
Java Review(三十六、IO)
@[Toc]
Java 的 IO 通过 java.io 包下的类和接口来支持, 在 java.io 包下主要包括输入、 输出两种 10 流, 每种输入、 输出流又可分为字节流和字符流两大类。 其中字节流以字节为单位来处理输入、 输出操作, 而字符流则以字符来处理输入、 输出操作。
File 类
Java的标准库java.io提供了File对象来操作文件和目录。
访问文件和目录
File 类可以使用文件路径字符串来创建 File 实例, 该文件路径字符串既可以是绝对路径, 也可以是相对路径。 在默认情况下, 系统总是依据用户的工作路径来解释相对路径。
创建了File对象后, 就可以调用 File 对象的方法来访问, File 类提供了很多方法来操作文件和目录, 下面列出一些比较常用的方法。
1、访问文件名相关的方法
- String getName(): 返回此 File 对象所表示的文件名或路径名( 如果是路径, 则返回最后一级子路径名)。
- String getPath(): 返回此 File 对象所对应的路径名。
- File getAbsoluteFile(): 返回此 Hie 对象的绝对路径。
- String getAbsolutePath(): 返回此 Hie 对象所对应的绝对路径名。
- String getParent(): 返回此 File 对象所对应目录( 最后一级子目录) 的父目录名。
- boolean renameTo(File newName): 重命名此 File 对象所对应的文件或目录, 如果重命名成功,则返回 true; 否则返回 false。
2. 文件检测相关的方法
- boolean exists(): 判断 File 对象所对应的文件或目录是否存在。
- boolean canWrite(): 判断 File 对象所对应的文件和目录是否可写。
- boolean canRead(): 判断 File 对象所对应的文件和目录是否可读。
- boolean isFile(): 判断 File 对象所对应的是否是文件, 而不是目录。
- boolean isDirectory(): 判断 File 对象所对应的是否是目录, 而不是文件。
- boolean isAbsolute(): 判断 Hie 对象所对应的文件或目录是否是绝对路径。 该方法消除了不同平台的差异, 可以直接判断 File 对象是否为绝对路径。 在 UNIX/Linux/BSD 等系统上, 如果路径名开头是一条斜线( /), 则表明该 File 对象对应一个绝对路径; 在 Windows 等系统上, 如果路径开头是盘符, 则说明它是一个绝对路径。
3. 获取常规文件信息
- long lastModified(): 返回文件的最后修改时间。
- long length(): 返回文件内容的长度。
4. 文件操作相关的方法
- boolean createNewFile(): 当此 File 对象所对应的文件不存在时, 该方法将新建一个该File对象所指定的新文件, 如果创建成功则返回 true; 否则返回 false。
- boolean delete(): 删除 Hie 对象所对应的文件或路径。
- static File createTempFile(String prefix,String suffix): 在默认的临时文件目录中创建一个临时的空文件, 使用给定前缀、 系统生成的随机数和给定后缀作为文件名。 这是一个静态方法,可以直接通过 File 类来调用。 prefix 参数必须至少是 3 字节长。 建议前缀使用一个短的、 有意义的字符串, 比如 "hjb” 或 ”mail”。 suffix 参数可以为 null, 在这种情况下, 将使用默认的后缀“.temp”。
- static File createTempFile(String prefix,String suffix,File directory): 在directory 所指定的目录中创建一个临时的空文件, 使用给定前缀、 系统生成的随机数和给定后缀作为文件名。 这是一个静态方法, 可以直接通过 File 类来调用。
- void deleteOnExit(): 注册一个删除钩子, 指定当 Java 虚拟机退出时, 删除 File 对象所对应的文件和目录。
5. 目录操作相关的方法
- boolean mkdir(): 试图创建一个 File 对象所对应的目录, 如果创建成功, 则返回 true; 否则返回 false。 调用该方法时 Hie 对象必须对应一个路径, 而不是一个文件。
- String[] list(): 列出 File 对象的所有子文件名和路径名, 返回 String 数组。
- File[] listFiles(): 列出 Hie 对象的所有子文件和路径, 返回 Hie 数组。
- static File[] listRoots(): 列出系统所有的根路径。 这是一个静态方法, 可以直接通过 Hie 类来调用。
面程序以几个简单方法来测试一下 File 类的功能:
import java.io.*;publicclassFileTest
{
publicstaticvoidmain(String[] args)
throws IOException
{
// 以当前路径来创建一个File对象
File file = new File(".");
// 直接获取文件名,输出一点
System.out.println(file.getName());
// 获取相对路径的父路径可能出错,下面代码输出null
System.out.println(file.getParent());
// 获取绝对路径
System.out.println(file.getAbsoluteFile());
// 获取上一级路径
System.out.println(file.getAbsoluteFile().getParent());
// 在当前路径下创建一个临时文件
File tmpFile = File.createTempFile("aaa", ".txt", file);
// 指定当JVM退出时删除该文件
tmpFile.deleteOnExit();
// 以系统当前时间作为新文件名来创建新文件
File newFile = new File(System.currentTimeMillis() + "");
System.out.println("newFile对象是否存在:" + newFile.exists());
// 以指定newFile对象来创建一个文件
newFile.createNewFile();
// 以newFile对象来创建一个目录,因为newFile已经存在,
// 所以下面方法返回false,即无法创建该目录
newFile.mkdir();
// 使用list()方法来列出当前路径下的所有文件和路径
String[] fileList = file.list();
System.out.println("====当前路径下所有文件和路径如下====");
for (String fileName : fileList)
{
System.out.println(fileName);
}
// listRoots()静态方法列出所有的磁盘根路径。
File[] roots = File.listRoots();
System.out.println("====系统所有根路径如下====");
for (File root : roots)
{
System.out.println(root);
}
}
}
API:java.io.File
