Mybatis源码Mapper接口定义
解析Mapper接口定义
经过一番艰苦的鏖战,我们总算是了解了mybatis是如何完成mapper.xml文件解析工作的.
但是,因为整个流程比较复杂和繁琐,相信很多人已经忘记了在解析mapper.xml之前,我们具体做了哪些工作.
现在我们就回顾一下,在解析mapper.xml之前所进行的操作.
在Mybatis源码之美:2.15.解析Mybatis的Mapper配置,初始化SQL环境的过程一文中,我们介绍了mybatis全局配置文件中用于配置Mapper定义的mapper和package两个元素的用法.
并根据这两个元素及其属性定义将其分为两类,一类指向mapper.xml文件,一类指向Mapper接口:
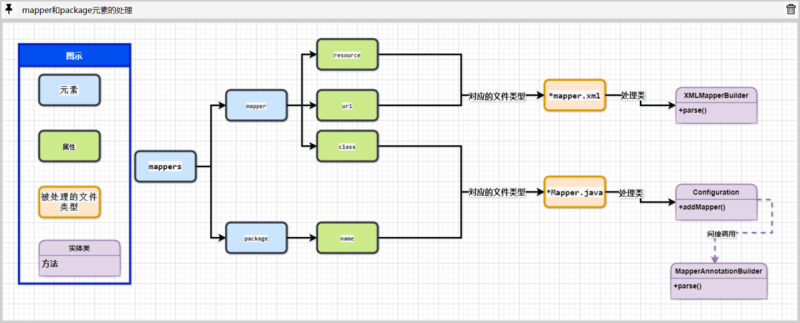
XMLConfigBuilder对象的mapperElement()方法被委以重任,担负起处理这两个元素的艰巨任务.
从实现上来看,根据具体元素及其属性的不同,mapperElement()方法会为mapper或者package元素执行不同的处理.
其中,鉴于mapper子元素的url和resource属性用于配置mapper.xml文件,因此mapperElement()方法会将其转换为XMLMapperBuilder对象进行后续的解析处理.
而mapper子元素的class属性用于指向一个Mapper接口定义,因此他会被委托给Configuration对象的addMapper()方法来处理.
至于package元素,他的作用是配置一组Mapper接口所处的包路径,因此他会被委托给Configuration对象的addMappers()方法来处理.
其中.无论是Configuration对象的addMapper()方法还是addMappers()的实现都是委托给MapperRegistry的同名方法来完成的.
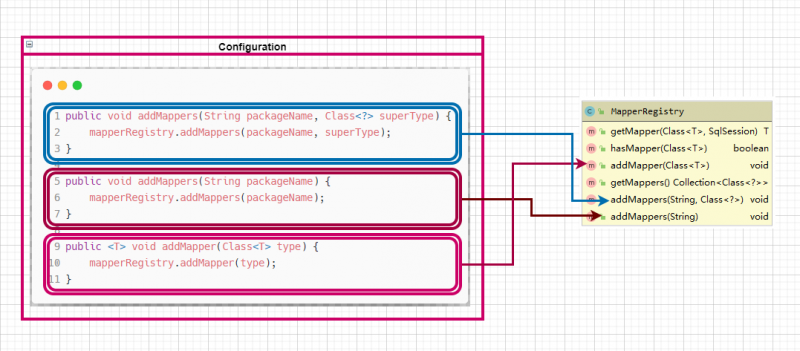
先撇开MapperRegistry的addMapper()方法的实现不谈,我们先看一下addMappers()方法的实现,该方法借助于ResolverUtil加载出用户指定包下的所有类定义,然后再交给addMapper()方法来处理:
/*** 根据基础包名,批量注册映射器
*
* @since 3.2.2
*/
publicvoidaddMappers(String packageName){
// 注册指定包下所有的java类
addMappers(packageName, Object.class);
}
/**
* 根据基础包名和父类/接口限制,批量注册映射器
*
* @since 3.2.2
*/
publicvoidaddMappers(String packageName, Class<?> superType){
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 加载指定包下的继承/实现了指定类型的所有类
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> mapperSet = resolverUtil.getClasses();
for (Class<?> mapperClass : mapperSet) {
// 执行映射器的注册操作
addMapper(mapperClass);
}
}
因此无论是package元素配置也好,还是mapper元素的class属性配置也罢,他们最终调用的处理方法都是MapperRegistry的addMapper()方法.
回到负责解析mapper.xml配置文件的XMLMapperBuilder的实现上来,它的parse()方法大致分为三步:
- 解析处理
mapper.xml文件 - 解析处理
mapper.xml文件对应的Mapper接口定义 - 补偿之前未完成处理的配置
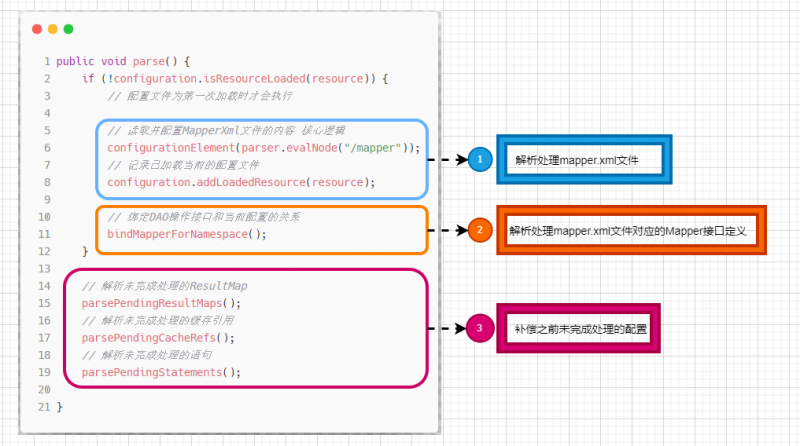
其中第二步涉及到的bindMapperForNamespace()方法展开来看,主要就是根据mapper.xml文件中的namespace属性找到相应的Mapper接口定义,并交由Configuration对象的addMapper()方法继续处理:
privatevoidbindMapperForNamespace(){String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class<?> boundType = null;
try {
// 加载Mapper文件对应的Dao操作接口
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
//ignore, bound type is not required
}
if (boundType != null) {
if (!configuration.hasMapper(boundType)) {
// 如果尚未绑定该资源则执行下列处理
// Spring may not know the real resource name so we set a flag
// to prevent loading again this resource from the mapper interface
// look at MapperAnnotationBuilder#loadXmlResourceloadXmlResource
// 注册已加载过的资源集合
configuration.addLoadedResource("namespace:" + namespace);
// 注册DAO操作接口
configuration.addMapper(boundType);
}
}
}
}
其中有两段代码值得注意:
- 一段是
if (!configuration.hasMapper(boundType))校验,这一步确保了同一Mapper接口不会被重复处理. - 一段是
configuration.addLoadedResource("namespace:" + namespace);,这一段通过namespace:前缀和具体的Mapper接口的全限定名称生成了一个唯一标志,该标志用于在MapperAnnotationBuilder中确保同一mapper.xml文件不会被重复处理.
