MapReduce 源码简析 - Client端
前言
文章主要研究 Client 端具体做的哪些事情, 以及计算向数据移动具体是如何实现的
输出来源:拉勾教育大数据训练营
代码入口
我们在编写 MapReduce 业务逻辑时, 最后基本都是通过 job.waitForCompletion(true) 来提交 Job ,可以进入该方法研究一下具体的实现
为了方便阅读, 删除了部分代码, 重点关注在代码的逻辑流程
// orgapachehadoopmapreduceJob.javaprivatesynchronizedvoidconnect(){
//...
returnnew Cluster(getConfiguration());
//...
}
publicbooleanwaitForCompletion(){
if (state == JobState.DEFINE)
submit(); //*
return isSuccessful();
}
publicvoidsubmit(){
//...
connect();//*
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient()); //*
status = ugi.doAs((PrivilegedExceptionAction) () -> {
return submitter.submitJobInternal(Job.this, cluster); //*
});
//...
}
public JobSubmitter getJobSubmitter(FileSystem fs,
ClientProtocol submitClient){
returnnew JobSubmitter(fs, submitClient);
}
在 Job.java 的 submit() 中可以看到通过 connect() 方法 cluster 对象得到了项目的配置信息, 又通过这些配置信息得到了具体的 FileSystem 和 Client 并创建了用于提交 Job 的 submitter 对象
submitter 使用 submitJobInternal 方法开始提交作业, 在该方法处可以看到以下详尽的注释
The job submission process involves:
Checking the input and output specifications of the job.
//检查此次 Job 的输入输出规范性
Computing the InputSplits for the job.
//计算此次 Job 的切片, 代表着确认多少个 MapTask
Setup the requisite accounting information for the DistributedCache of the job, if necessary.
//大概意思是, 如果需要的话对此次 Job 进行分布式缓存的优化
Copying the job's jar and configuration to the map-reduce system directory on the distributed file-system.
//将 Job 的 jar 和配置文件复制到 HDFS
Submitting the job to the JobTracker and optionally monitoring it's status.
//提交 Job 到 JobTracker 并监控, 这里的 JobTracker 是 hadoop 1.x 的实现, 现在用 Yarn 的话应该是提交 ResourceManager
通过以上注释已经明确接下来的代码可以看到 MapTask 并行度如何确定以及切片的具体机制, 那进入 JobSubmitter 源码好好分析一下
// orgapachehadoopmapreduceJobSubmitter.javaJobStatus submitJobInternal(Job job, Cluster cluster){
//...
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
copyAndConfigureFiles(job, submitJobDir);
int maps = writeSplits(job, submitJobDir);//* 这里计算 map 的数量
//...
}
privateintwriteSplits(JobContext job, Path jobSubmitDir){
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
// hadoop 2.x
maps = writeNewSplits(job, jobSubmitDir);//*
} else {
// hadoop 1.x
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
private <T extends InputSplit>
intwriteNewSplits(JobContext job, Path jobSubmitDir){
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input = //* 通过反射得到 Input
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);//*
List<InputSplit> splits = input.getSplits(job);//*
//...
return array.length;
}
publicJobContextImpl(Configuration conf, JobID jobId){
//...
public Class<? extends InputFormat<?,?>> getInputFormatClass() {
// INPUT_FORMAT_CLASS_ATTR对象代表着配置文件中的 mapreduce.job.inputformat.class
return conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
//...
}
进入 submitJobInternal() 后, 看到 writeSplits(job, submitJobDir) 计算返回 MapTask 的数量, writeSplits() 方法中调用 writeNewSplits(job, jobSubmitDir)
writeNewSplits() 里的 input 对象, 通过 ReflectionUtils 名字可以看出来是反射得到的 Input 具体格式, Hadoop 不少地方都是使用反射获取类型, 通过 getInputFormatClass() 方法得知, InputFormatClass 是用户可以指定的, 如果没有指定就设置成 TextInputFormat.class
代码中的 input.getSplits(job) 获取所有的 split 是 client 最核心的功能, 当点进去发现 InputFormat 是个抽象类, 大体的继承关系如下图
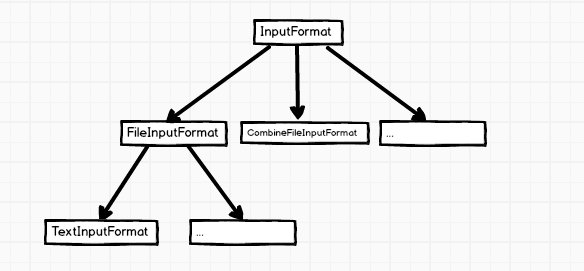
TextInputFormat 中没有 getSplits() 的实现, 往上找具体实现, 看来是在 FileInputFormat 中了
计算 split
// orgapachehadoopmapreducelibinputFileInputFormat.javapublic List<InputSplit> getSplits(JobContext job){
StopWatch sw = new StopWatch().start();
// 默认情况 minSize = 1, 或者修改 mapreduce.input.fileinputformat.split.minsize 属性
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
// 默认情况 maxSize 非常大, 是Long.max
long maxSize = getMaxSplitSize(job);
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
// 1.
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen(); // length 是当前文件的实际大小
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize); //*
// 2.
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); //*
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));// 缓存优化
bytesRemaining -= splitSize;
}
}
}
return splits;
}
protectedlonggetFormatMinSplitSize(){
return1;
}
publicstaticlonggetMinSplitSize(JobContext job){
//SPLIT_MINSIZE 是配置 mapreduce.input.fileinputformat.split.minsize 属性
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
publicstaticlonggetMaxSplitSize(JobContext context){
//SPLIT_MAXSIZE 是配置 mapreduce.input.fileinputformat.split.maxsize 属性
return context.getConfiguration().getLong(SPLIT_MAXSIZE, Long.MAX_VALUE);
}
protectedlongcomputeSplitSize(long blockSize, long minSize,long maxSize){
return Math.max(minSize, Math.min(maxSize, blockSize));
}
protectedintgetBlockIndex(BlockLocation[] blkLocations,long offset){
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block?
if ((blkLocations[i].getOffset() <= offset) &&
(offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){
return i;
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
}
在标记的 1. 处开始先是遍历 Job 中每个 File, 获取 File 中所有 block 的 location 和 blockSize, 并通过计算获取 splitSize, 具体计算公式是
splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
在标记的 2. 处就是实际划分 split 的代码, while 循环条件是剩余文件体积 > split 大小, 默认情况 split 和 block 一一对应
循环体中 length-bytesRemaining 是当前 split 的offset, getBlockIndex(blkLocations, length-bytesRemaining) 方法是计算当前 split 所在的 block 具体位置
循环结束以后 splits 会包含所有的文件的 split 具体关键信息, 同时 splits.size 也就确定了 MapTask 的数量
代码看到这里就清楚了 Client 是如何计算 MapTask 的并行度以及为计算向数据移动做了哪些具体的工作
结语
虽然我已经参与开发工作有段时间了, 实际上对于看源码我还是有些抵触了, 总是摸不着头脑不清楚哪里是重点, 多次以后就对源码相当反感.
这里还是多亏拉勾教育的墨萧讲师对整体学习思路的引导以及训练营对于大数据整体课程安排的合理性.
以上是 MapReduce 源码简析 - Client端 的全部内容, 来源链接: utcz.com/a/30810.html