤醒循环:
- 如果可以获取信号标, 退出循环, 并将信号标等待计数减1
- 如果不能获得信号标, 将当前g加入信号标等待队列中
- 通过gopark陷入沉睡, 等待唤醒
funcsemarelease1(addr) {root := semroot(addr)
if atomic.Load(&root.nwait) == 0 {
return
}
s, t0 := root.dequeue(addr)
if s != nil {
atomic.Xadd(&root.nwait, -1)
readyWithTime(s)
goyield()
}
}
到了解锁的时候, 我们同样拿着这个uint32先获取semaphore, 如果等待着队列长度为0, 我们不用唤醒任何人, 直接退出, 否则取出一个沉睡的G, 将等待队列长度减1, 通过goready唤醒这个G并放到P的run_next, 最后通过yield()完成一次调度, 直接切换到run_next去执行
sync.Mutex
现在我们已经搞定一个锁的两个核心组件了, 一个是排队, 一个是沉睡+唤醒功能. 有了semaphore作为作为唤醒的基础, 我们唯一需要理解的就只有三种状态是怎么转换的
type Mutex struct {state int32// 状态
sema uint32// 用于计算休眠G数量的信号量
}
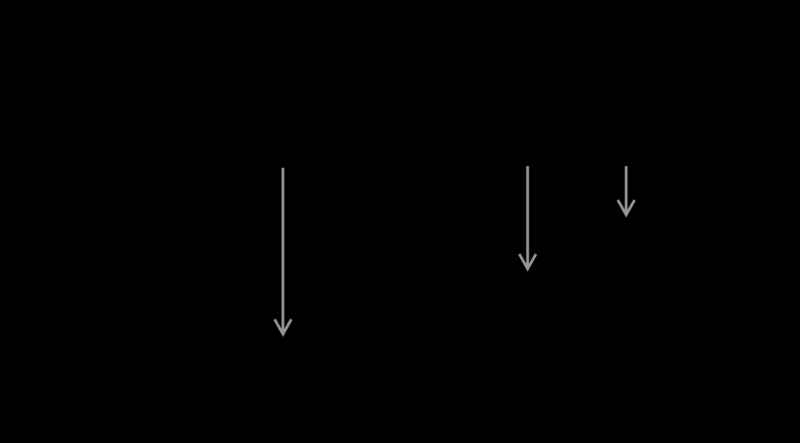
可以看到锁的状态有S/W/L三项, 如果有两个G在争抢使用, 假设这两个G分别是X与Y, 他们的状态迁移是这样的:
- 如果X已经锁定, 则状态为--L(已上锁,无人争夺), 这个时候Y再尝试锁定, 进入沉睡,状态为S-L(已上锁,有人沉睡)
- X此时解除锁定, 状态从S-L变成S--(未上锁,有人沉睡), 进一步的, 发现有人沉睡, 则开始唤醒步骤, 状态变更成-W-(未上锁,有人沉睡且开始唤醒)
- Y被唤醒且成功抢到锁, 状态变成--L(已上锁无人争夺)
- Y还没被唤醒, X就又再次抢锁, X抢成了, 状态变成-WL(唤醒阶段,且被上锁), Y被唤醒后发现锁不可用继续沉睡, 状态变成S-L
sync.RWMutex
type RWMutex struct {w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}
RWMutex是读/写互斥锁。锁可以由任意数量的读者或单个写者持有
mutex的目的是防止两个写G同时写入readerSem的场景: 一个写G任务还没结束, 读G已经想开始读了writerSem的场景: 一些读G任务还没结束, 写G已经想开始写了readerCount字段: 执行中+堵塞中的读GreaderWait字段: 只是执行中的读G
const rwmutexMaxReaders = 1 << 30func(rw *RWMutex)RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
runtime_Semacquire(&rw.readerSem)
}
}
一个新的读G来拉! 无论能不能进行下去, 先给count加一:
- 如果readerCount小于零说明写G正在写, 这个时候读G是不能读的, 通过拿下读锁进入堵塞
func(rw *RWMutex)Lock() {rw.w.Lock()
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_Semacquire(&rw.writerSem)
}
}
首先我们锁上Mutex,防止其他写G跟我抢.