文件过滤器
在 File 类的 list()方法中可以接收一个 FilenameFilter 参数, 通过该参数可以只列出符合条件的文件。
FilenameFilter 接口里包含了一个 accept(File dir,String name)方法, 该方法将依次对指定 File 的所有子目录或者文件进行迭代, 如果该方法返回 true, 则 list()方法会列出该子目录或者文件。
import java.io.*;publicclassFilenameFilterTest
{
publicstaticvoidmain(String[] args)
{
File file = new File(".");
// 使用Lambda表达式(目标类型为FilenameFilter)实现文件过滤器。
// 如果文件名以.java结尾,或者文件对应一个路径,返回true
String[] nameList = file.list((dir, name) -> name.endsWith(".java")
|| new File(name).isDirectory());
for(String name : nameList)
{
System.out.println(name);
}
}
}
IO流概览
流的分类
按照不同的分类方式, 可以将流分为不同的类型。
1. 输入流和输出流
按照流的流向来分, 可以分为输入流和输出流:
- 输入流: 只能从中读取数据, 而不能向其写入数据。
- 输出流: 只能向其写入数据, 而不能从中读取数据。
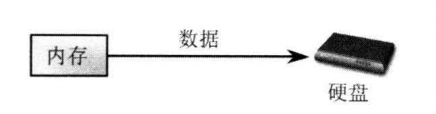
此处的输入、 输出涉及一个方向问题, 对于如图 1 所示的数据流向, 数据从内存到硬盘, 通常称为输出流——也就是说, 这里的输入、 输出都是从程序运行所在内存的角度来划分的。
图1:数据从内存到硬盘
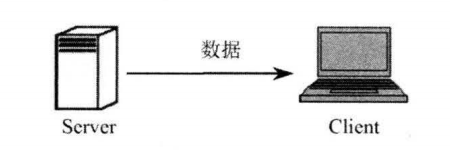
对于如图 2 所示的数据流向, 数据从服务器通过网络流向客户端, 在这种情况下, Server 端的内存负责将数据输出到网络里, 因此 Server 端的程序使用输出流; Client 端的内存负责从网络里读取数据, 因此 Client 端的程序应该使用输入流。
图2:数据从服务器到客户端
2. 字节流和字符流
字节流和字符流的用法几乎完全一样, 区别在于字节流和字符流所操作的数据单元不同操作的数据单元是 8 位的字节, 而字符流操作的数据单元是 16 位的字符。
3. 节点流和处理流
按照流的角色来分, 可以分为节点流和处理流。
可以从/向一个特定的IO设备( 如磁盘、 网络) 读/写数据的流, 称为节点流, 节点流也被称为低级流( Low Level Stream)。 图 3 显示了节点流示意图。
图3:节点流示意图
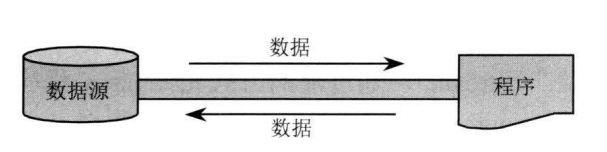
从图 3 中可以看出, 当使用节点流进行输入/输出时, 程序直接连接到实际的数据源, 和实际的输入/输出节点连接。
处理流则用于对一个己存在的流进行连接或封装, 通过封装后的流来实现数据读/写功能。 处理流也被称为高级流。 图 4 显示了处理流示意图。
图4:处理流示意图
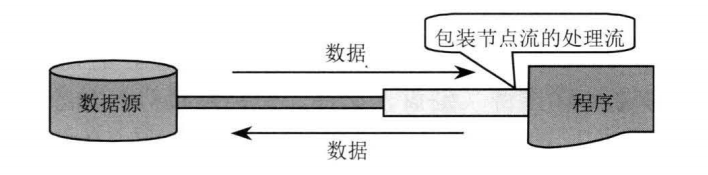
从图 4 中可以看出, 当使用处理流进行输入/输出时, 程序并不会直接连接到实际的数据源, 没有和实际的输入/输出节点连接。 使用处理流的一个明显好处是, 只要使用相同的处理流, 程序就可以采用完全相同的输入/输出代码来访问不同的数据源, 随着处理流所包装节点流的变化, 程序实际所访问的数据源也相应地发生变化。
流的概念模型
ava 把所有设备里的有序数据抽象成流模型, 简化了输入/输出处理, 理解了流的概念模型也就了解了Java IO。
Java 的 IO流的 40 多个类都是从如下 4 个抽象基类派生的:
- InputStream/Reader: 所有输入流的基类, 前者是字节输入流, 后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类, 前者是字节输出流, 后者是字符输出流。
通过使用处理流, Java 程序无须理会输入/输出节点是磁盘、 网络还是其他的输入/输出设备, 程序只要将这些节点流包装成处理流, 就可以使用相同的输入/输出代码来读写不同的输入/输出设备的数据。
图5:输入流模型图
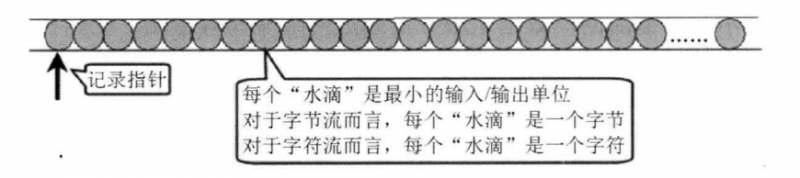
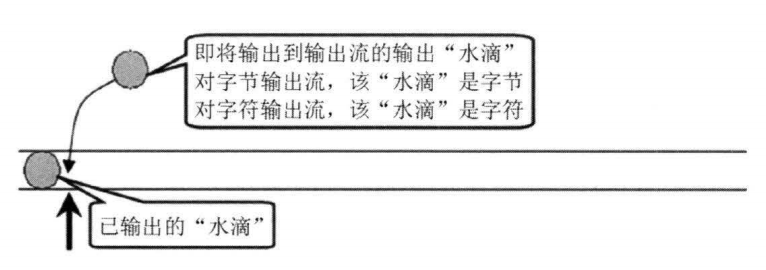
图6:输出流模型图
字节流和字符流
节流和字符流放的操作方式几乎完全一样, 区别只是操作的数据单元不同。
InputStream 和 Reader
InputStream 和 Reader 是所有输入流的抽象基类, 本身并不能创建实例来执行输入, 但它们是所有输入流的模板, 所以它们的方法是所有输入流都可使用的方法。
在 InputStream 里包含如下三个方法:
- int read(): 从输入流中读取单个字节( 相当于从图 5 所示的水管中取出一滴水), 返回所读取的字节数据( 字节数据可直接转换为 int 类型)。
- int read(byte[] b): 从输入流中最多读取 b.length 个字节的数据, 并将其存储在字节数组 b 中,返回实际读取的字节数。
- int read(byte[]b,int off,int len): 从输入流中最多读取 len 个字节的数据, 并将其存储在数组 b中, 放入数组 b 中时, 并不是从数组起点幵始, 而是从 uff 位置开始, 返回实际读取的字节数。
在 Reader 里包含如下三个方法:
- int read(): 从输入流中读取单个字符( 相当于从图 5 所示的水管中取出一滴水), 返回所读取的字符数据( 字符数据可直接转换为 int 类型)。
- int read(char[] cbuf): 从输入流中最多读取 cbuf.length 个字符的数据, 并将其存储在字符数组cbuf 中, 返回实际读取的字符数。
- int read(char[]cbuf,int off,int len): 从输入流中最多读取 len 个字符的数据, 并将其存储在字符数组 cbuf 中, 放入数组 cbuf 中时, 并不是从数组起点开始, 而是从 off 位置开始, 返回实际读取的字符数。
InputStream 和 Reader 都是抽象类, 本身不能创建实例, 但它们分别有一个用于读取文件的输入流: FilelnputStream 和 FileReader, 它们都是节点流—会直接和指定文件关联。
下面程序为 FilelnputStream 来读取自身的效果实例:
import java.io.*;publicclassFileInputStreamTest
{
publicstaticvoidmain(String[] args)throws IOException
{
// 创建字节输入流
FileInputStream fis = new FileInputStream(
"FileInputStreamTest.java");
// 创建一个长度为1024的“竹筒”
byte[] bbuf = newbyte[1024];
// 用于保存实际读取的字节数
int hasRead = 0;
// 使用循环来重复“取水”过程
while ((hasRead = fis.read(bbuf)) > 0 )
{
// 取出“竹筒”中水滴(字节),将字节数组转换成字符串输入!
