Dart处理Tcp中的粘包问题(utf8)
在tcp通信中,粘包是极其常见的事情.
下面我分享一个再实际开发的时候遇见的粘包问题,虽然它的实际触发场景不是tcp通信,但能应用于一些类似的粘包情况
由于我对计算机网路还没有过系统的学习,根据我看过的文献说一下我自己的理解
- 1.发送端没有对数据进行很好的分割
- 2.Tcp接收到的数据都存在缓冲区里面,由应用程序主动读取,而大部分的情况是,tcp收到的数据存在缓冲区的速度过快,导致一组完整数据的头部,粘到了前一组完整数据的尾部。或者在读取时,由于缓冲区的固定大小缘故,某一次读取的数据占满了缓冲区,可尾部的数据并不是完整的。
- tcp通信收发数据都是char的数组,在缓冲区的上限情况下,完全有可能发生粘包的情况
举个例子,'梦魇'对应的utf8编码为[230, 162, 166, 233, 173, 135]
使用
utf8.decode([230, 162, 166, 233, 173, 135]);即可获取'梦魇'二字,此时我们删掉最后一个数
utf8.decode([230, 162, 166, 233, 173]);那么这次转换一定会报错
Unfinished UTF-8 octet sequence (at offset 5)所以如果这一串编码在tcp中发生了粘包情况时,在一次数据接收并进行解码的过程中,如果尾部的数据只有一部分,那么对应这部分的解码会失败,从而下一次数据的开头也有着不规则的编码。
我的触发场景
来自于我上一篇Flutter开发的完整终端模拟器之后的维护,由于ptmx创建了一对虚拟终端对,所以我们的读写都是基于ptm设备,控制台的运行程序将自身的输出写进了pts,我们就能从ptm端拿到程序的输出。
大家平时开发的经验就知道,如果我们打开我们的终端模拟器,输入find /命令后,终端的输出不是简单的程序能避免从ptm读取数据不会粘包的,一瞬间可以说成千上万的输出到终端。
由于dart端是循环从ptm中读出程序的输出,它的速度是远远赶不上类似于find命令输出的速度的,最后就导致随便一两个命令就打断了我的运行调试,就是utf8解码时遇到了不规则序列,
我们也可以将allowMalformed参数写成true,utf8解码就不再丢错,但你的输出中就会有大量的'�'字符
所以本篇是解决tcp中utf8字符持续接收解码的场景
解决思路
根据编码的协议来进行拆包,拼包操作。我们只要将尾部不规则的编码拆出来存进缓存,并且在下一次数据到来的时候拼接到头部即可
所以关键难点就在于如何拆除不规则序列的尾部
查看编码规则
来自百度百科的UTF-8的相关内容
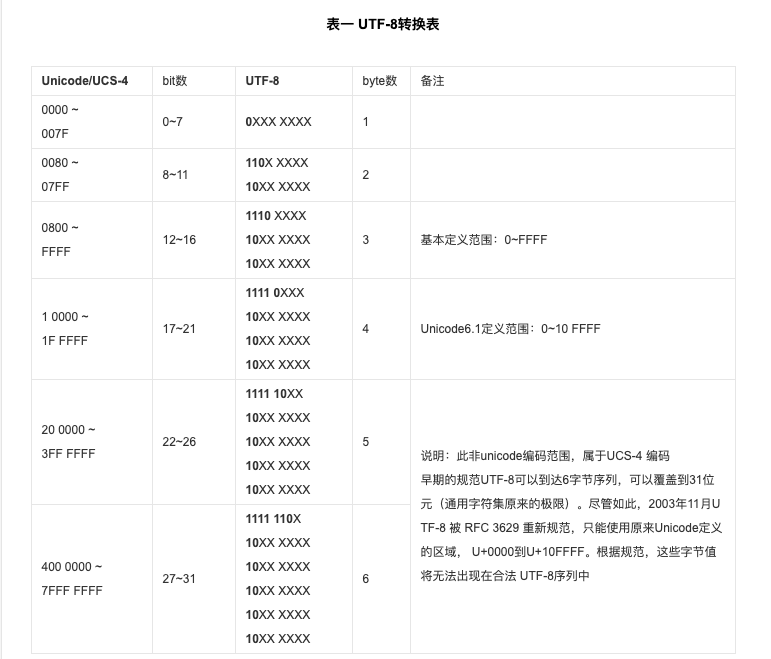
我们不需要关心它的完整编码规则,我们只需要找出它的规律
根据上图我们得出
任何字符转换成utf8序列后
- 第一个字节中1开头个数就代表了这一整组完整序列的字节数,包括这一个字节
- 剩余字节对应的二进制位总是以10开头
- 第一个范围Unicode对应编码的字节首位为0
得出检查算法🧐
我们选择从一次数据的尾部往前遍历
假定我们收到的数据放进名为units的列表
当Unicode范围在0000~007F的时候
由上面表格可知这个范围的Unicode值占用一个字节,并且是以首位为0
一个dart判定二进制是什么开头的小经验
不要使用int.toRadixString,因为当这个数对应二进制的首位不是1的时候,会被系统省略掉,所以我们要借助好语言中提供的移位,按位与,按位或等运算。
所以当
units.last & 128 == 0通过与128做按位与运算,具体如下:
1 0 0 0 0 0 0 0& x x x x x x x x
只要某个字节的首位不是0,那么与128做按位与运算得到的结果就是0
这种情况就代表这组序列的最后一个字节是完整的序列,不需要做处理
数据的最后一个字节是11开头
这是我自己的一种技巧吧
由于发现是字节对应的位11开头的话,就说明这个字节1开头的个数代表这整组序列的字节个数,如果最后一个字节有着代表个数的作用,那么它一定不属于这次数据,直接拆下来,扔进缓存,拼在下次的开头。
elseif (units.last & 192 == 192) {unitsCache = units.sublist(len - 1, len);
units.removeRange(len - 1, len);
192对应11000000
数据的最后一个字节为10开头
为10开头就会导致两种情况的存在
- 这组序列完整
- 不完整
haha废话了🤣
我们只需要从后往前遍历,记录下以10开头字节的个数,当遍历到11开头的字节时,对比11开头的字节中1的个数,是否是前面10开头的个数加1即可
