JAVA并发编程阶段总结篇,解决死锁问题以及ThreadLocal原理分析
一、线程的死锁问题
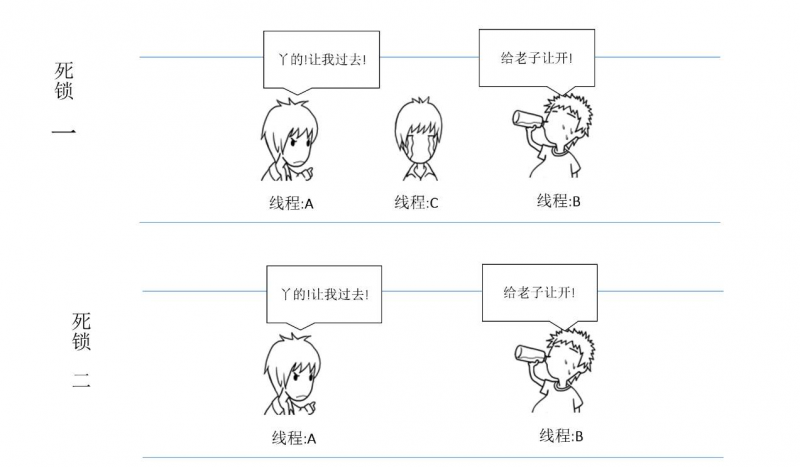
首先来看下死锁的概念吧:一组相互竞争的线程因为相互等待,造成“永久”阻塞的现象,我们称之为死锁;那么有死锁必然就有活锁了,什么是活锁呢?即任务或者执行者都没有被阻塞,由于某些条件未被满足,一直处于重试->尝试执行->执行失败的过程被成为活锁。

1.1 死锁发生的条件
只要满足以下四个条件,就必然会产生死锁:
线程互斥,共享资源只能被一个线程占用,要么线程A要么线程B(有一个坑位,谁抢到就是谁的);
占有且等待,线程T已经获得资源A,在同时等待资源B的时候,不释放资源A(占着茅坑等送纸);
不可抢占,其它线程不能强制抢占线程T占有的资源(有且仅有的坑位被占,不能马上赶走别人);
循环等待,线程T1等待线程T2占有的资源,线程T2等待线程T2占有的资源(我惦记着你的,你惦记着我的)。
1.2 如何解决死锁问题
针对上面的发生死锁的四个条件,只需要破坏其中的一个条件,就不会发生死锁。
- 互斥条件无法破坏,因为使用锁(lock或synchronized)就是互斥的;
- 占有且等待,一次性申请所有的资源,就不存在等待了;
- 不可抢占,占有资源的线程如果需要申请其它资源的时候,可以主动释放占有的资源;
- 循环等待,可以有线性顺序的方式来申请资源。从序号小的开始,然后再接着申请序号大的资源。
1.3 Thread.join
它的作用就是让线程的执行结果对后续线程的访问可见。
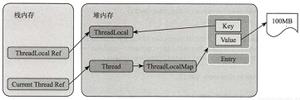
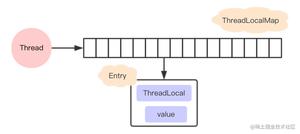
二、 ThreadLocal原理分析
ThreadLocal实际上是一种线程的隔离机制,就是为了保证在多线程环境下对于共享变量的访问的安全性。
2.1 set()方法
/*** Sets the current thread's copy of this thread-local variable
* to the specified value. Most subclasses will have no need to
* override this method, relying solely on the {@link #initialValue}
* method to set the values of thread-locals.
*
* @param value the value to be stored in the current thread's copy of
* this thread-local.
*/
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
当map不为空时,执行map.set(this, value)方法,代码如下:
private void set(ThreadLocal<?> key, Object value) {// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
//根据哈希码和数组长度求得元素的放置位置,即Entry数组的下标
int i = key.threadLocalHashCode & (len-1);
//从i开始遍历到数组的最后一个Entry(进行线性探索)
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
//如果key相等,就覆盖value
if (k == key) {
e.value = value;
return;
}
//如果key为空,用新的key,value,同时清理历史key=null(弱引用)的旧数据
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
//如果超过设置的閥值,则需要进行扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
2.2 线性探测
在上面的源码中使用了线性探测的方式来解决hash冲突问题。
那么什么是线性探测呢?
