基于 Web 端的人脸识别身份验证
效果展示

前言
近些年来,随着生物识别技术的逐渐成熟,基于深度学习的人脸识别技术取得了突破性进展,准确率显著提高。现阶段,人脸识别身份验证作为非常重要的身份验证方式,已被广泛的应用于诸多行业和领域,例如:支付宝付款、刷脸签到等方面。
其优点在于,以人脸为识别对象,识别过程更加友好、便捷,只需被识别者进入摄像范围内即可,不会引起被识别者的反感和警惕。目前,市面上的应用场景主要集中在移动端,而基于 Web 浏览器端的人脸识别身份验证方案较少。
本文将介绍基于 Web 浏览器端的人脸识别身份验证的整体方案,以及重点讲解如何在 Web 浏览器中实现人脸自动采集。
场景描述及分析
- 适用场景:人脸识别身份实名认证。用户使用人脸识别身份验证功能时,只需要将人脸对准摄像头,程序自动对人脸进行检测。如果检测到当前摄像头可视区域内仅存在唯一一个人脸,则采集当前人脸图片进行人脸对比、活体检测、身份证识别等多项组合能力,快速完成用户身份核验。
从上述场景描述中,分析出几个关键问题及解决方案:
问题一:如何获取到摄像头拍摄的实时视频流数据?
- 通过 navigator.mediaDevices.getUserMedia API(基于WebRTC )可以获取到摄像头拍摄的实时视频流数据
问题二:如何检测到实时视频流中存在唯一人脸,并进行采集?
- 使用开源的人脸采集 JS 库。需要支持单个和多个人脸检测
经横向对比目前常用的开源人脸采集 JS 库,Face-api.js 在性能和准确度上更胜一筹
face-api.js:基于 TensorFlow.js 内核,实现了三种卷积神经网络架构,用于完成人脸检测、识别和特征点检测任务,可以在浏览器中进行人脸识别。其内部实现了一个非常轻巧,快速,准确的 68 点面部标志探测器。支持多种 tf 模型,微小模型仅为 80kb。另外,它还支持 GPU 加速,相关操作可以使用 WebGL 运行
tracking.js : 一个独立的 JavaScript 库,主要实现了颜色和人(人脸、五官等)的跟踪检测。可以通过检测到某特定颜色,或者检测一个人体/脸的出现与移动,来触发 JavaScript 事件,然后对人脸进行采集。Tracking.js 是使用 CPU 进行计算的,在图像的矩阵运算效率上,相对 GPU 要慢一些
问题三:实名身份验证怎么实现?如何获取到身份证上的高清照片进行比对?
- 个人身份证上的高清照片是无法直接获取到的。可以使用 百度 AI 的实名身份认证服务,将待比对的人脸图片 + 身份证号码 + 姓名上传到百度 AI 服务,会返回图片的匹配度(0~100)。其底层调用的也是公安的实名认证接口
问题四:活体检测怎么实现?
- 考虑到 Web 端性能,活体检测交由服务端处理比较合适。具体可参考 百度 AI 活体检测
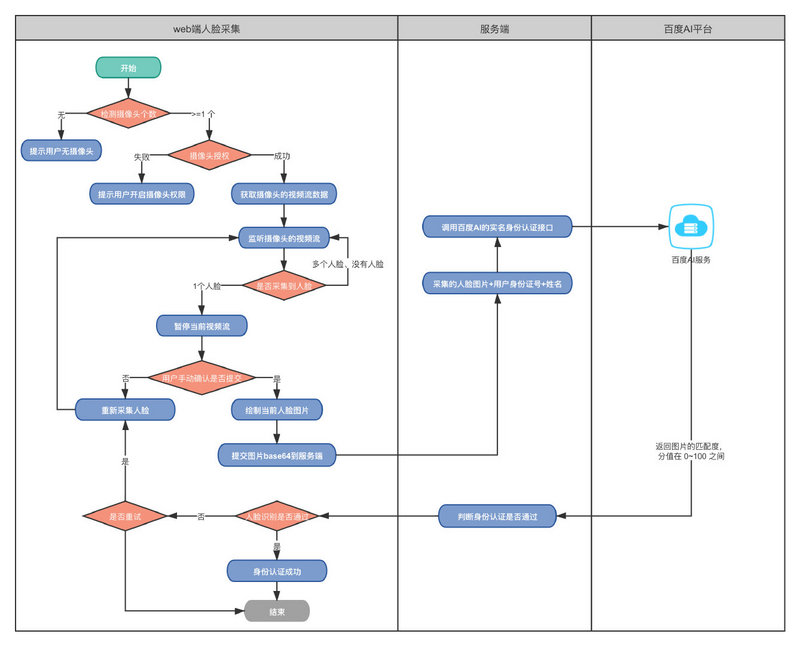
整体方案
主要分为以下几个关键步骤:
- 调用摄像头(需获得用户授权允许),获取摄像头的视频流数据
- 使用 face-api.js 识别视频流中的人脸特征点,定位出人脸的位置
- 符合人脸特征时,暂停视频流,根据视频流当前帧,绘制图像
- 将图像转成 Base64 编码,上传到服务端
- 服务端调用百度 AI 的接口,与身份证上的图片信息进行比对,并进行活体检测
实现细节
- 在上述方案中,想必大家对摄像头检测、实时视频流数据获取、Canvas 图片绘制这些都比较熟悉,我这边就不详细讲解了。部分同学没接触过也没关系,具体实现比较简单,可以直接看 源码,源码里面关于这些都有详细的注解。
- 下面我详细讲下,如何使用 face-api.js 在实时视频流中进行人脸的检测
1、 引入 face-api
script 标签方式,获取 最新脚本
<script></script>或者 使用 npm 方式
npm install face-api.js2、加载模型数据