负责维护Mapper接口定义的MapperRegistry注册表
简单的复习之后,我们来探究一下Mapper接口的解析处理过程.
刚才我们说过,Configuration将通过包名和类型注册Mapper接口定义的实现都委托为了MapperRegistry的同名方法来实现,那么这个MapperRegistry对象究竟是何方神圣呢?
MapperRegistry在mybatis中担任Mapper接口注册表这一重要角色,他负责维护Mapper接口及负责为该接口创建代理对象的工厂对象MapperProxyFactory之间的关系.
在前面的学习过程中,我们可以轻易的发现,在定义一个Mapper接口时,我们无需为其创建对应的实现类,就能够调用其方法,并完成相应的数据库操作.
这一功能的实现,主要归功于MapperProxyFactory,MapperProxyFactory会为Mapper接口创建一个合适的代理对象,拦截Mapper接口的方法调用,执行相应的数据库操作,并处理响应数据.
所谓的代理对象对应着设计模式中的代理模式,有兴趣可以简单了解一下.
抛开MapperProxyFactory创建代理对象的实现不谈,我们先看MapperRegistry对象的实现.
在MapperRegistry中有两个属性定义,一个负责维护Configuration对象,另一个是Map<Class<?>, MapperProxyFactory<?>>类型的knownMappers集合,该集合负责维护Mapper接口和MapperProxyFactory之间的关系.
相应的,作为一个注册表来说,MapperRegistry也分别对外暴露了getter/setter方法来操作注册表中的数据.
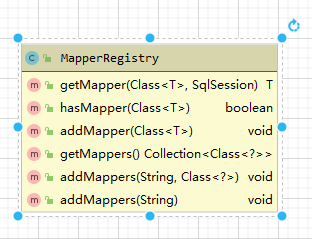
按照操作类型来区分,负责往注册表中添加数据的是两个addMappers()方法和一个addMapper()方法,负责从注册表中取数据的是getMappers()方法和getMapper()方法,最后一个hasMapper()方法用于检验注册表中是否含有指定类型的数据记录.
其中两个addMappers()方法的实现,我们前面刚看过,现在我们就看看最核心的注册方法addMapper():
public <T> voidaddMapper(Class<T> type){if (type.isInterface()) {
// 只处理接口
if (hasMapper(type)) {
// 只处理一次
thrownew BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 放入已知的代理映射中,mapper接口->MapperProxyFactory代理对象
knownMappers.put(type, new MapperProxyFactory<T>(type));
// 在运行解析器之前添加类型非常重要.
// 否则,映射器解析器可能会自动尝试绑定。
// 如果类型已知,则不会尝试
// 解析注解
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
// 执行解析
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
// 移除解析出现异常的接口
knownMappers.remove(type);
}
}
}
}
从实现上来,这个方法大致可以分为三步:
- 1.限制被处理的
Mapper类型必须为接口,且只能处理一次 - 2.为被处理的
Mapper接口创建相应的MapperProxyFactory对象 - 3.通过
MapperAnnotationBuilder完成Mapper接口的解析处理工作
除此之外呢,鉴于第三步的解析操作可能会出现解析失败的问题,因此在无法完成解析时,第二步注册的数据将会被移除.
关于MapperAnnotationBuilder的解析,我们待会再深入探究,现在继续看一下MapperRegistry对象的getter方法实现.
三个getter方法中的hasMapper()和getMappers()方法都是简单的属性获取操作:
public <T> booleanhasMapper(Class<T> type){return knownMappers.containsKey(type);
}
public Collection<Class<?>> getMappers() {
return Collections.unmodifiableCollection(knownMappers.keySet());
}
相对复杂一点的就是getMapper()方法的实现了:
public <T> T getMapper(Class<T> type, SqlSession sqlSession){// 从缓存获取映射器代理对象
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
thrownew BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 通过代理工厂实例化映射器实例
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
thrownew BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
在前面的文章中,我们简单介绍过SqlSession对象:
SqlSession是Mybatis提供给用户进行数据库操作的顶层API接口,它定义了操作数据库的方法并提供了操纵事务的能力,在Mybatis框架中,一定程度上我们可以认为SqlSession对象用于取代JDBC的Connection对象。通过前面文章的学习,我们已经基本了解了如何通过
mapper.xml文件来初始化MappedStatement对象,本篇文章则主要探究如何通过Mapper接口定义初始化MappedStatement对象.
在这里我们不会探究更多关于SqlSession对象的内容,而是简单回顾一下,便于解析接下来的内容.
getMapper()的实现原理基本就是获取指定Mapper接口对应的MapperProxyFactory对象,并以SqlSession作为参数调用MapperProxyFactory对象的newInstance()方法获取指定Mapper接口的代理类.
更多关于MapperProxyFactory的细节,我们会在后面的文章中进行探究.这样我们就简单了解了MapperRegistry对象的实现和作用.
现在,我们继续回到addMapper()方法上来,刚才我们说过实际负责解析Mapper接口定义的是MapperAnnotationBuilder对象:
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);// 执行解析
parser.parse();
现在我们就来探究一下该对象的实现,看上面的方法调用,MapperAnnotationBuilder对象的构造方法需要两个参数一个是Configuration对象,一个是Mapper接口类型.
在MapperAnnotationBuilder对象的构造方法中,利用这两个参数完成了基本属性的获取操作:
/*** Mybatis配置
*
*/
privatefinal Configuration configuration;
/**
* Mapper构建助手
*/
privatefinal MapperBuilderAssistant assistant;
/**
* Mapper接口类型
*/
privatefinal Class<?> type;
publicMapperAnnotationBuilder(Configuration configuration, Class<?> type){
// 转换为类名称
String resource = type.getName().replace('.', '/') + ".java (best guess)";
this.assistant = new MapperBuilderAssistant(configuration, resource);
this.configuration = configuration;
this.type = type;
}
其中值得注意的就是构建MapperBuilderAssistant对象的resource属性是通过Mapper接口类型的全限定名称推断出来的.