System.out.print(new String(bbuf , 0 , hasRead ));
}
// 关闭文件输入流,放在finally块里更安全
fis.close();
}
}
FileReader 来读取文件本身实例:
FileReaderTest.java
import java.io.*;publicclassFileReaderTest
{
publicstaticvoidmain(String[] args)
{
try(
// 创建字符输入流
FileReader fr = new FileReader("FileReaderTest.java"))
{
// 创建一个长度为32的“竹筒”
char[] cbuf = newchar[32];
// 用于保存实际读取的字符数
int hasRead = 0;
// 使用循环来重复“取水”过程
while ((hasRead = fr.read(cbuf)) > 0 )
{
// 取出“竹筒”中水滴(字符),将字符数组转换成字符串输入!
System.out.print(new String(cbuf , 0 , hasRead));
}
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
API:java.io.InputStream
API:java.io.FilterInputStream
API:java.io.Reader
API:java.io.FileReader
OutputStream 和 Writer
OntputStream 和 Writer 也非常相似, 它们采用如图 6 所示的模型来执行输出, 两个流都提供了如下三个方法:
- void write(int c): 将指定的字节/字符输出到输出流中, 其中 c 既可以代表字节, 也可以代表字符。
- void write(byte[]/char[] buf): 将字节数组/字符数组中的数据输出到指定输出流中。
- void write(byte[]/char[] buf,int off,int len): 将字节数组/字符数组中从 off 位置开始, 长度为 len的字节/字符输出到输出流中。
因为字符流直接以字符作为操作单位, 所以 Writer 可以用字符串来代替字符数组, 即以 String 对象作为参数。 Writer 里还包含如下两个方法:
- void write(String str): 将 str 字符串里包含的字符输出到指定输出流中。
- void write(String str,int off,int len): 将 str 字符串里从 off 位置开始, 长度为 len 的字符输出到指定输出流中。
下面程序使用 FilelnputStream 来执行输入, 并使用 FileOutputStream 来执行输出, 用以实现复制FileOutputStreamTest.java 文件的功能。
import java.io.*;publicclassFileOutputStreamTest
{
publicstaticvoidmain(String[] args)
{
try(
// 创建字节输入流
FileInputStream fis = new FileInputStream(
"FileOutputStreamTest.java");
// 创建字节输出流
FileOutputStream fos = new FileOutputStream("newFile.txt"))
{
byte[] bbuf = newbyte[32];
int hasRead = 0;
// 循环从输入流中取出数据
while ((hasRead = fis.read(bbuf)) > 0 )
{
// 每读取一次,即写入文件输出流,读了多少,就写多少。
fos.write(bbuf , 0 , hasRead);
}
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}
使用 Java 的 10 流执行输出时, 不要忘记关闭输出流, 关闭输出流除可以保证流的物 理资源被回收之外, 可能还可以将输出流缓冲区中的数据 flush 到物理节点里 ( 因为在执行 close()方法之前, 自动执行输出流的 flush()方法 )。
如果希望直接输出字符串内容, 则使用 Writer 会有更好的效果:
FileWriterTest.java
import java.io.*;publicclassFileWriterTest
{
publicstaticvoidmain(String[] args)
{
try(
FileWriter fw = new FileWriter("poem.txt"))
{
fw.write("锦瑟 - 李商隐rn");
fw.write("锦瑟无端五十弦,一弦一柱思华年。rn");
fw.write("庄生晓梦迷蝴蝶,望帝春心托杜鹃。rn");
fw.write("沧海月明珠有泪,蓝田日暖玉生烟。rn");
fw.write("此情可待成追忆,只是当时已惘然。rn");
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}
API:java.io.OutputStream
API:java.io.FileOutputStream
API:java.io.Writer
API:java.io.FilterWriter
输入/输岀流体系
Java 的输入/输出流体系提供了近 40 个类, 这些类看上去杂乱而没有规律, 但如果将其按功能进行分类, 则不难发现其是非常规律的。 表 1 显示了 Java 输入/输出流体系中常用的流分类。
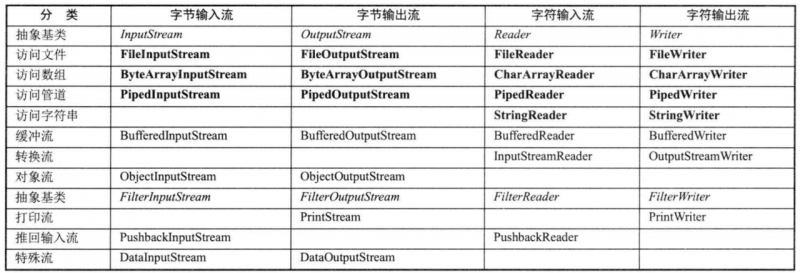
从表 1 中可以看出, Java 的输入/输出流体系之所以如此复杂, 主要是因为 Java 为了实现更好的设计, 它把 IO流按功能分成了许多类, 而每类中又分别提供了字节流和字符流( 当然有些流无法提供字节流, 有些流无法提供字符流), 字节流和字符流里又分别提供了输入流和输出流两大类, 所以导致整个输入/输出流体系格外复杂。
图7:Java 输入/输出流体系思维导图
通常来说, 字节流的功能比字符流的功能强大, 因为计算机里所有的数据都是二进制的, 而字节流可以处理所有的二进制文件—但问题是, 如果使用字节流来处理文本文件, 则需要使用合适的方式把这些字节转换成字符, 这就增加了编程的复杂度。 所以通常有一个规则: 如果进行输入/输出的内容是文本内容, 则应该考虑使用字符流; 如果进行输入/输出的内容是二进制内容, 则应该考虑使用字节流。
图8:Java 输入/输出流继承结构
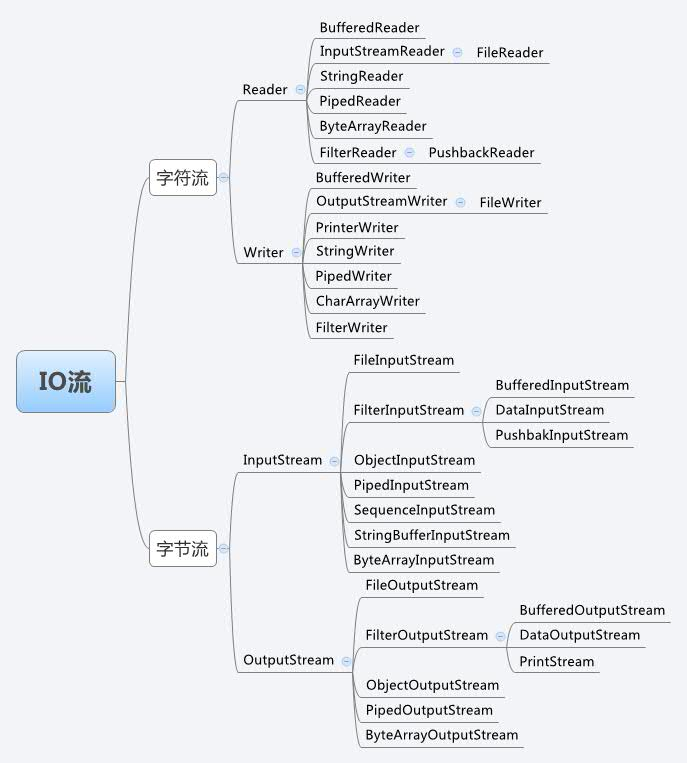
表 1 仅仅总结了输入/输出流体系中位于 java.io 包下的流, 还有一些诸如 AudioInputStream、CipherlnputStream、 DeflaterlnputStream、ZipInputStream 等具有访问音频文件、 加密/解密、 压缩/解压等功能的字节流, 它们具有特殊的功能, 位于 JDK 的其他包下。
处理流
4 个基类使用起来有些烦琐。 如果希望简化编程, 可以借助于处理流。
下面程序使用 PrintStream 处理流来包装 OutputStream, 使用处理流后的输出流在输出时将更加方便。