// 加载所有模型数据,models 是存放模型数据文件的目录await faceapi.loadModels('/models');
// 加载单个指定的模型数据
await faceapi.loadTinyFaceDetectorModel('/models');
await faceapi.loadSsdMobilenetv1Model('/models');
await faceapi.loadMtcnnModel('/models');
3、检测人脸
- faceapi.detectAllFaces :检测图像中的所有人脸
- faceapi.detectSingleFace :检测单个人脸,返回图像中具有最高置信度得分的人脸
// 数据源支持:HTMLImageElement | HTMLVideoElement | HTMLCanvasElement 类型// 不同的模型有不同的配置参数,下面会详细介绍
const detections1 = await faceapi.detectAllFaces(待检测的数据源, 模型的配置参数);
const detections2 = await faceapi.detectSingleFace(待检测的数据源, 模型的配置参数);
4、常用人脸检测模型介绍
(1)Tiny Face Detector 是一款性能非常高的实时人脸检测模型,与 SSD Mobilenet V1 人脸检测模型相比,它更快,更小,资源消耗更少,量化模型的大小仅为 190 KB(tiny_face_detector_model),但它在检测小脸时的表现稍差。加载时长 8 ms左右
// 模型的配置参数new faceapi.TinyFaceDetectorOptions({
// 输入的数据源大小,这个值越小,处理速度越快。常用值:128, 160, 224, 320, 416, 512, 608
inputSize: number, // default: 416
// 用于过滤边界的分数阈值,大于等于这个值才被认为检测到了人脸,然后返回一个detection对象
scoreThreshold: number // default: 0.5
});
(2)SSD Mobilenet V1 对于面部检测,该模型实现了基于 MobileNetV1 的 SSD(单次多盒检测器)。神经网络将计算图像中每个面部的位置,并将返回边界框以及每个面部的概率。该面部检测器旨在获得检测面部边界框而不是低推理时间的高精度。量化模型的大小约为 5.4 MB(ssd_mobilenetv1_model)。加载时长 2-3 s左右
// 模型的配置参数new faceapi.SsdMobilenetv1Options({
// 最小置信值,大于等于这个值才被认为检测到了人脸,然后返回一个detection对象
minConfidence: number, // default: 0.5
// 最多返回人脸的个数
maxResults: number // default: 100
});
(3)MTCNN MTCNN(多任务级联卷积神经网络)代表了 SSD Mobilenet v1 和 Tiny Yolo v2 的替代面部检测模型,它提供了更多的配置空间。通过调整输入参数,MTCNN 应该能够检测各种面部边界框大小。MTCNN 是一个 3 级级联 CNN,它同时返回 5 个面部标志点以及每个面的边界框和分数。此外,型号尺寸仅为 2 MB。加载时长 1-2s 左右
// 模型的配置参数new faceapi.MtcnnOptions({
// 人脸尺寸的最小值,小于这个尺寸的人脸不会被检测到
minFaceSize: number, // default: 20
// 用于过滤边界的分数阈值,分别可以设置3个阶段盒子的阈值。scoreThresholds: number[], // default: [0.6, 0.7, 0.7]
// 比例因子用于计算图像的比例步长