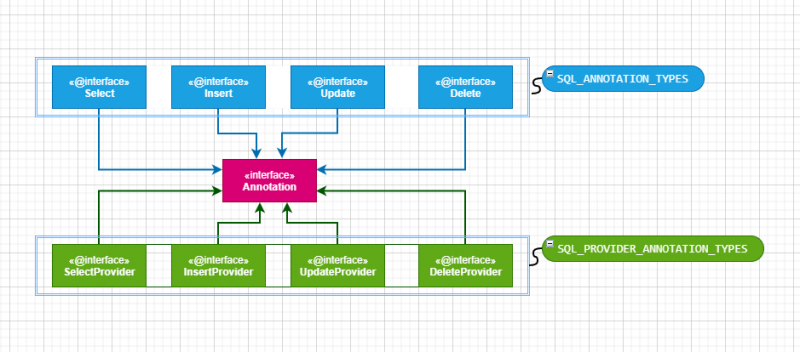
除此之外呢,MapperBuilderAssistant对象还有一个静态方法,该方法负责为MapperBuilderAssistant中的两个常量集合赋值:
/*** SQL语句的注解
*/
privatestaticfinal Set<Class<? extends Annotation>> SQL_ANNOTATION_TYPES = new HashSet<>();
/**
* SQL语句提供者的注解
*/
privatestaticfinal Set<Class<? extends Annotation>> SQL_PROVIDER_ANNOTATION_TYPES = new HashSet<>();
static {
/*
* SQL语句类型注解
*/
SQL_ANNOTATION_TYPES.add(Select.class);
SQL_ANNOTATION_TYPES.add(Insert.class);
SQL_ANNOTATION_TYPES.add(Update.class);
SQL_ANNOTATION_TYPES.add(Delete.class);
/*
* SQL 语句构造注解
*/
SQL_PROVIDER_ANNOTATION_TYPES.add(SelectProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(InsertProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(UpdateProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(DeleteProvider.class);
}
其中SQL_ANNOTATION_TYPES维护了配置SQL语句的系列注解,SQL_PROVIDER_ANNOTATION_TYPES则维护了负责配置提供SQL语句提供者的系列注解.
MapperAnnotationBuilder对象对外暴露的解析入口方法名为parse():
publicvoidparse(){// 对应的资源是类名称
String resource = type.toString();
// 校验资源只加载一次
if (!configuration.isResourceLoaded(resource)) {
// step1: 解析处理Mapper接口对应的XML文件
// 如果当前还未加载过该类,继续处理,否则跳过处理
// 加载对应的XML文件,并解析
loadXmlResource();
// 表示已加载当前资源
configuration.addLoadedResource(resource);
// 配置当前mapper文件的命名空间
assistant.setCurrentNamespace(type.getName());
// step2: 类注解解析处理
// 解析缓存
parseCache();
// 解析缓存引用
parseCacheRef();
// step3: 方法注解解析
// 获取指定接口定义的所有方法
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
// 此处不会处理由JDK生成的桥接方法
// 解析声明语句
parseStatement(method);
}
} catch (IncompleteElementException e) {
// 添加至尚未完成处理的方法集合中
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
// 补偿之前未完成解析操作的方法
parsePendingMethods();
}
该方法从实现上来看,大致可以分为三步:
- 1.加载并解析可能存在的
Mapper接口对应的XML文件配置. - 2.解析
Mapper接口上的类注解定义 - 3.解析
Mapper接口中的方法定义
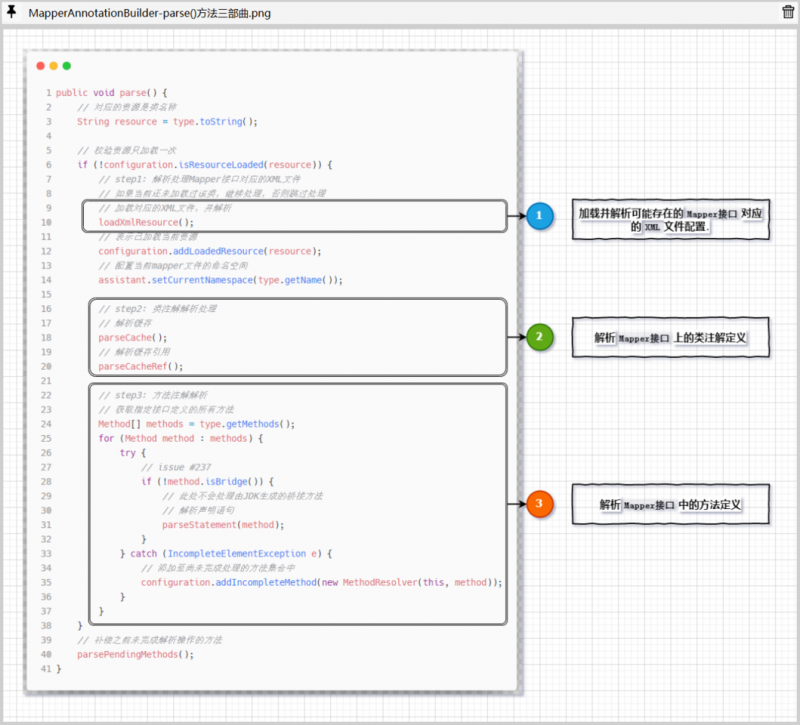
除此这三步之外呢,parse()方法还做了一些额外的功能性操作,比如在处理Mapper接口之前校验Mapper接口是否已被处理过,避免重复操作:
// 对应的资源是类名称String resource = type.toString();
// 校验资源只加载一次
if (!configuration.isResourceLoaded(resource)) {
// ... 处理操作 ...
}
在处理完XML文件之后,向mybatis记录该Mapper接口已被处理,结合着上一步的验证,完成Mapper接口防重解析的闭环操作:
// 表示已加载当前资源configuration.addLoadedResource(resource);
// 配置当前mapper文件的命名空间
assistant.setCurrentNamespace(type.getName());
在方法的最后,还会调用parsePendingMethods()方法来补偿之前因为各种原因未能成功处理的方法定义:
privatevoidparsePendingMethods(){// 解析尚未完成解析的方法
Collection<MethodResolver> incompleteMethods = configuration.getIncompleteMethods();
synchronized (incompleteMethods) {
Iterator<MethodResolver> iter = incompleteMethods.iterator();
while (iter.hasNext()) {
try {
iter.next().resolve();
iter.remove();
} catch (IncompleteElementException e) {
// This method is still missing a resource
}
}
}
}
parsePendingMethods()的实现是遍历所有未处理的方法解析器MethodResolver,并调用其resolve()方法,完成方法的解析处理操作,MethodResolver对象的构建和实现,我们会在后面详解.
在了解了parse()方法的基本实现之后,我们开始详细的探究parse()方法中的三步核心操作.
加载并解析Mapper接口对应的XML配置文件
首先是加载并解析Mapper接口对应的XML配置文件,通过前面的学习,我们知道mapper.xml配置文件中的根元素mapper有一个namespace属性.
<!ATTLISTmappernamespaceCDATA #IMPLIED
>
正常来说,namespace属性的取值是该mapper文件对应的Mapper接口定义的全限定名称。
根据这个定义,我们在解析XMl文件时,可以非常容易的推算出对应的Mapper接口.
但是在mapper接口中,却没有一个属性来显式的指定Mapper接口对应的XML文件,因此,基于java开发中约定大于配置的经验来看,在mybatis中有一个约定成俗的规则:
在mybatis中,Mapper接口与其对应的XML文件,往往具有一致的目录结构,以及除文件后缀之外完全相同的文件名.
