谈谈Redis分布式锁的正确实现方法
前言
最近在参加学校安排的实训任务,我们小组需完成一套分布式&微服务跨境电商,虽然这题目看起来有点老套,并且队友多是 Java 技术栈,所以我光荣(被迫)
的成为了一名前端,并顺路使用 PHP 的 Swoole 帮助负责服务器端的同学编写了几个微服务模块。在小组成员之间的协作中,还是出现了不少有趣的火花。
在昨天 review 队友代码的过程中,发现了我们组分布式锁的写法似乎有点问题,实现代码如下:
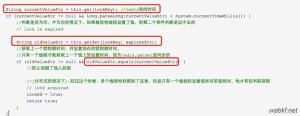
加锁部分

解锁部分
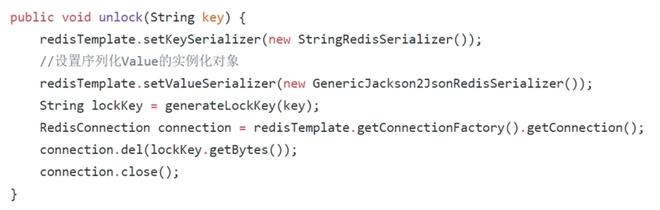
主要原理是使用了 redis 的 setnx 去插入一组 key-value,其中 key 要上锁的标识(在项目中是锁死用户 userId),如果上锁失败则返回 false。但是根据二段锁的思路,仔细思考会存在这么一个有趣的现象:
假设微服务 A 的某个请求对 userId = 7 的用户上锁,则微服务 A 的这个请求可以读取这个用户的信息,且可以修改其内容 ;其他模块只能读取这个用户的信息,无法修改其内容。
假设微服务 A 的当前请求对 userId = 7 的用户解锁,则所有模块可以读取这个用户的信息,且可以修改其内容
如此一来:
- 若微服务模块 A 接收到另一个需要修改 userId = 7 的用户 的请求时,假设这个用户还在被锁状态下,这次请求可以修改它吗?(可以,解个锁就行)
- 若微服务模块 B 接收到另一个需要修改 userId = 7 的用户 的请求时,假设这个用户还在被锁状态下,这次请求可以修改它吗?(可以,解个锁就行)
- 若微服务模块 A 执行上锁的请求中途意外崩掉,其他用户还能修改信息吗? (可以,解个锁就行)
很明显,这三点并不是我们所希望的。那么如何实现分布式锁才是最佳实践呐?
一个好的分布式锁需要实现什么
- 由某个模块的某次请求上锁,并且只有由这个模块的这次请求解锁(互斥,只能有一个微服务的某次请求持有锁)
- 若上锁模块的上锁请求超时执行,则应自动解锁,并还原其所做修改(容错,就算 一个持有锁的微服务宕机也不影响最终其他模块的上锁 )
我们应该怎么做
综上所述,我们小组的分布式锁在实现模块互斥的情况下,忽略的一个重要问题便是“请求互斥”。我们只需要在加锁时,key-value 的值保存为当前请求的 requestId ,解锁时加多一次判断,是否为同一请求即可。
那么这么修改之后,我们可以高枕无忧了吗?
是的,够用了。因为我们开发环境 Redis 是统一用一台服务器上的单例,采用上述方式实现的分布式锁并没有什么问题,但在准备部署到生产环境下时,突然意识到一个问题:如果实现主从读写分离,redis 多机主从同步数据时,采用的是异步复制,也便是一个“写”操作到我们的 reids 主库之后,便马上返回成功(并不会等到同步到从库后再返回,如果这种是同步完成后再返回便是同步复制),这将会造成一个问题:
假设我们的模块 A中 id=1 的请求上锁成功后,没同步到从库前主库被我们玩坏了(宕机),则 redis 哨兵将会从从库中选择出一台新的主库,此时若模块 A 中 id=2 的请求重新请求加锁,将会是成功的。
技不如人,我们只能借助搜索引擎划水了(大雾),发现这种情况还真的有通用的解决方案:redlock。
怎么实现 Redlock 分布式安全锁
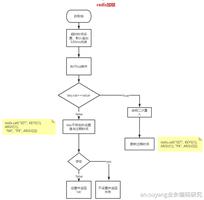
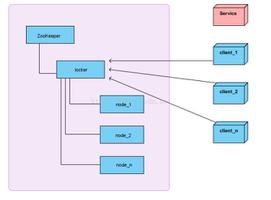
首先 redlock 是 redis 官方文档推荐的实现方式,本身并没有用到主从层面的架构,采用的是多态主库,依次去取锁的方式。假设这里有 5 台主库,整体流程大致如下:
加锁
- 应用层请求加锁
- 依次向 5 台 redis 服务器发送请求
- 若有超过半数的服务器返回加锁成功,则完成加锁,如果没有则自动执行解锁,并等待一段随机时间后重试。(客观原因加锁失败:网络情况不好、服务器未响应等问题, 等待一段随机时间后重试可以避开“蜂拥而进”的情况造成服务器资源占用瞬时猛增 )
- 如有其中任意一台服务器已经持有该锁,则加锁失败, 等待一段随机时间后重试。 (主观原因加锁失败:已经被被别人锁上了)
解锁
直接向 5 台服务器发起请求即可,无论这台服务器上是不是已经有锁。
整体思路很简单,但是实现起来仍有许多值得注意的地方。在向这 5 台服务器发送加锁请求时,由于会带上一个过期时间以保证上文所提到的“自动解锁(容错性) ”,考虑到延时等原因,这 5 台机自动解锁的时间不完全相同,因此存在一个加
锁时间差的问题,一般而言是这么解决的:
- 在加锁之前,必须在应用层(或者把分布式锁单独封装成一个全局通用的微服务亦可)2. 记录请求加锁的时间戳 T1
- 完成最后一台 redis 主库加锁后,记录时间戳 T2
- 则加锁所需时间为 T1 – T2
- 假设资源自动解锁的时间为 10 秒后,则资源真正可利用的时间为 10 – T1 + T2。若
可利用时间不符合预期,或者为负数,你懂的,重新来一遍吧。
如果你对锁的过期时间有着更加严格的把控,可以把 T1 到第一台服务器加锁成功的时间单独记录,再在最后的可用时间上加上这段时间即可得到一个更加准确的值
现在考虑另一个问题,如果恰好某次请求的锁保存在了三台服务器上,其中这三台都宕机了(怎么这么倒霉.. TAT),那此时另一个请求又来请求加锁,岂不又回到最初我们小组所面临的问题了?很遗憾的说,是的,在这种问题上官方文档给出的答案是:启用AOF持久化功能情况会得到好转 🙂
关于性能方面的处理, 一般而言不止要求低延时,同时要求高吞吐量,我们可以按照官方文档的说法, 采用多路传输同时对 5 台 redis 主库进行通信以降低整体耗时,或者把 socket 设置成非阻塞模式 (这样的好处是发送命令时并不等待返回,因此可以一次性发送全部命令再进行等待整体运行结果,虽然本人认为通常情况下如果本身网络延迟极低的情况下作用不大,等待服务器处理的时间占比会更加大)
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。
以上是 谈谈Redis分布式锁的正确实现方法 的全部内容, 来源链接: utcz.com/a/254306.html