zookeeper分布式锁原理及实现
前言
本文介绍下 zookeeper方式 实现分布式锁原理简介
zookeeper实现分布式锁的原理就是多个节点同时在一个指定的节点下面创建临时会话顺序节点,谁创建的节点序号最小,谁就获得了锁,并且其他节点就会监听序号比自己小的节点,一旦序号比自己小的节点被删除了,其他节点就会得到相应的事件,然后查看自己是否为序号最小的节点,如果是,则获取锁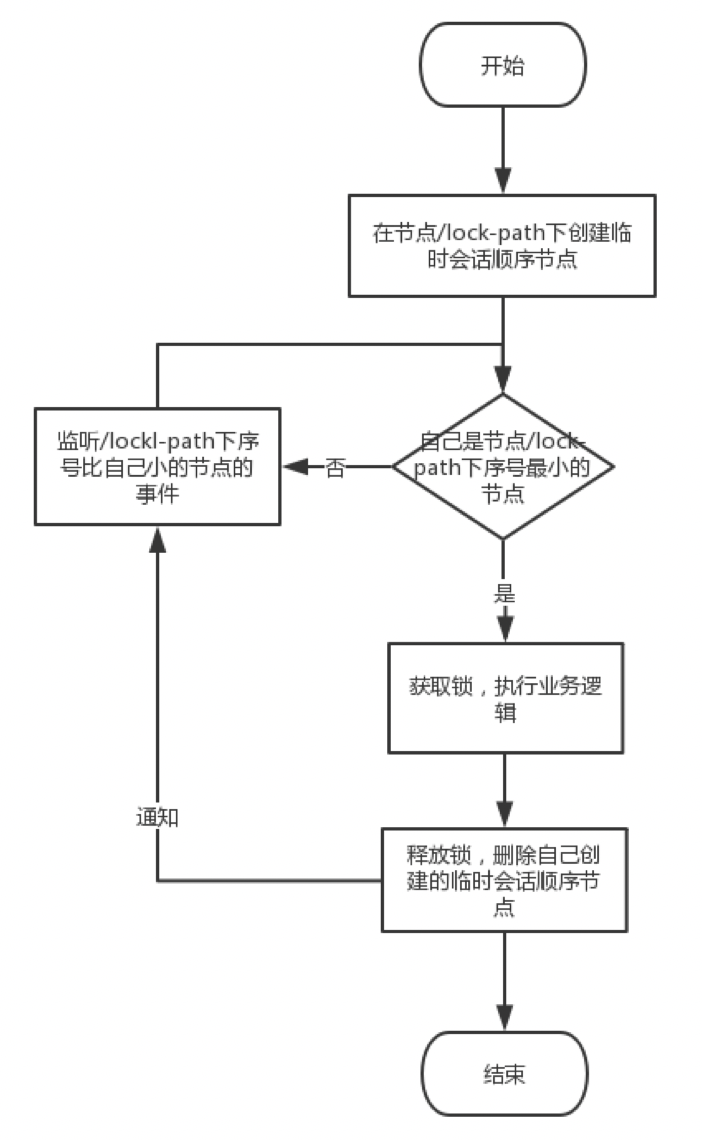
docker 安装 zk
下载镜像
docker pull zookeeper启动镜像
docker run --name zk -p 2181:2181 -p 2888:2888 -p 3888:3888 --restart always -d zookeeper
-p 端口映射--name 容器实例名称
-d 后台运行
2181 Zookeeper客户端交互端口
2888 Zookeeper集群端口
3888 Zookeeper选举端口
查看容器
docker ps |grep zookeeperzk简单的几个操作命令
进入docker容器
docker exec -it 942142604a46 bash查看节点状态
./bin/zkServer.sh status开启客户端
./bin/zkCli.sh创建临时节点
create -e /node1 node1.1
创建临时节点,当客户端关闭时候,该节点会随之删除。不加参数-e创建永久节点
获取节点值
get /node列出节点值
ls /node删除节点值
delete /node查看节点信息
stat /test先介绍下zk的客户端框架Curator
简介
Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等Curator的maven依赖
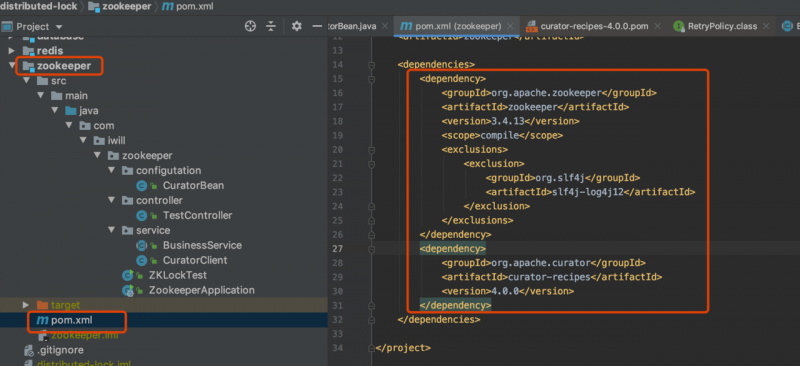
介绍下Curator的基本API
使用静态工程方法创建会话
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",
5000, 5000, retryPolicy);
RetryPolicy为重试策略第一个参数为baseSleepTimeMs初始的sleep时间,用于计算之后的每次重试的sleep时间。