在这个约束条件下,我们就可以很方便的通过Mapper接口来获取所对应的XML文件了.
loadXmlResource()方法的实现就立足于这一约束条件下:
privatevoidloadXmlResource(){// Spring may not know the real resource name so we check a flag
// to prevent loading again a resource twice
// this flag is set at XMLMapperBuilder#bindMapperForNamespace
if (!configuration.isResourceLoaded("namespace:" + type.getName())) {
// 获取对应的XML资源文件
String xmlResource = type.getName().replace('.', '/') + ".xml";
// #1347
// 读取对应的资源文件
InputStream inputStream = type.getResourceAsStream("/" + xmlResource);
if (inputStream == null) {
// Search XML mapper that is not in the module but in the classpath.
try {
// 在类加载路径加载资源文件
inputStream = Resources.getResourceAsStream(type.getClassLoader(), xmlResource);
} catch (IOException e2) {
// 如果不能获取对应的配置文件,忽略处理,因为对应的配置可以通过注解来实现
// ignore, resource is not required
}
}
if (inputStream != null) {
// 生成对应的Xml解析器
XMLMapperBuilder xmlParser = new XMLMapperBuilder(inputStream, assistant.getConfiguration(), xmlResource, configuration.getSqlFragments(), type.getName());
// 解析对应的xml文件
xmlParser.parse();
}
}
}
mybatis会通过Mapper接口的全限定名称,解析出Mapper接口的目录结构,并由此得到Mapper接口对应的XML文件的文件访问地址.
在XML文件存在的前提下,构建一个相应的XMLMapperBuilder对象完成XML配置文件的解析工作.
这时候,我们再回头看一下XMLMapperBuilder和MapperAnnotationBuilder之间的关系,我们会发现,二者形成了一个伪递归调用的依赖关系.
在解析时无论是先解析XML文件还是Mapper接口定义,mybatis都会按照一定的规则去寻找其对应的Mapper接口或者XML文件,来完成一个Mapper对象的完整的解析工作.为什么说这是一个伪递归调用呢?
这是因为,无论是
XMLMapperBuilder还是MapperAnnotationBuilder,在实现上,做的第一步都是防重解析校验.
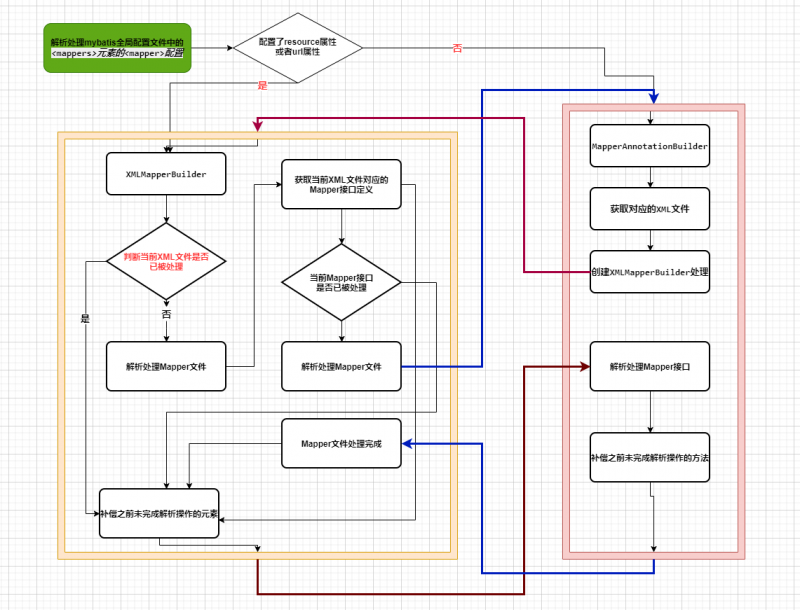
解析Mapper接口上的类注解定义
mybatis提供了基于注解配置SQL的能力,这一能力的效果基本等同于通过XML文件配置SQL的效果.
mybatis为XML文件中定义的大部分元素都提供了相对应的注解实现,这些注解根据XML元素的效果的不同而具有不同的作用范围,具体体现就是:有些注解是类注解,有些注解是方法注解,当然还有一些其他类型的注解,我们在遇到的时候再细说.
现在,我们先来看一下,定义在Mapper接口上的类注解,在mybatis中,用于Mapper接口的类注解有三个,除了标识性注解Mapper之外,真正具有配置能力的只有两个,他们分别是:CacheNamespace和CacheNamespaceRef.
CacheNamespace和CacheNamespaceRef这两个注解都是用来为Mapper定义提供缓存配置的,他们的作用基本等同于mapper.xml文件中的cache和cache-ref元素.
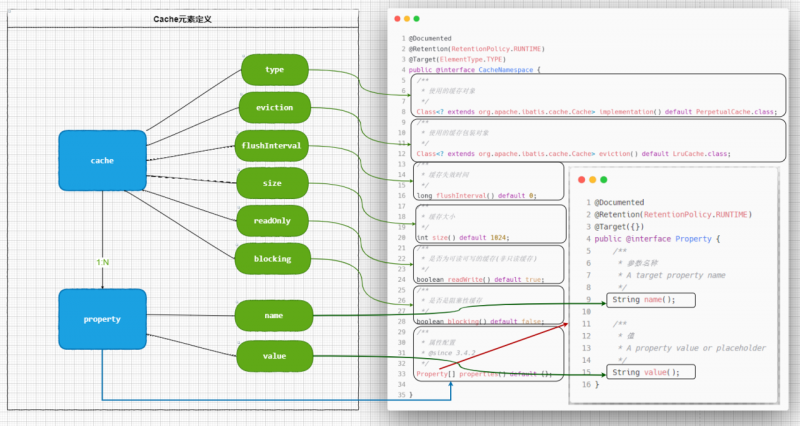
我们看一下这个注解及其元素的对照关系图:
cache元素和CacheNamespace的对应关系:
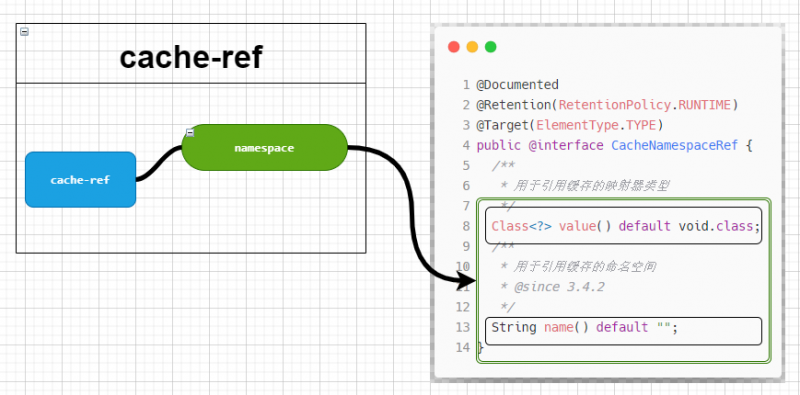
cache-ref和CacheNamespaceRef的关系:
仔细看cache元素和CacheNamespace的对应关系,注解和元素定义在属性定义上基本保持着一对一的关系,因此cache元素和CacheNamespace的用法和解析操作也基本一致.
cache-ref和CacheNamespaceRef的关系中,CacheNamespaceRef定义了两个属性,其中type表示被引用的缓存配置所属的Mapper接口定义,name则表示被引用缓存的命名空间名称.
type和name来两个属性是互斥的,type用于通过Mapper接口类型引用缓存配置,name则负责通过Mapper接口的命名空间名称来引用缓存配置.