然后我们将count减少1<<30:
- 减少这么大的数字会导致count一定小于零,看看上面的RLock函数, 如果count小于零会导致锁上读锁,从而导致新来的读G堵塞住.
- 检查readerWait, 这个数字代表正在读的(不包含等的)G的数量, 如果这个数字不为零, 代表有读G正在工作, 通过拿下写锁进入堵塞
func(rw *RWMutex)RUnlock() {if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
runtime_Semrelease(&rw.writerSem, false)
}
}
}
- 一个读G结束了, 将readerCount减1, 如果小于零的话说明写G正在工作, 可能也正在堵塞, 我们想知道这个写G到底是在工作还是在堵塞于是我们将readerWait也减1
- 如果得到的不是零, 说明写G真的是在堵塞, 而且还有别的读G还没完工, 写G在等你们读G都结束了才能开始工作
- 如果得到的是零, 说明写G在堵塞, 而且最后一个读G也已经结束了, 这时候释放写锁, 刚刚卡在上锁环节的写G此时被唤醒开始工作
func(rw *RWMutex)Unlock() {r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false)
}
rw.w.Unlock()
}
写G结束了, 这个时候我们可以允许读G开始工作了, 刚刚因为写G工作, 一些读G堵塞着在:
- 将readerCount加回来, 这个时候得到的数字代表正在堵塞中的读G的数量. 通过sema_release放那些读G开始工作
- 我们需要将Mutex释放, 允许其他写G开始工作
ABA问题
funcpop(top) {for {
this := top
next := top.next
if CompareAndSwap(top,this,next) {
break
}
}
}
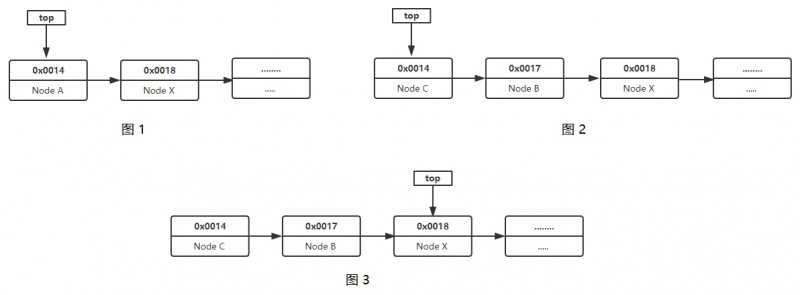
ABA是CompareAndSwap中潜在的隐患, 我们以上面这张图为例, pop()函数删除链表最顶端的节点, 同时指针移到下一个位置上去
- (图一) 开始删了, 预期是能删走节点A, 同时top指针会指在节点X上
- (图二) 就在执行CAS的瞬间, 调度了, 另一个G进来, 先是删了节点A, 然后将节点BC推进来了, 而且节点C的地址恰巧就是之前节点A的地址
- 结束调度, 回到之前的G, 你认为这个时候会发生什么?
根据CAS的原理, 先检查top是不是this: top指向节点C, 地址0x0014, 对上了, 于是top指针变成了0x0018, 直接指向了节点X, 中间的节点B被无视了.
这里面的问题出在哪儿呢? CAS只管表层, 也就是地址的值不变就行了, 至于里面存了什么, 存的东西有没有变是不管的. 这就好像你拎了一箱子钱, 人家把你箱子里钱都偷没了, 你却只知道箱子还是那个箱子, 却不知道钱已经没了, 一个道理. 这就是问题出现的根本原因
ABA问题的解决
doubleCAS被用于解决这种比较极端的例子, 还是刚刚那个例子, 我们要去CAS一个地址, 假设一个地址长32位, 那我们就搞64位整数来存这个地址.

每次CAS的时候比较的不只是地址, 而是地址+计数器这个64位整数, 只有两个都对上了才算通过, 结合上面的ABA问题, 如果这个时候A节点被删了, 同时BC被推进来, 0x0014对应的count肯定是不一样的, 等到调度回来CAS无法通过
Reference
- sema源码分析
- mutex的实现
- cas与ABA问题
- 读写锁
- doubleCAS
以上是 Go语言学习 - Understanding Lock 的全部内容, 来源链接: utcz.com/a/31847.html