第二个参数为maxRetries,最大重试次数
使用Fluent风格api创建
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(5000) // 会话超时时间
.connectionTimeoutMs(5000) // 连接超时时间
.retryPolicy(retryPolicy)
.namespace("base") // 包含隔离名称
.build();
client.start();
创建数据节点
lient.create().creatingParentContainersIfNeeded() // 递归创建所需父节点.withMode(CreateMode.PERSISTENT) // 创建类型为持久节点
.forPath("/nodeA", "init".getBytes()); // 目录及内容
删除数据节点
client.delete().guaranteed() // 强制保证删除
.deletingChildrenIfNeeded() // 递归删除子节点
.withVersion(10086) // 指定删除的版本号
.forPath("/nodeA");
读取数据节点
byte[] bytes = client.getData().forPath("/nodeA");System.out.println(new String(bytes));
读stat
Stat stat = new Stat();client.getData()
.storingStatIn(stat)
.forPath("/nodeA");
修改数据节点
client.setData().withVersion(10086) // 指定版本修改
.forPath("/nodeA", "data".getBytes());
事务
client.inTransaction().check().forPath("/nodeA").and()
.create().withMode(CreateMode.EPHEMERAL).forPath("/nodeB", "init".getBytes())
.and()
.create().withMode(CreateMode.EPHEMERAL).forPath("/nodeC", "init".getBytes())
.and()
.commit();
其他