现在我们回到代码实现上来,负责解析CacheNamespace注解的是方法parseCache(),该方法会获取用户通过CacheNamespace注解提供的配置,并将其传递给MapperBuilderAssistant的useNewCache方法来完成缓存的处理:
privatevoidparseCache(){CacheNamespace cacheDomain = type.getAnnotation(CacheNamespace.class);
if (cacheDomain != null) {
// 获取缓存大小的限制
Integer size = cacheDomain.size() == 0 ? null : cacheDomain.size();
// 获取缓存失效时间
Long flushInterval = cacheDomain.flushInterval() == 0 ? null : cacheDomain.flushInterval();
// 获取自定义参数配置
Properties props = convertToProperties(cacheDomain.properties());
// 构建配置缓存引用
assistant.useNewCache(cacheDomain.implementation(), cacheDomain.eviction(), flushInterval, size, cacheDomain.readWrite(), cacheDomain.blocking(), props);
}
}
在处理过程中,名为convertToProperties()的方法负责将Property注解转换为Properties对象:
private Properties convertToProperties(Property[] properties){if (properties.length == 0) {
returnnull;
}
Properties props = new Properties();
for (Property property : properties) {
props.setProperty(property.name(),
PropertyParser.parse(property.value(), configuration.getVariables()));
}
return props;
}
MapperBuilderAssistant的useNewCache方法的实现,我们在Mybatis源码之美:3.3.Mybatis中的缓存配置一文中已经做了较为详细的探究.
负责解析CacheNamespaceRef注解的方法是parseCacheRef():
privatevoidparseCacheRef(){CacheNamespaceRef cacheDomainRef = type.getAnnotation(CacheNamespaceRef.class);
if (cacheDomainRef != null) {
// 引用缓存对应的映射器类型
Class<?> refType = cacheDomainRef.value();
// 引用缓存对应的命名空间
String refName = cacheDomainRef.name();
if (refType == void.class && refName.isEmpty()) {
thrownew BuilderException("Should be specified either value() or name() attribute in the @CacheNamespaceRef");
}
if (refType != void.class && !refName.isEmpty()) {
thrownew BuilderException("Cannot use both value() and name() attribute in the @CacheNamespaceRef");
}
// 解析出对应的命名空间名称
String namespace = (refType != void.class) ? refType.getName() : refName;
try {
assistant.useCacheRef(namespace);
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(new CacheRefResolver(assistant, namespace));
}
}
}
从实现上来看,该方法限制了CacheNamespaceRef注解中的value()和name()两个属性必须满足有且仅有一个的条件.
之后将value()和name()的取值转换为相应的命名空间,并交由MapperBuilderAssistant的useCacheRef()方法来完成后续的处理工作.
同样,关于MapperBuilderAssistant的useCacheRef()方法的实现,我们在文章Mybatis源码之美:3.2.Mybatis中跨命名空间的缓存引用一文中已经完成了相应的探究工作.
那么,这就是Mapper接口上的两个类注解的处理工作,因为针对于一个Mapper定义来说,缓存配置是唯一的,因此其被设计为类注解.
解析Mapper接口中的方法定义
在完成了Mapper接口中缓存配置的处理工作之后,mybatis将会加载Mapper接口中所有的有效方法定义,并将这些方法解析转换为对应的MappedStatement对象.
Method[] methods = type.getMethods();for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
// 此处不会处理由JDK生成的桥接方法
// 解析声明语句
parseStatement(method);
}
} catch (IncompleteElementException e) {
// 添加至尚未完成处理的方法集合中
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
这里所谓的有效方法就是除了由编译器自动生成的桥接方法之外的所有方法.
关于桥接方法的内容虽然很简单,但是基于篇幅考虑,这里就不展开了,但是强烈建议了解一下桥接方法相关的内容.
负责解析桥接方法的方法是parseStatement(),该方法只有一个Method类型的入参.
虽然parseStatement()方法的实现看起来比较长,涉及到的东西也比较多.
但是因为注解和XML元素之间具有极强的相关性以及我们在前面的文章中已经了解了如何通过CRUD元素创建相应的MappedStatement对象,所以对我们而言,parseStatement()方法的整体解析逻辑还是比较简单的.
整个parseStatement()方法的实现,就是围绕着Method及其相关注解,获取创建MappedStatement对象所需属性的过程.
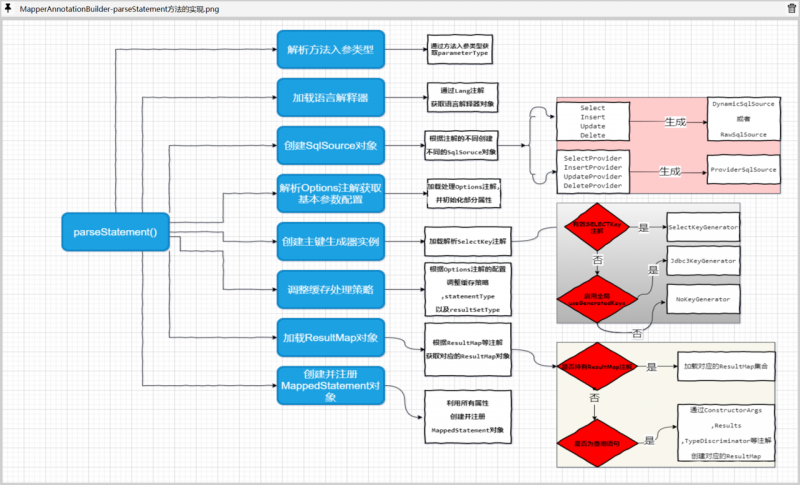
解析parameterType
在parseStatement()方法的实现中,首先借助于getParameterType()方法获取了当前MappedStatement对象所对应的入参类型:
// 获取参数类型Class<?> parameterTypeClass = getParameterType(method);
这步操作取代的是XML配置中parameterMap和parameterType两个属性配置.
getParameterType()方法的实现非常简单,在忽略了RowBounds和ResultHandler两个特殊的入参类型之后,如果只剩下一个入参,那么该参数的类型就是最终的parameterTypeClass,如果剩余多个入参的话,入参类型则会被包装为ParamMap.
private Class<?> getParameterType(Method method) {Class<?> parameterType = null;
// 获取所有的参数类型
Class<?>[] parameterTypes = method.getParameterTypes();
for (Class<?> currentParameterType : parameterTypes) {
// 遍历处理
if (!RowBounds.class.isAssignableFrom(currentParameterType) && !ResultHandler.class.isAssignableFrom(currentParameterType)) {
// 跳过RowBounds和ResultHandler的子类/实现
if (parameterType == null) {
// 处理第一个有效参数时,赋值
parameterType = currentParameterType;
} else {
// 当有效参数大于一个时,返回类型定义为ParamMap
// issue #135
// 这里为何不直接返回?
parameterType = ParamMap.class;
}
}
}
return parameterType;
}
上文中提及的RowBounds和ResultHandler两个对象,是mybatis中提供的具有特殊用途的参数,RowBounds对象用于处理分页,ResultHandler对象用于处理数据库操作结果.
