Kafka——一个高吞吐的分布式消息系统
1.SparkStreaming有什么好处?
1)解耦
2)缓冲
2.消息队列常见场景
1)系统之间解耦合
2)峰值压力缓冲
3)异步通信
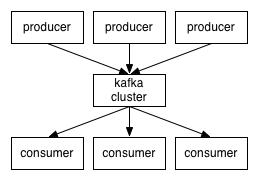
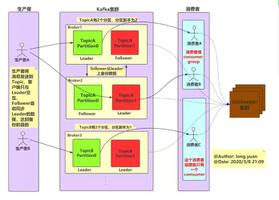
3.kafka的架构
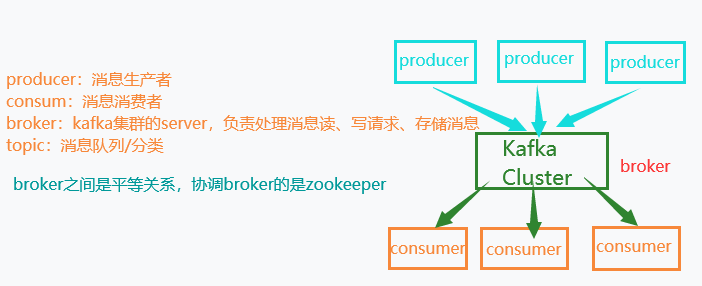
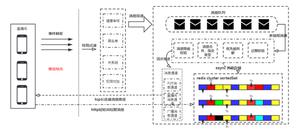
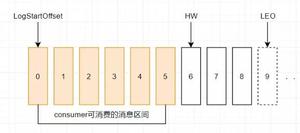
4.kafka的消息存储和生产消费模型
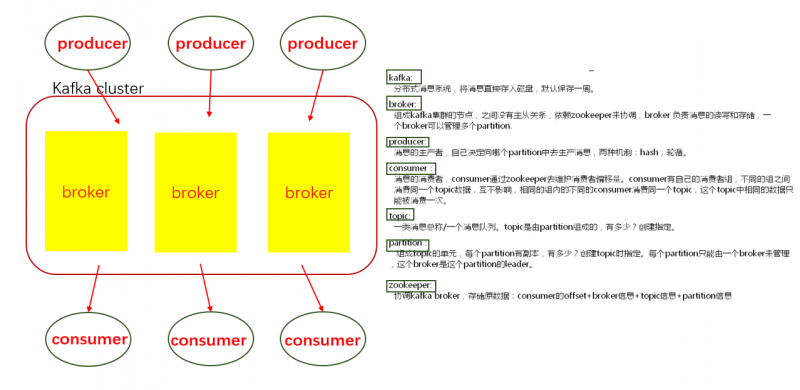
1)一个topic分成多个partition
2)每个partition内部消息强有序,每个消息都有一个序号叫offset
3)一个partition只对应一个broker,一个broker可以管多个partition
4)消息直接写入文件,而不是存储在内存中
5)根据时间策略(默认一周)删除,而不是消费完就删除
6)producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略
7)consumer自己维护消费到哪个offset,每个consumer都有对应的group,group是queue消费模型
8)各个consumer消费不同的partition,一个消息在group内只消费一次,各个group各自独立消费,互不影响
5.kafka的特点
- 消息系统的特点:生存者消费者模型,FIFO
- 高性能:单节点支持上千个客户端,百MB/s吞吐
- 持久性:消息直接持久化在普通磁盘上且性能好
- 分布式:数据副本冗余、流量负载均衡、可扩展
- 很灵活:消息长时间持久化+Client维护消费状态
6.kafka与其他消息队列对比
- RabbitMQ:分布式,支持多种MQ协议,重量级
- ActiveMQ:与RabbitMQ类似
- ZeroMQ:以库的形式提供,使用复杂,无持久化
- radis:单机、纯内存性好,持久化较差
- kafka:分布式,较长时间持久化,高性能,轻量灵活
7.命令
1.生成topic
cd /usr/local/kafka/bin./kafka-topics.sh --zookeeper ht-1:2181,ht-2:2181,ht-3:2181 --create --topic t0426 --partitions 3 --replication-factor 3

