Map containsKey()和List的contains()的性能分析
今天在做LeetCode的第194场周赛时的第二题时,使用List.contains方法来去重一直超时,在周赛快结束时才知道list的contains是从头开始进行比较,而Map.containsKey则是先通过Hash值得多对应的链表,在链表内进行比较,效率显然高于list。
题目
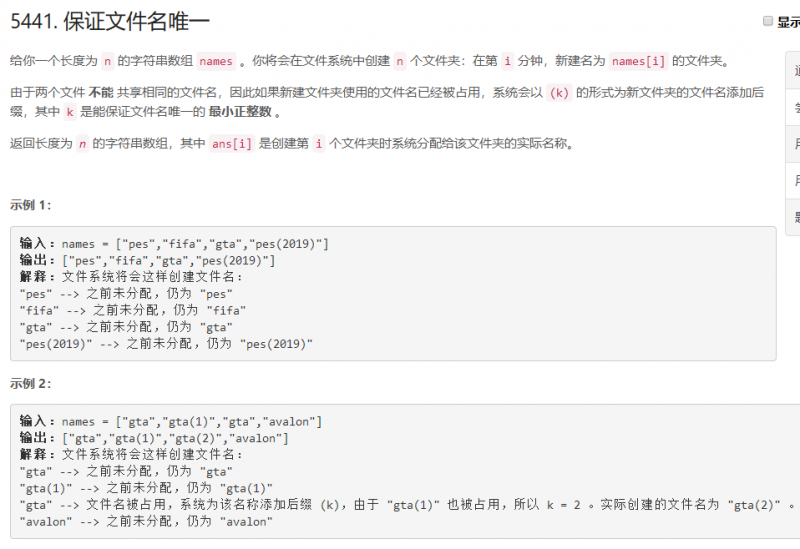
来源于:LeetCode第194场周赛第二题
(1)先附上使用Map的方法
class Solution {public String[] getFolderNames(String[] names) {
Map<String, Integer> differentNameCountMap = new HashMap();
List<String> result = new ArrayList();
for(String name : names) {
Integer count = differentNameCountMap.get(name);
if(count == null) {
differentNameCountMap.put(name, 1);
result.add(name);
continue;
}
while(differentNameCountMap.containsKey(name + "(" + count + ")")) count ++;
result.add(name + "(" + count + ")");
differentNameCountMap.put(name, count + 1);
differentNameCountMap.put(name + "(" + count + ")", 1);
}
String[] resultS = new String[result.size()];
for(int i = 0; i < result.size(); i ++) resultS[i] = result.get(i);
return resultS;
}
}
(2)使用List的情况:
class Solution {public String[] getFolderNames(String[] names) {
Map<String, Integer> differentNameCountMap = new HashMap();
List<String> result = new ArrayList();
for(String name : names) {
//此处使用一次
if(!result.contains(name)) {
differentNameCountMap.put(name, 1);
result.add(name);
continue;
}
Integer count = differentNameCountMap.get(name);
if(count == null) count = 1;
//又使用一次
while(result.contains(name + "(" + count + ")")) count ++;
result.add(name + "(" + count + ")");
differentNameCountMap.put(name, count + 1);
differentNameCountMap.put(name + "(" + count + ")", 1);
}
String[] resultS = new String[result.size()];
for(int i = 0; i < result.size(); i ++) resultS[i] = result.get(i);
return resultS;
}
}
源码分析:
1.ArrayList.contains()源码:
/*** Returns <tt>true</tt> if this list contains the specified element.
* More formally, returns <tt>true</tt> if and only if this list contains
* at least one element <tt>e</tt> such that
* @return <tt>true</tt> if this list contains the specified element
*/
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
*/
public int indexOf(Object o) {
//不管o是否为空,数组都是从头开始进行比较!!
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
2.Map.containsKey()的源码分析
/*** Returns <tt>true</tt> if this map contains a mapping for the
* specified key.
*
* @param key The key whose presence in this map is to be tested
* @return <tt>true</tt> if this map contains a mapping for the specified
* key.
*/
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
/**
* Implements Map.get and related methods
*
* @param hashhashfor key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//进行hash值的比较
//只有一个结点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//该hash值下有多个结点,判读是二叉树还是链表
if ((e = first.next) != null) {
//二叉树的比较方法
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
3.性能分析:
对比两个方法的源码可以得知,Map的containsKey()方法的查找性能明显优于List.contains()。
其实具体的查询效率,是Map是O(n1) 或O(log(n1)),而list则是O(n)
注:n1,表示当前hash值下的节点数,而n表示当前集合的所有元素的总数,明显Map的效率更高。
只能自己当时糊涂了啊!!!
以上是 Map containsKey()和List的contains()的性能分析 的全部内容, 来源链接: utcz.com/a/26782.html