PrintStreamTest.java
import java.io.*;publicclassPrintStreamTest
{
publicstaticvoidmain(String[] args)
{
try(
FileOutputStream fos = new FileOutputStream("test.txt");
PrintStream ps = new PrintStream(fos))
{
// 使用PrintStream执行输出
ps.println("普通字符串");
// 直接使用PrintStream输出对象
ps.println(new PrintStreamTest());
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}
上面程序中先定义了一个节点输出流 FileOutputStream, 然 后程序使用PrintStream 包装了该节点输出流, 最后使用 PrintStream 输出字符串、 输出对象……
PrintStream 的输出功能非常强大, 前面程序中一直使用的标准输出 System.out 的类型就是 PrintStream。
程序使用处理流, 通常只需要在创建处理流时传入一个节点流作为构造器参数即可, 这样创建的处理流就是包装了该节点流的处理流。
API:java.io.PrintStream
转换流
输入/输出流体系中还提供了两个转换流, 这两个转换流用于实现将字节流转换成字符流, 其中InputStreamReader 将字节输入流转换成字符输入流, OutputStreamWriter 将字节输出流转换成字符输出流。
下面以获取键盘输入为例来介绍转换流的用法。 Java 使用 System.in 代表标准输入, 即键盘输入,但这个标准输入流是 InputStream 类的实例, 使用不太方便, 而且键盘输入内容都是文本内容, 所以可以使用 InputStreamReader 将其转换成字符输入流, 普通的 Reader 读取输入内容时依然不太方便, 可以将普通的 Reader 再次包装成 BufferedReader, 利用 BufferedReader 的 readLine()方法可以一次读取一行内容。
如下程序所示:
import java.io.*;publicclassKeyinTest
{
publicstaticvoidmain(String[] args)
{
try(
// 将Sytem.in对象转换成Reader对象
InputStreamReader reader = new InputStreamReader(System.in);
// 将普通Reader包装成BufferedReader
BufferedReader br = new BufferedReader(reader))
{
String line = null;
// 采用循环方式来一行一行的读取
while ((line = br.readLine()) != null)
{
// 如果读取的字符串为"exit",程序退出
if (line.equals("exit"))
{
System.exit(1);
}
// 打印读取的内容
System.out.println("输入内容为:" + line);
}
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}
API:java.io.InputStreamReader
API:java.io.InputStreamWriter
对象序列化
对象序列化的目标是将对象保存到磁盘中, 或允许在网络中直接传输对象。 对象序列化机制允许把内存中的 Java 对象转换成平台无关的二进制流, 从而允许把这种二进制流持久地保存在磁盘上, 通过网络将这种二进制流传输到另一个网络节点。 其他程序一旦获得了这种二进制流( 无论是从磁盘中获取的, 还是通过网络获取的), 都可以将这种二进制流恢复成原来的 Java 对象。
序列化的含义和意义
序列化机制允许将实现序列化的 Java 对象转换成字节序列, 这些字节序列可以保存在磁盘上, 或通过网络传输, 以备以后重新恢复成原来的对象。 序列化机制使得对象可以脱离程序的运行而独立存在。
对象的序列化 ( Serialize ) 指将一个 Java 对象写入 IO流中, 与此对应的是, 对象的反序列化(Deserialize) 则指从 IO 流中恢复该 Java 对象。
如果需要让某个对象支持序列化机制, 则必须让它的类是可序列化的 (serializable )o 为了让某个
类是可序列化的, 该类必须实现如下两个接口之一。
- Serializable
- Extemalizable
Java 的很多类己经实现了 Serializable, 该接口是一个标记接口, 实现该接口无须实现任何方法, 它只是表明该类的实例是可序列化的。
所有可能在网络上传输的对象的类都应该是可序列化的, 否则程序将会出现异常, 比如 RMI( Remote Method Invoke, 即远程方法调用, 是 Java EE 的基础) 过程中的参数和返回值; 所有需要保存到磁盘里的对象的类都必须可序列化, 比如 Web 应用中需要保存到 HttpSession 或 ServletContext 属性的 Java 对象。
因为序列化是 RMI 过程的参数和返回值都必须实现的机制, 而 RMI 又是 Java EE 技术的基础——所有的分布式应用常常需要跨平台、 跨网络, 所以要求所有传递的参数、 返回值必须实现序列化。 因此序列化机制是 Java EE 平台的基础。 通常建议: 程序创建的每个 JavaBean 类都实现 Serializable。
使用对象流实现序列化
使用 Serializable 来实现序列化, 只需要让目标类实现 Serializable 标记接口即可, 无须实现任何方法。
一旦某个类实现了 Serializable 接口, 该类的对象就是可序列化的, 程序可以通过如下两个步骤来序列化该对象。
- 创建一个 ObjectOutputStream, 这个输出流是一个处理流, 所以必须建立在其他节点流的基础之上。 如下代码所示:
// 创建一个 ObjectlnputStream 输入流ObjectlnputStream ois =new ObjectlnputStream(
new FilelnputStream("object.txt"));
- 调用 ObjectInputStream 对象的 readObject()方法读取流中的对象, 该方法返回一个 Object 类型的 Java 对象, 如果程序知道该 Java 对象的类型, 则可以将该对象强制类型转换成其真实的类型。 如下代码所示:
// 从输入流中读取一个 Java 对象, 并将其强制类型转换为 Person 类Person p(Person)ois.readObject();
下面程序定义了一个 Person 类, 这个 Person 类就是一个普通的 Java 类, 只是实现了 Serializable接口, 该接口标识该类的对象是可序列化的。
publicclassPerson
implementsjava.io.Serializable
{
private String name;
privateint age;
// 注意此处没有提供无参数的构造器!