client.checkExists() // 检查是否存在.forPath("/nodeA");
client.getChildren().forPath("/nodeA"); // 获取子节点的路径
异步回调
Executor executor = Executors.newFixedThreadPool(2);client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.inBackground((curatorFramework, curatorEvent) -> {
System.out.println(String.format("eventType:%s,resultCode:%s",curatorEvent.getType(),curatorEvent.getResultCode()));
},executor)
.forPath("path");
zk分布式实现的代码分析
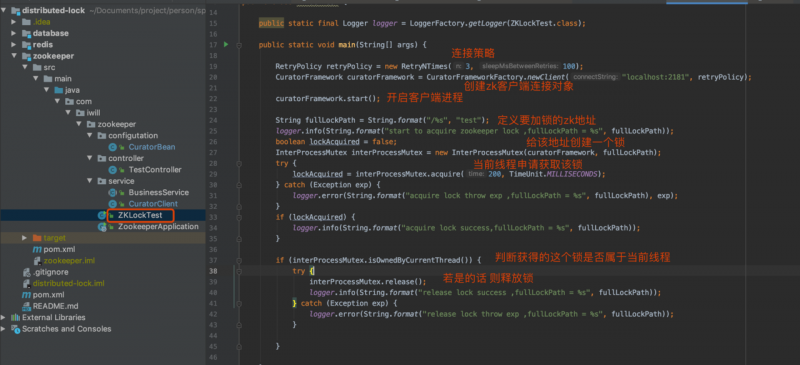
先说下这个test方法 描述了 获取zk锁的完整流程
再说下 如何通过访问接口的方式的实现
目录结构
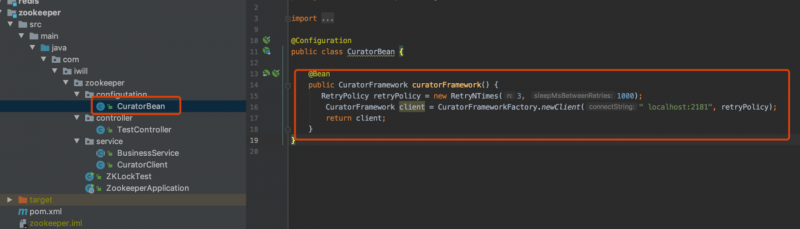
初始化zk客户端连接
zk 客户端申请、释放锁实现
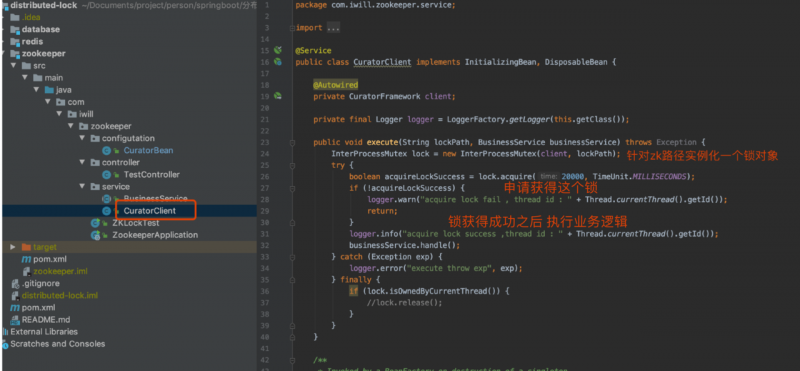
实现了 InitializingBean, DisposableBean接口
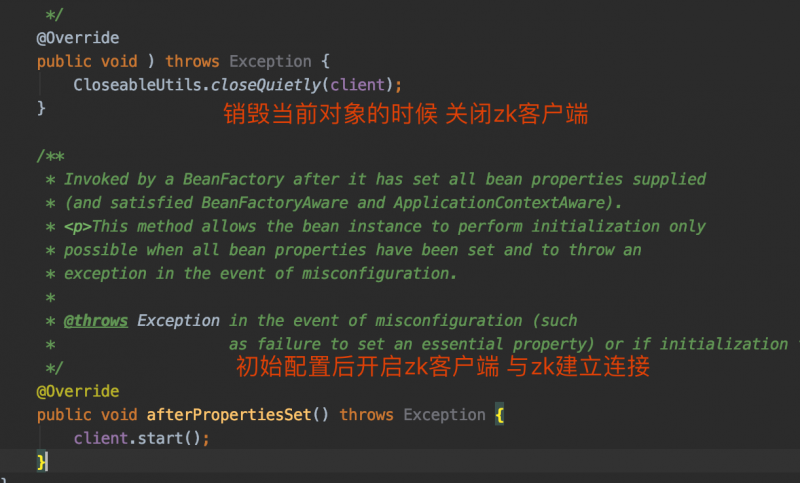
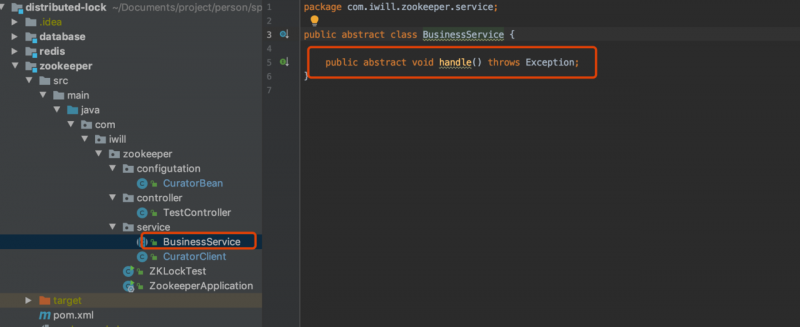
应用在启动的时候(client.start方法执行的时候)zookeeper客户端就会和zookeeper服务器时间建立会话,系统关闭时,客户端与zookeeper服务器的会话就关闭了定义一个抽象的业务处理接口
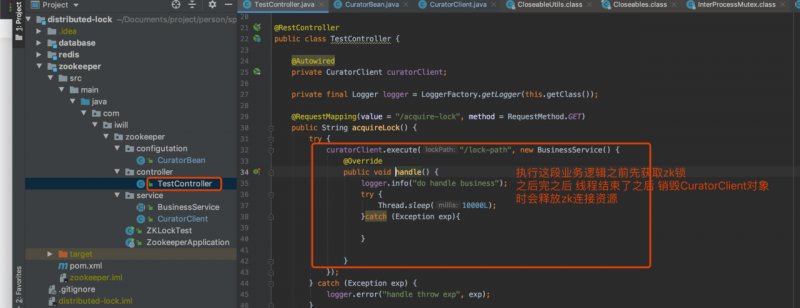
单个线程获取zk锁
多个线程获取zk锁
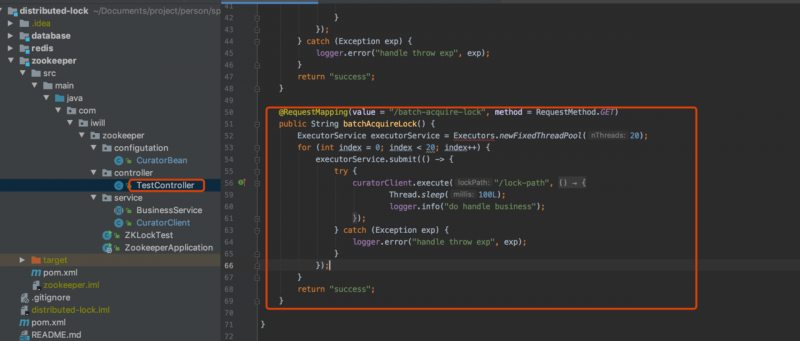
创建线程池ExecutorService executorService = Executors.newFixedThreadPool(20);
20个线程同时发起对同一个zk锁的获取申请
Curator 源码分析