scaleFactor: number, // default: 0.709
// 经过CNN的输入图像缩放版本的最大数量。数字越小,检测时间越短,但相对准确度会差一些。
maxNumScales: number, // default: 10
// 手动设置缩放步长 scaleSteps
scaleSteps?: number[],
});
特别说明:
- 模型的配置参数设置非常重要,需要慢慢的微调,能优化识别性能和比对的正确性
- 实测下来,Tiny Face Detector 模型的性能非常好,检测的准确度也不错,只有人脸很小的时候,会有较大偏差,scoreThreshold 阈值为 0.6 时最佳
注意事项
- 由于 Web 端的人脸识别强依赖于本地摄像头的唤起,因此,对于本地摄像头的调用需要进行详细的错误捕获和处理,以便明确的提示用户该如何操作。下面已枚举出所有可能出现的报错:
const errorMap = {'NotAllowedError': '摄像头已被禁用,请在系统设置或者浏览器设置中开启后重试',
'AbortError': '硬件问题,导致无法访问摄像头',
'NotFoundError': '未检测到可用摄像头',
'NotReadableError': '操作系统上某个硬件、浏览器或者网页层面发生错误,导致无法访问摄像头',
'OverConstrainedError': '未检测到可用摄像头',
'SecurityError': '摄像头已被禁用,请在系统设置或者浏览器设置中开启后重试',
'TypeError': '类型错误,未检测到可用摄像头'
};
await navigator.mediaDevices.getUserMedia({video: true})
.catch((error) => {
if (errorMap[error.name]) {
alert(errorMap[error.name]);
}
});
http 协议下,Chrome 浏览器无法调用本地摄像头
- Chrome 浏览器出于安全性的考虑,现只支持 HTTPS 协议 和 localhost 下,调用摄像头。HTTP 协议下是无法调用摄像头的。如果一定要在 HTTP下调用到摄像头,只能修改 Chrome 浏览器的配置项,但不建议这么做
源码获取
- 查看源码
扩展阅读
- 前端在人工智能时代能做些什么?
- TensorFlow.js 官方文档
- 在浏览器中进行深度学习:TensorFlow.js【系列文章】
- face-api.js
- tracking.js
招贤纳士
政采云前端团队(ZooTeam),一个年轻富有激情和创造力的前端团队,隶属于政采云产品研发部,Base 在风景如画的杭州。团队现有 50 余个前端小伙伴,平均年龄 27 岁,近 3 成是全栈工程师,妥妥的青年风暴团。成员构成既有来自于阿里、网易的“老”兵,也有浙大、中科大、杭电等校的应届新人。团队在日常的业务对接之外,还在物料体系、工程平台、搭建平台、性能体验、云端应用、数据分析及可视化等方向进行技术探索和实战,推动并落地了一系列的内部技术产品,持续探索前端技术体系的新边界。
如果你想改变一直被事折腾,希望开始能折腾事;如果你想改变一直被告诫需要多些想法,却无从破局;如果你想改变你有能力去做成那个结果,却不需要你;如果你想改变你想做成的事需要一个团队去支撑,但没你带人的位置;如果你想改变既定的节奏,将会是“5 年工作时间 3 年工作经验”;如果你想改变本来悟性不错,但总是有那一层窗户纸的模糊… 如果你相信相信的力量,相信平凡人能成就非凡事,相信能遇到更好的自己。如果你希望参与到随着业务腾飞的过程,亲手推动一个有着深入的业务理解、完善的技术体系、技术创造价值、影响力外溢的前端团队的成长历程,我觉得我们该聊聊。任何时间,等着你写点什么,发给 ZooTeam@cai-inc.com

以上是 基于 Web 端的人脸识别身份验证 的全部内容, 来源链接: utcz.com/a/24569.html