2.查看生成的topic
./kafka-topics.sh --zookeeper ht-1:2181,ht-2:2181,ht-3:2181 --list3.控制台当生产者
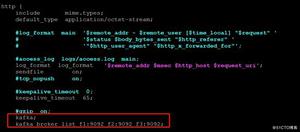
./kafka-console-producer.sh --topic t0426 --broker-list ht-1:9092,ht-2:9092,ht-3:90924.控制台当消费者
./kafka-console-consumer.sh --bootstrap-server ht-1:9092 --topic t04265.查看topic的描述信息
./kafka-topics.sh --zookeeper ht-1,ht-2,ht-3 --describe --topic t0426
6.查看producer生产消息的最大位置
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list ht-1:9092 --topic t0427 --time -1
7.删除topic
./kafka-topics.sh --zookeeper ht-1:2181,ht-2:2181,ht-3:2181 --delete --topic t0426
8.kafka的Leader均衡机制
当partition的leader挂掉之后,会按照副本优先原则去寻找新的leader,由新的broker来管理partition,当挂掉的leader重新启动,partition会重新由原来的broker管理
9.删除topic
1.命令删除topic,当前topic被标记删除,默认一周之后被删除
2.清除broker上当前topic的数据目录
3.去zookeeper中删除原数据
4.删除zookeeper中被标记删除的topic信息
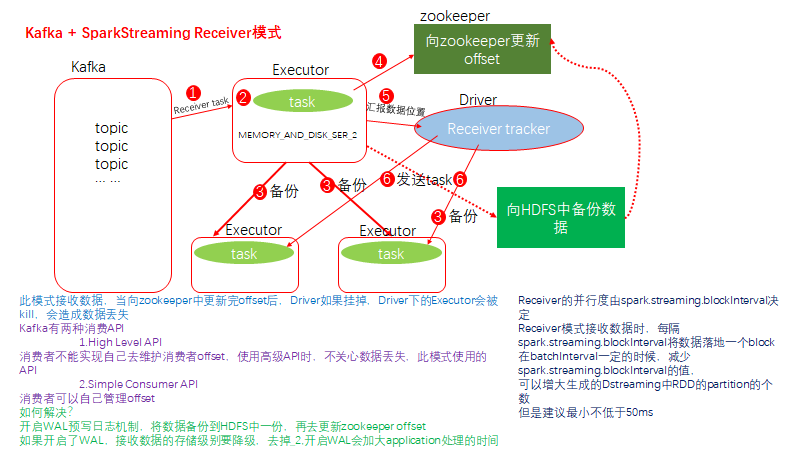
10.SparkStreaming + Kafka 的Receiver模式
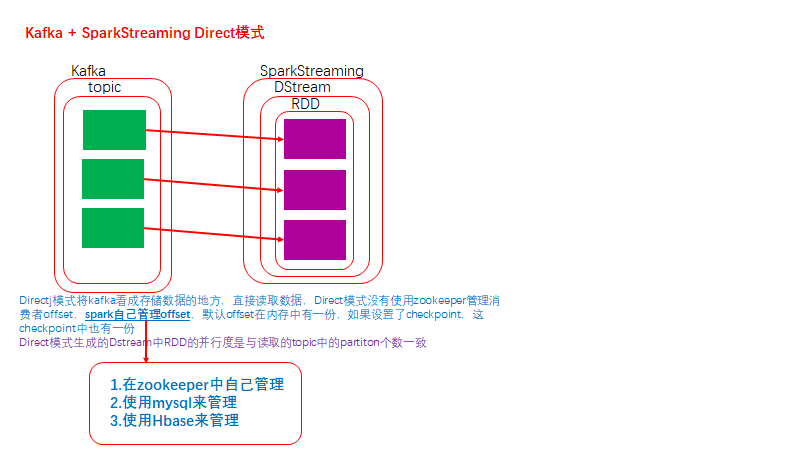
11.SparkStreaming + Kafka 的Direct模式
以上是 Kafka——一个高吞吐的分布式消息系统 的全部内容, 来源链接: utcz.com/a/25289.html