publicPerson(String name , int age)
{
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
// 省略name与age的setter和getter方法
// name的setter和getter方法
publicvoidsetName(String name)
{
this.name = name;
}
public String getName()
{
returnthis.name;
}
// age的setter和getter方法
publicvoidsetAge(int age)
{
this.age = age;
}
publicintgetAge()
{
returnthis.age;
}
}
下面程序使用 ObjectOutputStream 将一个 Person 对象写入磁盘文件:
import java.io.*;publicclassWriteObject
{
publicstaticvoidmain(String[] args)
{
try(
// 创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("object.txt")))
{
Person per = new Person("孙悟空", 500);
// 将per对象写入输出流
oos.writeObject(per);
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
运行上面程序, 将会看到生成了一个 object.txt 文件, 该文件的内容就是Person 对象。
如果希望从二进制流中恢复 Java 对象, 则需要使用反序列化。 反序列化的步骤如下:
- 创建一个 ObjectlnputStream 输入流, 这个输入流是一个处理流, 所以必须建立在其他节点流的基础之上。 如下代码所示:
/ / 创建一个 ObjectlnputStream 输入流ObjectlnputStream ois =new ObjectlnputStream(
new FilelnputStream("object.txt"));
- 调用 ObjectInputStream 对象的 readObject()方法读取流中的对象, 该方法返回一个 Object 类型的 Java 对象, 如果程序知道该 Java 对象的类型, 则可以将该对象强制类型转换成其真实的类型。 如下代码所示:
// 从输入流中读取一个 Java 对象, 并将其强制类型转换为 Person 类Person p(Person)ois.readObject();
下面程序从刚刚生成的 object.txt 文件中读取 Person 对象:
import java.io.*;publicclassReadObject
{
publicstaticvoidmain(String[] args)
{
try(
// 创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("object.txt")))
{
// 从输入流中读取一个Java对象,并将其强制类型转换为Person类
Person p = (Person)ois.readObject();
System.out.println("名字为:" + p.getName()
+ "n年龄为:" + p.getAge());
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
反序列化读取的仅仅是 Java 对象的数据, 而不是 Java 类, 因此采用反序列化恢复Java 对象时, 必须提供该 Java 对象所属类的 class 文件, 否则将会引发 ClassNotFoundException 异常。
对象引用的序列化
Person 类的两个成员变量分别是 String 类型和 int 类型, 如果某个类的成员变量的类型不是基本类型或 String 类型, 而是另一个引用类型, 那么这个引用类必须是可序列化的, 否则拥有该类型成员变量的类也是不可序列化的。
如下 Teacher 类持有一个 Person 类的引用, 只有 Person 类是可序列化的,Teacher 类才是可序列化的。 如果 Person 类不可序列化, 则无论 Teacher 类是否实现 Serilizable、 Extemalizable 接口, 则 Teacher类都是不可序列化的。
publicclassTeacherimplementsjava.io.Serializable
{private String name;
private Person student;
publicTeacher(String name , Person student)
{
this.name = name;
this.student = student;
}
// 此处省略了name和student的setter和getter方法
……
}
Java 序列化机制采用了一种特殊的序列化算法, 其算法内容如下:
- 所有保存到磁盘中的对象都有一个序列化编号。
- 当程序试图序列化一个对象时, 程序将先检查该对象是否己经被序列化过, 只有该对象从未(在本次虚拟机中) 被序列化过, 系统才会将该对象转换成字节序列并输出。
- 如果某个对象已经序列化过, 程序将只是直接输出一个序列化编号, 而不是再次重新序列化该对象。
下面程序序列化了两个 Teacher 对象, 两个 Teacher对象都持有一个引用到同一个 Person 对象的引用, 而且程序两次调用 writeObject()方法输出同一Teacher 对象。
import java.io.*;publicclassWriteTeacher
{
publicstaticvoidmain(String[] args)
{
try(
// 创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("teacher.txt")))
{
Person per = new Person("孙悟空", 500);
Teacher t1 = new Teacher("唐僧" , per);
Teacher t2 = new Teacher("菩提祖师" , per);
// 依次将四个对象写入输出流
oos.writeObject(t1);
oos.writeObject(t2);
oos.writeObject(per);
oos.writeObject(t2);
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
上面程序中的粗体字代码 4 次调用了 writeObject()方法来输出对象, 实际上只序列化了三个对象,而且序列的两个 Teacher 对象的 student 引用实际是同一个 Person 对象。 下面程序读取序列化文件中的对象即可证明这一点:
import java.io.*;publicclassSerializeMutable
{
publicstaticvoidmain(String[] args)
{
try(
// 创建一个ObjectOutputStream输入流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("mutable.txt"));
// 创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("mutable.txt")))
{
Person per = new Person("孙悟空", 500);
// 系统会per对象转换字节序列并输出
oos.writeObject(per);
// 改变per对象的name实例变量
per.setName("猪八戒");
// 系统只是输出序列化编号,所以改变后的name不会被序列化
oos.writeObject(per);
Person p1 = (Person)ois.readObject(); //①
Person p2 = (Person)ois.readObject(); //②
// 下面输出true,即反序列化后p1等于p2
System.out.println(p1 == p2);
// 下面依然看到输出"孙悟空",即改变后的实例变量没有被序列化
System.out.println(p2.getName());
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
自定义序列化
在一些特殊的场景下, 如果一个类里包含的某些实例变量是敏感信息, 例如银行账户信息等, 这时不希望系统将该实例变量值进行序列化; 或者某个实例变量的类型是不可序列化的, 因此不希望对该实例变量进行递归序列化, 以避免引发 java.io.NotSerializableException 异常。
通过在实例变量前面使用 transient 关键字修饰, 可以指定 Java 序列化时无须理会该实例变量。 如下 Person 类与前面的 Person 类几乎完全一样, 只是它的 age 使用了 transient 关键字修饰。
publicclassPersonimplementsjava.io.Serializable
{private String name;
privatetransientint age;
// 注意此处没有提供无参数的构造器!
publicPerson(String name , int age)
{
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
// 省略name与age的setter和getter方法
……
}
下面程序先序列化一个 Person 对象, 然后再反序列化该 Person 对象, 得到反序列化的 Person 对象后程序输出该对象的 age 实例变量值:
import java.io.*;publicclassTransientTest
{
publicstaticvoidmain(String[] args)
{
try(
// 创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("transient.txt"));
// 创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("transient.txt")))
{
Person per = new Person("孙悟空", 500);
// 系统会per对象转换字节序列并输出
oos.writeObject(per);
Person p = (Person)ois.readObject();
//age实例变量使用 transient 关键字修饰, 所以输出 0
System.out.println(p.getAge());
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
使用 transient 关键字修饰实例变量虽然简单、 方便, 但被 transient 修饰的实例变量将被完全隔离在序列化机制之外, 这样导致在反序列化恢复 Java 对象时无法取得该实例变量值。 Java 还提供了一种自定义序列化机制, 通过这种自定义序列化机制可以让程序控制如何序列化各实例变量, 甚至完全不序列化某些实例变量( 与使用 transient 关键字的效果相同)。
在序列化和反序列化过程中需要特殊处理的类应该提供如下特殊签名的方法, 这些特殊的方法用以实现自定义序列化。
- private void writeObject(java.io.ObjectOutputStream out)throws IOException
- private void readObject(java.io.ObjectInputStream in)throws IOException, ClassNotFoundExccption;
- private void readObjectNoData()throws ObjectStreamException;
- writeObject()方法负责写入特定类的实例状态, 以便相应的 readObject()方法可以恢复它。 通过重写该方法, 程序员可以完全获得对序列化机制的控制, 可以自主决定哪些实例变量需要序列化, 需要怎样序列化。 在默认情况下, 该方法会调用 out.defaultWriteObject 来保存 Java 对象的各实例变量, 从而可以实现序列化 Java 对象状态的目的。
- readObject()方法负责从流中读取并恢复对象实例变量, 通过重写该方法, 程序员可以完全获得对反序列化机制的控制, 可以自主决定需要反序列化哪些实例变量, 以及如何进行反序列化。 在默认情况下, 该方法会调用in.defaultReadObject 来恢复 Java 对象的非瞬态实例变量。 在通常情况下, readObject()方法与 writeObject()方法对应, 如果 writeObject()方法中对 Java 对象的实例变量进行了一些处理, 则应该在 readObjectO方法中对其实例变量进行相应的反处理, 以便正确恢复该对象。
- 当序列化流不完整时, readObjectNoData()方法可以用来正确地初始化反序列化的对象。 例如, 接收方使用的反序列化类的版本不同于发送方, 或者接收方版本扩展的类不是发送方版本扩展的类, 或者序列化流被篡改时, 系统都会调用 readObjectNoData()方法来初始化反序列化的对象。
下面的 Person 类提供了 writeObject()和 readObject()两个方法, 其中 writeObject()方法在保存 Person对象时将其name 实例变量包装成 StringBuffer, 并将其字符序列反转后写入;在 readObjectO方法中处理 name 的策略与此对应 先将读取的数据强制类型转换成 StringBuffer, 再将其反转后赋给例变量。
import java.io.*;publicclassPerson
implementsjava.io.Serializable
{
private String name;
privateint age;
// 注意此处没有提供无参数的构造器!