会话的建立与关闭
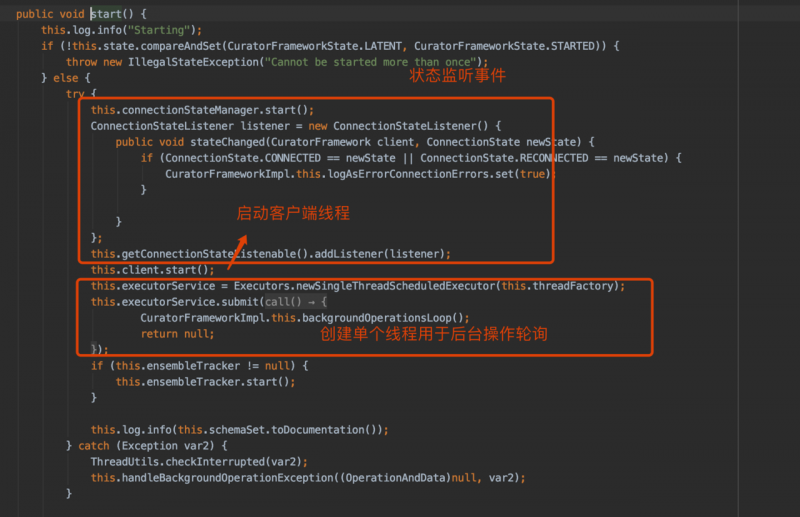
在client.start调用后,就会创建与zookeeper服务器之间的会话链接系统关闭时 会话就会断开
client.start 源码分析
启动日志
关闭日志

系统启动时zk的日志

系统关闭时zk的日志

访问多线程获取zk锁接口
curl http://127.0.0.1:8080/batch-acquire-lock查看zk锁情况

查看日志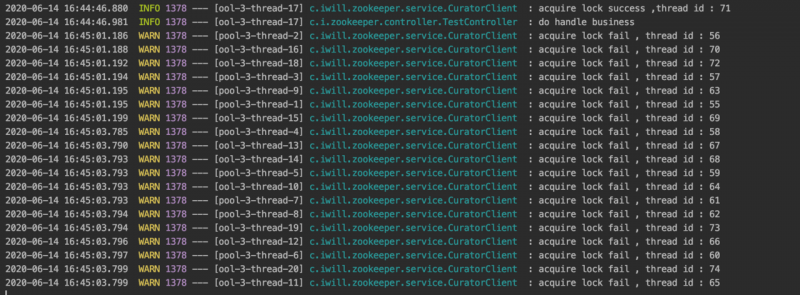
20个线程同时获取锁 会在/lock-path下面创建20个临时节点 序号从0-19 只有创建序号0的临时节点的那个线程才会成功获取得锁 其他的没有获取锁的临时节点会删除此时那个获得zk锁的线程如果使用锁完毕之后如果不释放锁 这个锁对应的临时节点还会存在

由此也会看出一个缺点临时会话顺序节点会被删除,但是它们的父节点/lock-path不会被删除。因此,高并发的业务场景下使用zookeeper分布式锁时,会留下很多的空节点
节点创建
跟踪lock.acquire(200, TimeUnit.MILLISECONDS)进入到org.apache.curator.framework.recipes.locks.StandardLockInternalsDriver#createsTheLock
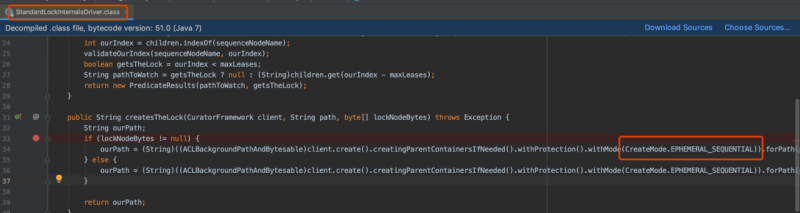
创建的节点为临时会话顺序节点(EPHEMERAL_SEQUENTIAL)即该节点会在客户端链接断开时被删除,还有,我们调用org.apache.curator.framework.recipes.locks.InterProcessMutex#release时也会删除该节点
可重入性
跟踪获取锁的代码进入到org.apache.curator.framework.recipes.locks.InterProcessMutex#internalLock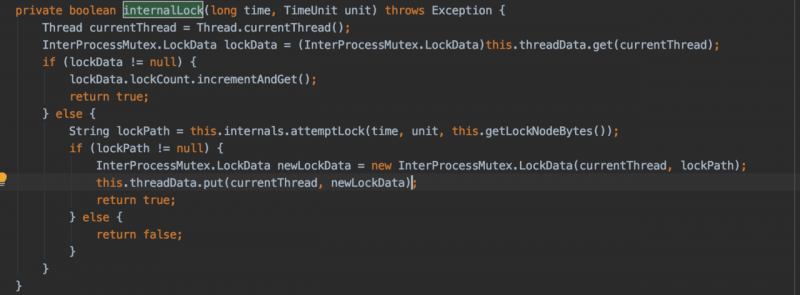
可以看见zookeeper的锁是可重入的,即同一个线程可以多次获取锁,只有第一次真正的去创建临时会话顺序节点,后面的获取锁都是对重入次数加1。相应的,在释放锁的时候,前面都是对锁的重入次数减1,只有最后一次才是真正的去删除节点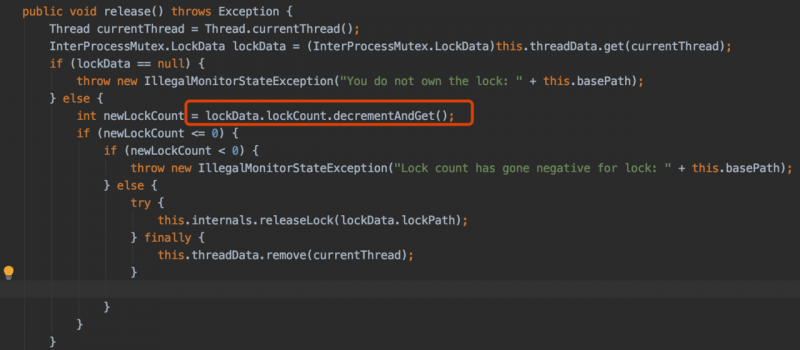