加载语言解释器
得到入参类型之后,parseStatement()方法会调用getLanguageDriver()方法解析Lang注解得到MappedStatement对应的语言解释器:
private LanguageDriver getLanguageDriver(Method method){Lang lang = method.getAnnotation(Lang.class);
Class<? extends LanguageDriver> langClass = null;
if (lang != null) {
langClass = lang.value();
}
return assistant.getLanguageDriver(langClass);
}
该语言解释将被用于解析SQL语句和SelectKey注解.
在这里Lang注解的功能和CRUD元素中的lang属性等效,Lang注解只有一个用来配置语言解释器的属性定义.
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public@interface Lang {
/**
* 对应的语言解析器
*/
Class<? extends LanguageDriver> value();
}
解析注解获取有效SqlSource对象
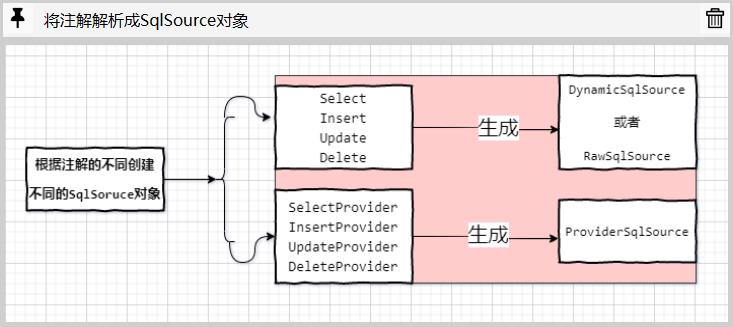
在前面的学习过程中,我们知道能够提供SQL语句的注解有两类,一类是直接提供SQL配置的Select|Insert|Update|Delete注解,一类是通过Java对象提供SQL配置的SelectProvider|InsertProvider|UpdateProvider|DeleteProvider注解.
这两类注解的的定义和用法都不算复杂,其中Select系列注解除了名称不同之外,拥有完全一致的属性定义:

这个String数组类型的value()属性用于维护用户提供的SQL配置.
SelectProvider系列注解和Select系列注解十分相似,SelectProvider|InsertProvider|UpdateProvider|DeleteProvider这四个注解同样拥有一致的属性定义:

其中Class类型的type属性用于指定负责提供SQL配置的类的类型,String类型的method属性用于进一步指定负责提供SQL的方法名称.
关于注解的示例代码,可以参考文章Mybatis源码之美:3.10.1.探究CRUD元素解析工作前的知识准备中的相关内容.
回到getSqlSourceFromAnnotations()方法上来,Select系列注解和SelectProvider系列注解因为作用不同,所以具有完全不同的两种解析方式,最后也会被处理成截然不同的SqlSource实例:
private SqlSource getSqlSourceFromAnnotations(Method method, Class<?> parameterType, LanguageDriver languageDriver){try {
// 获取注解了Select|Insert|Update|Delete的方法注解
Class<? extends Annotation> sqlAnnotationType = getSqlAnnotationType(method);
// 获取注解了SelectProvider|InsertProvider|UpdateProvider|DeleteProvider的方法注解
Class<? extends Annotation> sqlProviderAnnotationType = getSqlProviderAnnotationType(method);
// 优先处理Sql注解
if (sqlAnnotationType != null) {
if (sqlProviderAnnotationType != null) {
// 两者不可共存
thrownew BindingException("You cannot supply both a static SQL and SqlProvider to method named " + method.getName());
}
// 获取SQL注解
Annotation sqlAnnotation = method.getAnnotation(sqlAnnotationType);
// 获取注解中的value对应的值
final String[] strings = (String[]) sqlAnnotation.getClass().getMethod("value").invoke(sqlAnnotation);
// 构建SqlSource
return buildSqlSourceFromStrings(strings, parameterType, languageDriver);
} elseif (sqlProviderAnnotationType != null) {
// 获取SqlProvider注解
Annotation sqlProviderAnnotation = method.getAnnotation(sqlProviderAnnotationType);
// 创建ProviderSqlSource对象
returnnew ProviderSqlSource(assistant.getConfiguration(), sqlProviderAnnotation, type, method);
}
returnnull;
} catch (Exception e) {
thrownew BuilderException("Could not find value method on SQL annotation. Cause: " + e, e);
}
}
其中Select系列注解根据具体的配置的不同可能生成RawSqlSource或者DynamicSqlSource对象,当然,前提是你使用了默认的LanguageDriver.
SelectProvider系列注解则会生成相应的ProviderSqlSource对象.
理论知识补充完之后,我们回到getSqlSourceFromAnnotations()方法的实现上来.
从实现上来看,getSqlAnnotationType()和getSqlProviderAnnotationType()两个方法分别用于获取方法上的Select|Insert|Update|Delete注解和SelectProvider|InsertProvider|UpdateProvider|DeleteProvider注解.
这两个方法的具体实现都是委托给chooseAnnotationType()方法来完成的:
SQL_ANNOTATION_TYPES.add(Select.class);SQL_ANNOTATION_TYPES.add(Insert.class);
SQL_ANNOTATION_TYPES.add(Update.class);
SQL_ANNOTATION_TYPES.add(Delete.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(SelectProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(InsertProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(UpdateProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(DeleteProvider.class);
private Class<? extends Annotation> getSqlAnnotationType(Method method) {
return chooseAnnotationType(method, SQL_ANNOTATION_TYPES);
}
private Class<? extends Annotation> getSqlProviderAnnotationType(Method method) {
return chooseAnnotationType(method, SQL_PROVIDER_ANNOTATION_TYPES);
}
chooseAnnotationType()方法的实现只是简单的获取第一个匹配的注解并返回给调用方而已:
private Class<? extends Annotation> chooseAnnotationType(Method method, Set<Class<? extends Annotation>> types) {for (Class<? extends Annotation> type : types) {
Annotation annotation = method.getAnnotation(type);
if (annotation != null) {
return type;
}
}
returnnull;
}
得到方法注解之后,getSqlSourceFromAnnotations()方法会根据注解的类型来创建不同的SqlSource对象.
需要注意的是Select|Insert|Update|Delete注解和SelectProvider|InsertProvider|UpdateProvider|DeleteProvider注解之间的关系是互斥的,即一个方法上不允许同时标注Select系列注解和SelecetProvider注解.
这时候,创建SqlSource对象的工作就因为注解类型的不同,而分成了两种截然不同的方式.