publicPerson(String name , int age)
{
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
// 省略name与age的setter和getter方法
……
privatevoidwriteObject(java.io.ObjectOutputStream out)
throws IOException
{
// 将name实例变量的值反转后写入二进制流
out.writeObject(new StringBuffer(name).reverse());
out.writeInt(age);
}
privatevoidreadObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException
{
// 将读取的字符串反转后赋给name实例变量
this.name = ((StringBuffer)in.readObject()).reverse()
.toString();
this.age = in.readInt();
}
}
对于这个 Person 类而言, 序列化、 反序列化 Person 实例并没有任何区别—区别在于序列化后的对象流, 即使有 Cracker 截获到 Person 对象流,他看到的 name 也是加密后的 name 值, 这样就提高序列化的安全性。
还有一种更彻底的自定义机制,它甚至可以在序列化对象时将该对象替换成其他对象。如果需要实 。现序列化某个对象时替换该对象, 则应为序列化类提供如下特殊方法:
ANY-ACCESS-MODIFIER Object writeReplace()throws ObjectStreamException;此 writeReplaceO方法将由序列化机制调用, 只要该方法存在。 因为该方法可以拥有私有( private )、受保护的 ( protected) 和 包 私 有 ( package-private) 等访问权限, 所以其子类有可能获得该方法。 例如,下面的 Person 类提供了 writeReplace()方法, 这样可以在写入 Person 对象时将该对象替换成 ArrayList。
import java.util.*;import java.io.*;
publicclassPerson
implementsjava.io.Serializable
{
private String name;
privateint age;
// 注意此处没有提供无参数的构造器!
publicPerson(String name , int age)
{
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
// 省略name与age的setter和getter方法
……
// 重写writeReplace方法,程序在序列化该对象之前,先调用该方法
private Object writeReplace()throws ObjectStreamException
{
ArrayList<Object> list = new ArrayList<>();
list.add(name);
list.add(age);
return list;
}
}
Java 的序列化机制保证在序列化某个对象之前, 先调用该对象的writeReplaceO方法, 如果该方法返回另一个 Java 对象, 则系统转为序列化另一个对象。 如下程序表面上是序列化 Person 对象, 但实际上序列化的是 ArrayList:
import java.io.*;import java.util.*;
publicclassReplaceTest
{
publicstaticvoidmain(String[] args)
{
try(
// 创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("replace.txt"));
// 创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("replace.txt")))
{
Person per = new Person("孙悟空", 500);
// 系统将per对象转换字节序列并输出
oos.writeObject(per);
// 反序列化读取得到的是ArrayList
ArrayList list = (ArrayList)ois.readObject();
System.out.println(list);
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
与 writeReplace()方法相对的是, 序列化机制里还有一个特殊的方法, 它可以实现保护性复制整个对象。 这个方法就是:
ANY-ACCESS-MODIFIER Object readResolve()throws ObjectStreamException;这个方法会紧接着 readObject()之后被调用, 该方法的返回值将会代替原来反序列化的对象, 而原来 readObject()反序列化的对象将会被立即丢弃。
NIO
从 JDK 1.4 开始, Java 提供了一系列改进的输入/输出处理的新功能, 这些功能被统称为新 IO ( New IO, 简称 NIO), 新增了许多用于处理输入/输出的类, 这些类都被放在 java.nio 包以及子包下, 并且对原 java.io 包中的很多类都以 NI0 为基础进行了改写, 新增了满足 NI0 的功能。
新 IO 和传统的IO有相同的目的, 都是用于进行输入/输出, 但新 IO 使用了不同的方式来处理输入/输出, 新 IO 采用内存映射文件的方式来处理输入/输出, 新 IO 将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样来访问文件了( 这种方式模拟了操作系统上的虚拟内存的概念), 通过这种方式来进行输入/输出比传统的输入/输出要快得多。
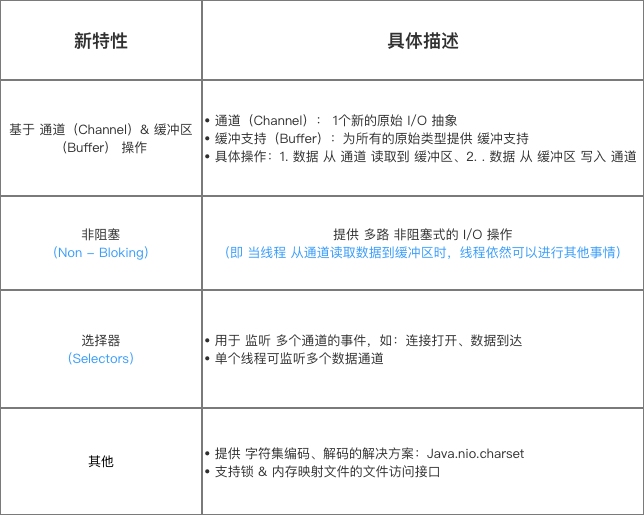
Java 中与新 IO 相关的包如下:
- java.nio 包: 主要包含各种与 Buffer 相关的类。
- java.nio.channels 包: 主要包含与 Channel 和 Selector 相关的类。
- java.nio.charset 包: 主要包含与字符集相关的类。
- java.nio.channels.spi 包: 主要包含与 Channel 相关的服务提供者编程接口。
- java.nio.charset.spi 包: 包含与字符集相关的服务提供者编程接口。
图10:NIO核心组件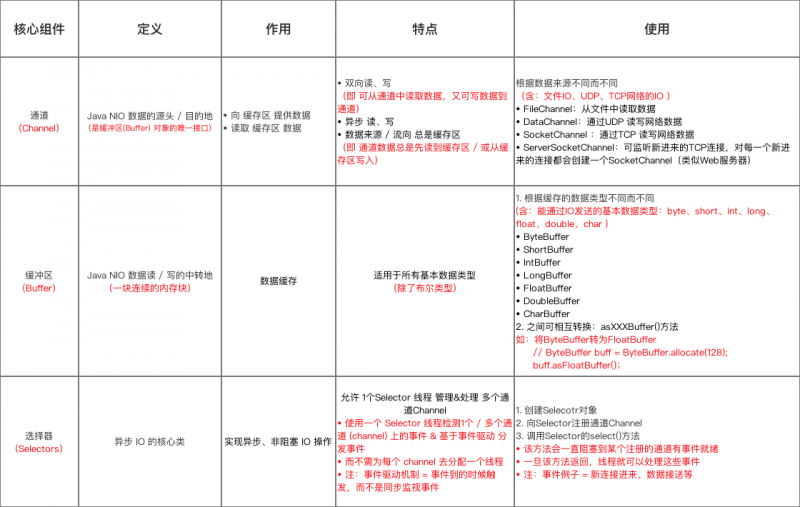
使用 Buffer
从内部结构上来看, Buffer 就像一个数组, 它可以保存多个类型相同的数据。 Buffer是一个抽象类,其最常用的子类是 ByteBuffer, 它可以在底层字节数组上进行 get/set 操作。 除 ByteBuffer 之外, 对应于其他基本数据类型( boolean除外) 都有相应的 Buffer 类: CharBuffer、 ShortBuffer、 IntBuffer、LongBuffer、FloatBuffer、 DoubleBuffer。
上面这些 Buffer类, 除 ByteBuffer 之外, 它们都采用相同或相似的方法来管理数据, 只是各自管理的数据类型不同而己。 这些 Buffer 类都没有提供构造器, 通过使用如下方法来得到一个 Buffer 对象。
- static XxxBufFer allocate(int capacity): 创建一个容量为 capacity 的 XxxBuffer 对象。
但实际使用较多的是 ByteBuffer 和 CharBuffer, 其他 Buffer 子类则较少用到。 其中 ByteBuffer 类还有一个子类: MappedByteBuffer, 它用于表示 Channel 将磁盘文件的部分或全部内容映射到内存中后得到的结果, 通常MappedByteBuffer 对象由 Channel 的 map()方法返回。