线性探测是一种开放的寻址策略。hash表是直接通过key访问数据结构的,通过hash函数来把key映射到hash表中的一个位置的访问记录,从而加速查找的速度。存储记录的就叫hash表(也成为散列表)。
由两种方式情况解决这个冲突问题:
写入:找到发生冲突的最近单元
查找:从发生冲突的位置开始,往后查找
通俗的解释是这样子的:我们去蹲坑的时候发现坑位被占,就找后面的一个坑,如果后面的这个坑空着,那么就占用;如果后面的坑被占用,则一直往后面的坑位遍历,直到找到空闲的坑位为止,否则就一直憋着。
2.3 repalceStaleEntry()方法
private void replaceStaleEntry(ThreadLocal<?> key, Object value,int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// Back up to check for prior stale entry in current run.
// We clean out whole runs at a time to avoid continual
// incremental rehashing due to garbage collector freeing
// up refs in bunches (i.e., whenever the collector runs).
//向前扫描,查找最前一个无效的slot
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
//通过循环遍历,可以定位到最前面的一个无效的slot
slotToExpunge = i;
// Find either the key or trailing null slot of run, whichever
// occurs first
//从i开始遍历到数组的最后一个Entry(进行线性探索)
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// If we find key, then we need to swap it
// with the stale entry to maintain hash table order.
// The newly stale slot, or any other stale slot
// encountered above it, can then be sent to expungeStaleEntry
// to remove or rehash all of the other entries in run.
//找到匹配的key
if (k == key) {
//更新对应的slot对应的value
e.value = value;
//与无效的slot进行替换
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
////如果最早的一个无效的slot和当前的staleSlot相等,则从i作为清理的起点
if (slotToExpunge == staleSlot)
slotToExpunge = i;
//从slotToExpunge开始做一次连续的清理
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
//如果当前的slot已经无效,并且向前扫描过程中没有无效slot,则更新slotToExpunge为当前位置
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
//如果key对应的value在entry中不存在,则直接放一个新的entry
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
//如果有任何一个无效的slot,则做一次清理
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
2.4 斐波那契额散列(Fibonacci散列算法)
下面还是给一段ThreadLocal的源码:
//HASH_INCREMENT是为了让哈希码能均匀的分布在2的N次方的数组里private static final int HASH_INCREMENT = 0x61c88647;
/**
* Returns the next hash code.
*/
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
其中定义了一个魔法值 HASH_INCREMENT = 0x61c88647,对于实例变量threadLocalHashCode,每当创建ThreadLocal实例时这个值都会getAndAdd(0x61c88647)。
HASH_INCREMENT 再借助一定的算法,就可以将哈希码能均匀的分布在 2 的 N 次方的数组里,保证了散列表的离散度,从而降低了冲突几率。我们不妨来写段测试代码吧:
public class FibonacciHash {private static final int HASH_INCREMENT = 0x61c88647;
public static void main(String[] args) {
magicHash(16);
magicHash(32);
}
private static void magicHash(int size) {
int hashCode = 0;
for (int i = 0; i < size; i++) {
hashCode = i * HASH_INCREMENT + HASH_INCREMENT;
System.out.print((hashCode & (size - 1)) + " ");
}
System.out.println("");
}
}
执行main()方法的结果:
7 14 5 12 3 10 1 8 15 6 13 4 11 2 9 07 14 21 28 3 10 17 24 31 6 13 20 27 2 9 16 23 30 5 12 19 26 1 8 15 22 29 4 11 18 25 0
产生的哈希码分布确实是很均匀,而且没有任何冲突。
以上是 JAVA并发编程阶段总结篇,解决死锁问题以及ThreadLocal原理分析 的全部内容, 来源链接: utcz.com/a/26509.html