客户端故障检测:
正常情况下,客户端会在会话的有效期内,向服务器端发送PING 请求,来进行心跳检查,说明自己还是存活的。服务器端接收到客户端的请求后,会进行对应的客户端的会话激活,会话激活就会延长该会话的存活期。如果有会话一直没有激活,那么说明该客户端出问题了,服务器端的会话超时检测任务就会检查出那些一直没有被激活的与客户端的会话,然后进行清理,清理中有一步就是删除临时会话节点(包括临时会话顺序节点)。这就保证了zookeeper分布锁的容错性,不会因为客户端的意外退出,导致锁一直不释放,其他客户端获取不到锁。
数据一致性:
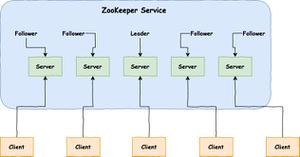
zookeeper服务器集群一般由一个leader节点和其他的follower节点组成,数据的读写都是在leader节点上进行。当一个写请求过来时,leader节点会发起一个proposal,待大多数follower节点都返回ack之后,再发起commit,待大多数follower节点都对这个proposal进行commit了,leader才会对客户端返回请求成功;如果之后leader挂掉了,那么由于zookeeper集群的leader选举算法采用zab协议保证数据最新的follower节点当选为新的leader,所以,新的leader节点上都会有原来leader节点上提交的所有数据。这样就保证了客户端请求数据的一致性了。
CAP:
任何分布式架构都不能同时满足C(一致性)、A(可用性)、P(分区耐受性),因此,zookeeper集群在保证一致性的同时,在A和P之间做了取舍,最终选择了P,因此可用性差一点。综上所述
zookeeper分布式锁保证了锁的容错性、一致性。但是会产生空闲节点(/lock-path),并且有些时候不可用。源码
https://gitee.com/pingfanrenbiji/distributed-lock/tree/master/zookeeper引用文章
https://my.oschina.net/yangjianzhou/blog/1930493https://www.jianshu.com/p/db65b64f38aa
本文使用 mdnice 排版
以上是 zookeeper分布式锁原理及实现 的全部内容, 来源链接: utcz.com/a/24623.html