Redis基础学习之管道机制详析
前言
Redis服务是一种C/S模型,提供请求-响应式协议的TCP服务,所以当客户端请求发出,服务端处理并返回结果到客户端,一般是以阻塞形式等待服务端的响应,但这在批量处理连接时延迟问题比较严重,所以Redis为了提升或弥补这个问题,引入了管道技术:可以做到服务端未及时响应的时候,客户端也可以继续发送命令请求,做到客户端和服务端互不干涉影响,服务端并最终返回所有服务端的响应,这在促进原有C/S模型交互的响应速度上有了质的提高。
以下是对 Redis管道机制的一个学习记录
Pipeline简介
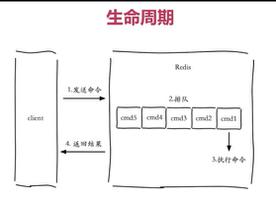
Redis客户端执行一条命令:
- 发送命令
- 命令排队
- 执行命令
- 返回结果
其中发送命令和返回结果可以称为 Round Trip Time (RTT,往返时间)。在Redis中提供了批量操作命令,例如mget、mset等,有效地节约了RTT。但是大部分命令是不支持批量操作的。
为此Redis提供了一个称为管道(Pipeline) 的机制将一组Redis命令进行组装,通过一次 RTT 传输给 Redis,再将这些 Redis 命令的执行结果按顺序传递给客户端。即使用pipeline执行了n次命令,整个过程就只需要一次 RTT。
对Pipeline进行性能测试
我们使用redis-benchmark 对Pipeline进行性能测试,该工具提供了 -P 的选项,此选项表示使用管道机制处理 n 条Redis请求,默认值为1。测试如下:
# 不使用管道执行get set 100000次请求
[root@iz2zeaf3cg1099kiidi06mz ~]# redis-benchmark -t get,set -q -n 100000
SET: 55710.31 requests per second
GET: 54914.88 requests per second
# 每次pipeline组织的命令个数 为 100
[root@iz2zeaf3cg1099kiidi06mz ~]# redis-benchmark -P 100 -t get,set -q -n 100000
SET: 1020408.19 requests per second
GET: 1176470.62 requests per second
# 每次pipeline组织的命令个数 为 10000
[root@iz2zeaf3cg1099kiidi06mz ~]# redis-benchmark -P 10000 -t get,set -q -n 100000
SET: 321543.41 requests per second
GET: 241545.89 requests per second
从上面测试可以看出,使用pipeline的情况下 Redis 每秒处理的请求数远大于 不使用 pipeline的情况。
当然每次pipeline组织的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加 客户端等待时间,另一方面会造成一定的网络阻塞。
从上面的测试中也可以看出,如果一次pipeline组织的命令个数为 10000,但是它对应的QPS 却小于 一次pipeline命令个数为 100的。所以每次组织 Pipeline的命令个数不是越多越好,可以将一次包含大量命令的 Pipeline 拆分为 多个较小的 Pipeline 来完成。
Pipeline关于RTT的说明
在官网上有一段这样的描述:

大致意思就是 :
Pipeline管道机制不单单是为了减少RTT的一种方式,它实际上大大提高了Redis的QPS。原因是,在没有使用管道机制的情况下,从访问数据结构和产生回复的角度来看,为每个命令提供服务是非常便宜的。但是从底层套接字的角度来看,这是非常昂贵的,这涉及read()和write()系统调用,从用户态切换到内核态,这种上下文切换开销是巨大。而使用Pipeline的情况下,通常使用单个read()系统调用读取许多命令,然后使用单个write()系统调用传递多个回复,这样就提高了QPS
批量命令与Pipeline对比
- 批量命令是原子的,Pipeline 是非原子的
- 批量命令是一个命令多个 key,Pipeline支持多个命令
- 批量命令是 Redis服务端实现的,而Pipeline需要服务端和客户端共同实现
使用jedis执行 pipeline
public class JedisUtils {
private static final JedisUtils jedisutils = new JedisUtils();
public static JedisUtils getInstance() {
return jedisutils;
}
public JedisPool getPool(String ip, Integer port) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(RedisConfig.MAX_IDLE);
jedisPoolConfig.setMaxTotal(RedisConfig.MAX_ACTIVE);
jedisPoolConfig.setMaxWaitMillis(RedisConfig.MAX_WAIT);
jedisPoolConfig.setTestOnBorrow(true);
jedisPoolConfig.setTestOnReturn(true);
JedisPool pool = new JedisPool(jedisPoolConfig, ip, port,RedisConfig.TIMEOUT,RedisConfig.PASSWORD);
return pool;
}
public Jedis getJedis(String ip, Integer port) {
Jedis jedis = null;
int count = 0;
while (jedis == null && count < RedisConfig.RETRY_NUM) {
try {
jedis = getInstance().getPool(ip, port).getResource();
} catch (Exception e) {
System.out.println("get redis failed");
}
count++;
}
return jedis;
}
public void closeJedis(Jedis jedis) {
if (jedis != null) {
jedis.close();
}
}
public static void main(String[] args) throws InterruptedException {
Jedis jedis = JedisUtils.getInstance().getJedis("127.0.0.1", 6379);
Pipeline pipeline = jedis.pipelined();
pipeline.set("hello", "world");
pipeline.incr("counter");
System.out.println("还没执行命令");
Thread.sleep(100000);
System.out.println("这里才开始执行");
pipeline.sync();
}
}
在睡眠100s的时候查看 Redis,可以看到此时在pipeline中的命令并没有执行,命令都被放在一个队列中等待执行:
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> get counter
(nil)
睡眠结束后,使用 pipeline.sync()完成此次pipeline对象的调用。
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> get counter
"1"
必须要执行pipeline.sync() 才能最终执行命令,当然可以使用 pipeline.syncANdReturnAll回调机制将pipeline响应命令进行返回。
参考资料 & 鸣谢
- Redis开发与运维
- Using pipelining to speedup Redis queries
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
以上是 Redis基础学习之管道机制详析 的全部内容, 来源链接: utcz.com/a/254242.html