例如某次数据
从后往前遍历发现5个10开头的字节,倒数第6个字节有6个1,那么尾部的这组序列就是完整,如果是7,就代表它还差一个字节的数据。
说了大半天
完整代码
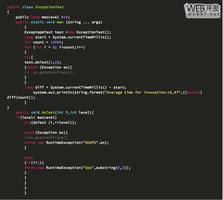
import 'dart:convert';import 'dart:ffi';
mixin CustomUtf {
static List<int> unitsCache = <int>[]; //这个缓存是为了解决拿到的最后字符不完整
static String cStringtoString(Pointer<Uint8> str) {
if (str == null) {
return null;
}
int len = 0;
while (str.elementAt(++len).value != 0) {}
List<int> units = List<int>(len);
for (int i = 0; i < len; ++i) {
units[i] = str.elementAt(i).value;
}
units = unitsCache + units;
// print('len=====$len');
len = len + unitsCache.length;
unitsCache.clear();
//只有当为0开头经过二进制转换才小于7位,如果读取到的最后一个字符为0开头,
//说明这整个UTF8字符占用1个字节,不存在后面还有其他字节没有读取到的情况
if (units.last & 128 == 0) {
// print('===>${units.last}');
try {
return utf8.decode(units, allowMalformed: false);
} catch (e) {
print(units);
print(e);
}
} elseif (units.last & 192 == 192) {
print('结尾数');
unitsCache = units.sublist(len - 1, len);
units.removeRange(len - 1, len);
} else {
// print('发现需要拼包的序列');
// print(units.last);
// print(units);
// print('拆包中');
int number = 0;
while (true) {
//等于2说明移位后为10
final int cur = units[len - 1 - number];
// print('当前指向的数===>$cur');
if (cur >> 6 == 2) {
// print('经过一个10');
//经过一次10开头的便记录一次
} elseif (cur.toRadixString(2).startsWith('1' * (number + 2))) {
//此时该字节以number+2个字节开始,说明该次读取不完整
//因为此时该字节开始的1应该为number+1个(10开始的个数加上此时这个字节)
unitsCache = units.sublist(len - number, len);
units.removeRange(len - number, len);
break;
} elseif (cur.toRadixString(2).startsWith('1' * (number+1))) {
{
break;
}
}
number++;
}
}
try {
return utf8.decode(units, allowMalformed: false);
} catch (e) {
print('===>$units');
print(e);
}
return null;
}
}
以上代码是用于将原生Pointer<Uint8>类型转为String并且能够应对大量字符传输过来时的粘包情况。
同步到我的个人博客
Dart处理Tcp中的粘包问题(utf8)
结语
之后的博文还是准备继续深入Flutter对标准终端模拟器的开发讲解,应该在考试后了。
文章主要分享主要是思想,可能听说过我的人都知道,我给的代码都是祖传的,使用没问题我就很少碰(没时间呀🤪 )
最近自己项目还有学校的事情忙得不开交,时刻记着学习呀。
小弟我各部分基础都还不扎实,只想借掘金分享自己的学习,帮助有同样需求的人,如有任何错误还恳请各位前辈不吝赐教,不能光想着职责我呀。
以上是 Dart处理Tcp中的粘包问题(utf8) 的全部内容, 来源链接: utcz.com/a/23299.html