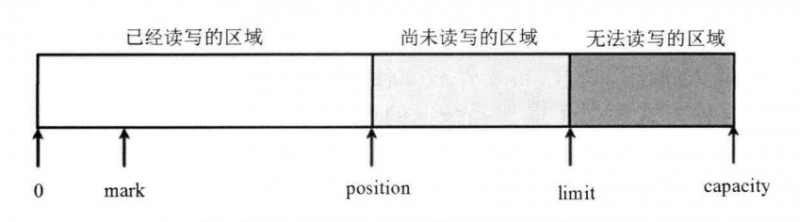
在 Buffer 中有三个重要的概念: 容量( capacity)、 界限 ( limit ) 和 位 置( position )。
- 容 量 (capacity): 缓冲区的容量 (capacity) 表 示 该 Buffer 的最大数据容量, 即最多可以存储多少数据。 缓冲区的容量不可能为负值, 创建后不能改变。
- 界限 ( limit ): 第一个不应该被读出或者写入的缓冲区位置索引。 也就是说, 位于 limit 后的数据既不可被读, 也不可被写。
- 位置 ( position ): 用于指明下一个可以被读出的或者写入的缓冲区位置索引( 类似于IO流中的记录指针)。 当使用 Buffer 从 Channel 中读取数据时,position 的值恰好等于己经读到了多少数据。 当刚刚新建一个 Buffer 对象时, 其position 为 0; 如 果 从 Channel 中读取了 2 个 数 据 到该 Buffer 中, 则 position 为 2, 指向 Buffer 中 第 3 个( 第1个位置的索引为0) 位 置。
Buffer 里还支持一个可选的标记 (mark, 类 似于传统 IO流中的mark ), Buffer 允许直接将 position 定位到该 mark 处。 这些值满足如下关系:
mark<position<limit<capacity图11:Buffer 读入数据后的示意图
Buffer 的主要作用就是装入数据,然后输出数据( 其作用类似于前面介绍的取水的“ 竹筒”), 开始时 Buffer的position 为 0, limit 为 capacity, 程序可通过 put()方法向 Buffer 中放入一些数据 ( 或者从 Channel 中获取一些数据), 每放入一些数据, Buffer 的 position 相应地向后移动一些位置。
当 Buffer 装入数据结束后, 调用 Buffer 的 flip()方法, 该方法将 limit 设置为 position 所在位置, 并将 position 设为 0, 这就使得 Buffer 的读写指针又移到了开始位置。 也就是说, Buffer 调用 flip()方法之后, Buffer 为输出数据做好准备; 当 Buffer 输出数据结束后, Buffer 调用 clear()方法, clear()方法不是清空 Buffer 的数据, 它仅仅将 position 置 为 0, 将 limit 置 为 capacity, 这 样 为 再 次 向 Buffer 中装入数据做好准备。
除此之外, Buffer 还包含如下一些常用的方法。
- int capacity(): 返回 Buffer 的 capacity 大小。
- boolean hasRemaining(): 判断当前位置 ( position ) 和界限 ( limit ) 之间是否还有元素可供处理。
- int limit(): 返回 Buffer 的界限 ( limit ) 的位置。
- Buffer limit(int newLt): 重新设置界限 ( limit ) 的值, 并返回一个具有新的 limit 的缓冲区对象。
- Buffer mark(): 设置 Buffer 的 mark 位置, 它只能在 0 和位置 ( position ) 之间做 mark。
- int position(): 返回 Buffer 中的 position 值。
- Buffer position(int newPs): 设置 Buffer 的 position, 并 返 回 position 被修改后的 Buffer 对象。
- int remaining(): 返回当前位置和界限 ( limit ) 之间的元素个数。
- Buffer reset(): 将位置( position ) 转到 mark 所在的位置。
- Buffer rewind(): 将位置( position ) 设置成 0, 取消设置的 mark。
除这些移动 position、 limit、 mark 的方法之外, Buffer 的所有子类还提供了两个重要的方法: put()和 get()方法, 用于向 Buffer 中放入数据和从 Buffer 中取出数据。 当使用 put()和 get()方法放入、 取出数据时, Buffer 既支持对单个数据的访问, 也支持对批量数据的访问( 以数组作为参数)。
当使用 put()和 get()来访问 Buffer 中的数据时, 分为相对和绝对两种:
- 相对( Relative ): 从 Buffer 的当前 position 处开始读取或写入数据, 然后将位置( position ) 的值按处理元素的个数增加。
- 绝对( Absolute): 直接根据索引向 Buffer 中读取或写入数据, 使用绝对方式访问 Buffer 里的数据时, 并不会影响位置 ( position ) 的值。
下面程序为 Buffer 的一些常规操作实例:
import java.nio.*;publicclassBufferTest
{
publicstaticvoidmain(String[] args)
{
// 创建Buffer
CharBuffer buff = CharBuffer.allocate(8); // ①
System.out.println("capacity: " + buff.capacity());
System.out.println("limit: " + buff.limit());
System.out.println("position: " + buff.position());
// 放入元素
buff.put('a');
buff.put('b');
buff.put('c'); // ②
System.out.println("加入三个元素后,position = "
+ buff.position());
// 调用flip()方法
buff.flip(); // ③
System.out.println("执行flip()后,limit = " + buff.limit());
System.out.println("position = " + buff.position());
// 取出第一个元素
System.out.println("第一个元素(position=0):" + buff.get()); // ④
System.out.println("取出一个元素后,position = "
+ buff.position());
// 调用clear方法
buff.clear(); // ⑤
System.out.println("执行clear()后,limit = " + buff.limit());
System.out.println("执行clear()后,position = "
+ buff.position());
System.out.println("执行clear()后,缓冲区内容并没有被清除:"
+ "第三个元素为:" + buff.get(2)); // ⑥
System.out.println("执行绝对读取后,position = "
+ buff.position());
}
}
API:java.nio.Buffer
使用 Channel
缓冲区为我们装载了数据,但是数据的写入和读取并不能直接进行read()和write()这样的系统调用,而是JVM为我们提供了一层对系统调用的封装。而Channel可以用最小的开销来访问操作系统本身的IO服务,这就是为什么要有Channel的原因。
Channel 类似于传统的流对象, 但与传统的流对象有两个主要区别。
- Channel 可以直接将指定文件的部分或全部直接映射成 Buffer。
- 程序不能直接访问 Channel 中的数据, 包括读取、 写入都不行, Channel 只能与 Buffer 进行交互。 也就是说, 如果要从 Channel 中取得数据, 必须先用 Buffer 从 Channel 中取出一些数据,然后让程序从 Buffer 中取出这些数据; 如果要将程序中的数据写入 Channel, —样先让程序将数据放入 Buffer 中, 程序再将 Buffer 里的数据写入 Channel 中。