其中Select系列注解因为只有一个用于提供SQL配置的value()属性,因此在简单的进行了字符串拼接工作之后,后续创建SqlSource对象的工作就交给了LanguageDriver的createSqlSource()方法来完成.
private SqlSource buildSqlSourceFromStrings(String[] strings, Class<?> parameterTypeClass, LanguageDriver languageDriver){final StringBuilder sql = new StringBuilder();
// 拼接代码块
for (String fragment : strings) {
sql.append(fragment);
sql.append(" ");
}
// 解析成SqlSource
return languageDriver.createSqlSource(configuration, sql.toString().trim(), parameterTypeClass);
}
关于LanguageDriver的createSqlSource()方法在前面我们已经学过了,这里就不再赘述了.
至于SelectProvider系列注解的处理方式,则更为简单粗暴,将涉及到的SelectProvider系列注解和Mapper接口类型以及Mapper方法作为构造参数直接构造出一个ProviderSqlSource对象.
// 获取SqlProvider注解Annotation sqlProviderAnnotation = method.getAnnotation(sqlProviderAnnotationType);
// 创建ProviderSqlSource对象
returnnew ProviderSqlSource(assistant.getConfiguration(), sqlProviderAnnotation, type, method);
作为构造参数的Mapper接口类型以及Mapper方法在后续的调用中,将会用于创建ProviderContext对象.
此刻,再去回顾Mybatis源码之美:3.10.1.探究CRUD元素解析工作前的知识准备一文中关于ProviderContext对象的内容,是不是就感觉豁然开朗了呢.
回顾getSqlSourceFromAnnotations()方法的整体实现,该方法并不一定会返回SqlSource对象,在指定方法上无有效的注解时,该方法返回的是一个空对象.
如果该方法返回了空对象,这就意味着parseStatement()方法的后续代码不会执行!
解析Options注解获取基本参数配置
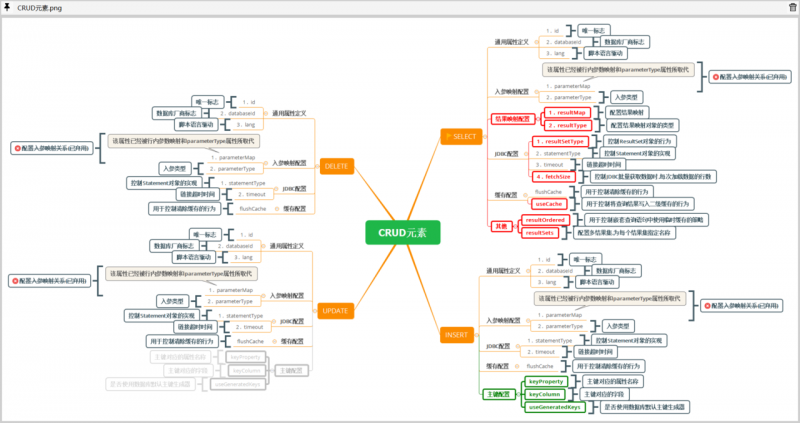
在前面的文章中,我们了解到构建一个MappedStatement对象,除了必要的SqlSource对象之外,还需要一些的额外的参数.
这些参数在XML文件中是通过CRUD元素的属性来提供的:
相应的,在基于注解的配置方式中,mybatis为我们提供了一系列额外的注解来完成类似的工作:
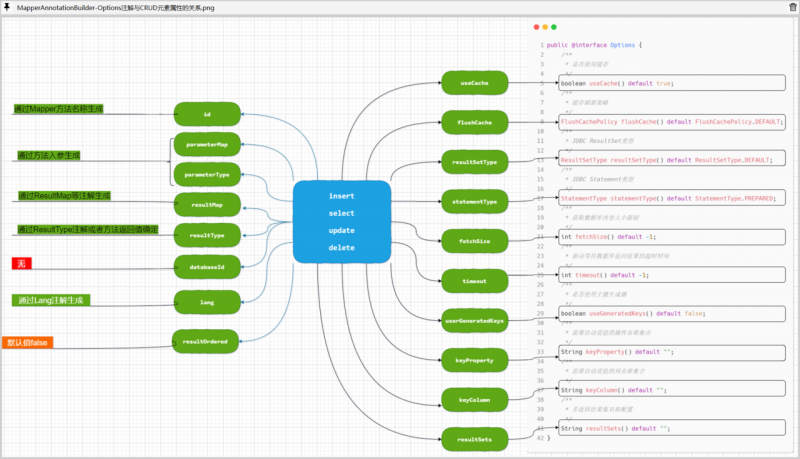
在这些注解中,相对比较复杂的是Options注解,该注解提供了较多的属性定义,来对标CRUD元素中的属性定义.
当然Options注解中的属性数量要远远低于CRUD元素中的属性定义,那些没有被体现出来的属性将会通过其他的方式来获取.
对于一个有效的Mapper方法定义来说,Options注解只是一个可选的注解,在实际的解析中,mybatis已经提供了大量的默认值来创建MappedStatement对象.
// 获取方法的属性设置Options options = method.getAnnotation(Options.class);
// 类名+方法名
final String mappedStatementId = type.getName() + "." + method.getName();
Integer fetchSize = null;
Integer timeout = null;
StatementType statementType = StatementType.PREPARED;
ResultSetType resultSetType = null;
// 获取SQl语句类型
SqlCommandType sqlCommandType = getSqlCommandType(method);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 非查询语句刷新缓存
boolean flushCache = !isSelect;
// 查询语句使用缓存
boolean useCache = isSelect;
KeyGenerator keyGenerator;
String keyProperty = null;
String keyColumn = null;
这些默认值的获取方式基本都是简单的赋值操作,只有sqlCommandType的取值是根据Select系列注解和SelectProvider系列注解的具体类型来决定的:
private SqlCommandType getSqlCommandType(Method method){Class<? extends Annotation> type = getSqlAnnotationType(method);
if (type == null) {
type = getSqlProviderAnnotationType(method);
if (type == null) {
return SqlCommandType.UNKNOWN;
}
if (type == SelectProvider.class) {
type = Select.class;
} elseif (type == InsertProvider.class) {
type = Insert.class;
} elseif (type == UpdateProvider.class) {
type = Update.class;
} elseif (type == DeleteProvider.class) {
type = Delete.class;
}
}
// 返回SQL命令类型
return SqlCommandType.valueOf(type.getSimpleName().toUpperCase(Locale.ENGLISH));
}
创建合适的KeyGenerator对象
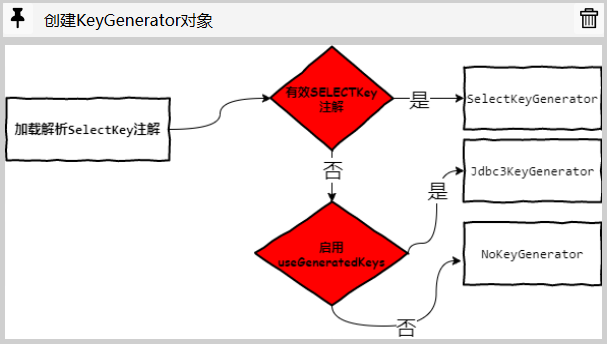
针对于insert和update类型的方法定义,parseStatement()还需要额外的进行KeyGenerator对象的创建工作.