Java 为 Channel 接口提供了DatagramChanneKFileChanneKPipe.SinkChanneKPipe.SourceChanneK
SelectableChannel、 ServerSocketChannel 、 SocketChannel 等实现类。
——新IO里的 Channel 是按功能来划分的。
所有的 Channel 都不应该通过构造器来直接创建, 而是通过传统的节点 InputStream、 OutputStream的 getChannel()方法来返回对应的 Channel, 不同的节点流获得的 Channel 不一样。 例如,FilelnputStream、FileOutputStream 的 getChannel()返回的是 FileChannel, 而 PipedlnputStream、 PipedOutputStream 的getChannel()返回的是 Pipe.SinkChanneK Pipe.SourceChannel。
Channel 中最常用的三类方法是 map()、 read()和 write(), 其中 map()方法用于将 Channel 对应的部分或全部数据映射成 ByteBuffer; 而 read()或 write()方法都有一系列重载形式, 这些方法用于从 Buffer中读取数据或向 Buffer 中写入数据。
map()方法的方法签名为: MappedByteBuffer map(FileChannel.MapMode mode, long position, longsize), 第一个参数执行映射时的模式, 分别有只读、 读写等模式; 而第二个、 第三个参数用于控制将Channel 的哪些数据映射成 ByteBuffer。
下面程序直接将 FileChannel 的全部数据映射成 ByteBuffer:
import java.io.*;import java.nio.*;
import java.nio.channels.*;
import java.nio.charset.*;
publicclassFileChannelTest
{
publicstaticvoidmain(String[] args)
{
File f = new File("FileChannelTest.java");
try(
// 创建FileInputStream,以该文件输入流创建FileChannel
FileChannel inChannel = new FileInputStream(f).getChannel();
// 以文件输出流创建FileBuffer,用以控制输出
FileChannel outChannel = new FileOutputStream("a.txt")
.getChannel())
{
// 将FileChannel里的全部数据映射成ByteBuffer
MappedByteBuffer buffer = inChannel.map(FileChannel
.MapMode.READ_ONLY , 0 , f.length()); // ①
// 使用GBK的字符集来创建解码器
Charset charset = Charset.forName("GBK");
// 直接将buffer里的数据全部输出
outChannel.write(buffer); // ②
// 再次调用buffer的clear()方法,复原limit、position的位置
buffer.clear();
// 创建解码器(CharsetDecoder)对象
CharsetDecoder decoder = charset.newDecoder();
// 使用解码器将ByteBuffer转换成CharBuffer
CharBuffer charBuffer = decoder.decode(buffer);
// CharBuffer的toString方法可以获取对应的字符串
System.out.println(charBuffer);
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
API:java.nio.channels.Channels
API:java.nio.channels.FileChannel
使用Selector
Selector(选择器)是Java NIO中能够检测一到多个NIO通道,并能够知晓通道是否为诸如读写事件做好准备的组件。这样,一个单独的线程可以管理多个channel,从而管理多个网络连接。
仅用单个线程来处理多个Channels的好处是,只需要更少的线程来处理通道。事实上,可以只用一个线程处理所有的通道。对于操作系统来说,线程之间上下文切换的开销很大,而且每个线程都要占用系统的一些资源(如内存)。因此,使用的线程越少越好。
但是,需要记住,现代的操作系统和CPU在多任务方面表现的越来越好,所以多线程的开销随着时间的推移,变得越来越小了。实际上,如果一个CPU有多个内核,不使用多任务可能是在浪费CPU能力。不管怎么说,关于那种设计的讨论应该放在另一篇不同的文章中。在这里,只要知道使用Selector能够处理多个通道就足够了。
下面是单线程使用一个Selector处理3个channel的示例:
//1、通过调用Selector.open()方法创建一个SelectoSelector sel = Selector.open();
//2、向Selector注册通道
channel.configureBlocking(false);
SelectionKey key = channel.register(selector,Selectionkey.OP_READ);
与Selector一起使用时,Channel必须处于非阻塞模式下。这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式,而套SocketChannel可以。
更完整实例如下:
// 1. 创建Selector对象 Selector sel = Selector.open();
// 2. 向Selector对象绑定通道
// a. 创建可选择通道,并配置为非阻塞模式
ServerSocketChannel server = ServerSocketChannel.open();
server.configureBlocking(false);
// b. 绑定通道到指定端口
ServerSocket socket = server.socket();
InetSocketAddress address = new InetSocketAddress(port);
socket.bind(address);
// c. 向Selector中注册感兴趣的事件
server.register(sel, SelectionKey.OP_ACCEPT);
return sel;
// 3. 处理事件
try {
while(true) {
// 该调用会阻塞,直到至少有一个事件就绪、准备发生
selector.select();
// 一旦上述方法返回,线程就可以处理这些事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = (SelectionKey) iter.next();
iter.remove();
process(key);
}
}
} catch (IOException e) {
e.printStackTrace();
}
【1】:《疯狂Java讲义》
【2】:廖雪峰的官方网站:File对象
【3】:廖雪峰的官方网站:InputStream
【4】:廖雪峰的官方网站:Reader
【5】:廖雪峰的官方网站:Writer
【6】:【一图胜千言】java流IO超详细思维导图 含xmind文件
【7】:Java.IO层次体系结构
【8】:Java NIO系列教程(一) Java NIO 概述
【9】:Java NIO系列教程(六) Selector
【10】:Java:带你全面了解神秘的Java NIO
【11】:Java基础:攻破JAVA NIO技术壁垒1
【12】:Java基础:攻破JAVA NIO技术壁垒2
以上是 Java Review(三十六、IO) 的全部内容, 来源链接: utcz.com/a/21176.html