在基于注解的配置方式中,mybatis提供了SelectKey注解来对标XML中insert|update元素的selectKey子元素:
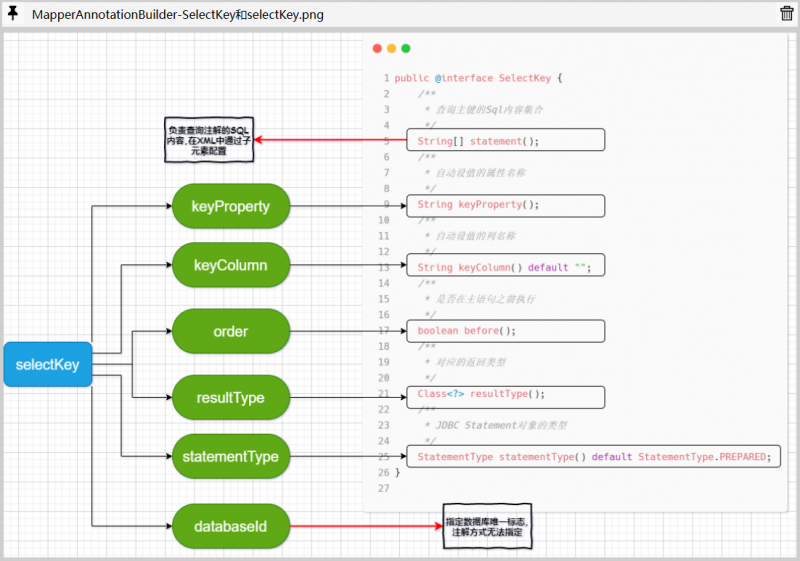
负责解析SelectKey注解的是handleSelectKeyAnnotation()方法,该方法的实现和解析XML中selectKey元素的过程差不多,通过解析SelectKey注解得到创建SelectKeyGenerator对象所需的属性,之后完成SelectKeyGenerator对象的创建工作:
private KeyGenerator handleSelectKeyAnnotation(SelectKey selectKeyAnnotation, String baseStatementId, Class<?> parameterTypeClass, LanguageDriver languageDriver){// 生成Key生成器的全局唯一标志
String id = baseStatementId + SelectKeyGenerator.SELECT_KEY_SUFFIX;
// 获取返回类型
Class<?> resultTypeClass = selectKeyAnnotation.resultType();
// 获取语句类型
StatementType statementType = selectKeyAnnotation.statementType();
// 获取指定的字段
String keyProperty = selectKeyAnnotation.keyProperty();
// 获取指定的列
String keyColumn = selectKeyAnnotation.keyColumn();
// 获取是否前置执行
boolean executeBefore = selectKeyAnnotation.before();
// defaults
// 是否使用缓存
boolean useCache = false;
// 默认不适用key生成器
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
// 返回结果集大小
Integer fetchSize = null;
// 请求超时时间
Integer timeout = null;
// 是否刷新缓存
boolean flushCache = false;
// 对应的参数映射集合
String parameterMap = null;
// 对应的响应映射集合
String resultMap = null;
// 返回集合的类型
ResultSetType resultSetTypeEnum = null;
// 根据SelectKey构建SqlSource
SqlSource sqlSource = buildSqlSourceFromStrings(selectKeyAnnotation.statement(), parameterTypeClass, languageDriver);
// SQL类型为查询
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
// 添加声明语句
assistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum,
flushCache, useCache, false,
keyGenerator, keyProperty, keyColumn, null, languageDriver, null);
// 合并命名空间
id = assistant.applyCurrentNamespace(id, false);
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
// 构建SELECT Key
SelectKeyGenerator answer = new SelectKeyGenerator(keyStatement, executeBefore);
// 注册到全局
configuration.addKeyGenerator(id, answer);
return answer;
}
如果用户没有配置SelectKey注解,那么创建何种KeyGenerator实例将取决于useGeneratedKeys属性,该属性可以通过Options注解和mybatis全局配置文件来提供,Options注解的优先级要更高一些.
调整缓存处理策略等属性
创建了KeyGenerator对象之后,parseStatement()方法将会使用Options注解中的属性配置替换部分属性的默认值.
其中主要包括缓存的处理策略,请求超时时间,statementType以及resultSetType,这一过程相对比较简单:
if (options != null) {if (FlushCachePolicy.TRUE.equals(options.flushCache())) {
flushCache = true;
} elseif (FlushCachePolicy.FALSE.equals(options.flushCache())) {
flushCache = false;
}
useCache = options.useCache();
fetchSize = options.fetchSize() > -1 || options.fetchSize() == Integer.MIN_VALUE ? options.fetchSize() : null; //issue #348
timeout = options.timeout() > -1 ? options.timeout() : null;
statementType = options.statementType();
resultSetType = options.resultSetType();
}
加载ResultMap对象
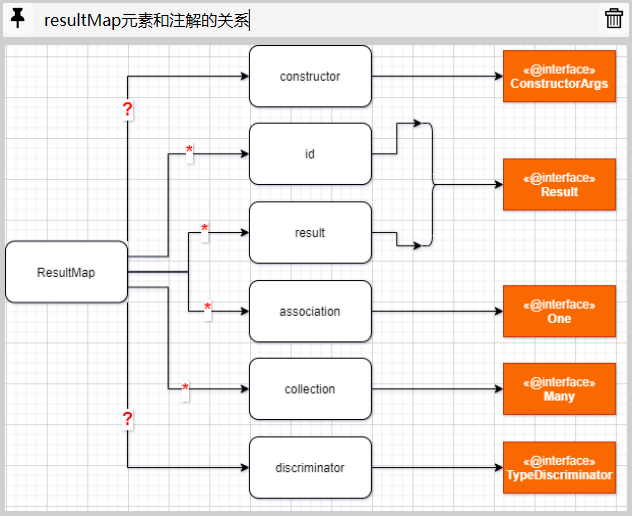
和基于XML提供SQL配置不同的是,基于注解提供SQL配置时,可以选择使用ResultMap注解引用现有的ResultMap配置,也可以通过ConstructorArgs,Results以及TypeDiscriminator等注解提供全新的ResultMap配置.
ResultMap注解的作用和CRUD元素中的resultMap属性基本保持一致,他提供了一个String数组类型的属性value(),该属性的作用是记录一组ResultMap对象的唯一标志,这组唯一标志将会在后面的解析过程中被转换成对应的ResultMap对象:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public@interface ResultMap {
String[] value();
}
通过注解配置一个全新ResultMap对象的过程,涉及到的注解相对较多一些,参照着XML文件中的resultMap元素,我们来一一了解这些注解.
首先是下面这张整体结构图,他描述了XML元素和注解之间的对应关系:
ConstructorArgs注解
首先是用于配置返回对象构造方法的constructor元素,和他拥有一样功能的是ConstructorArgs注解.
根据constructor元素的DTD定义来看;
<!ELEMENTconstructor (idArg*,arg*)>constructor元素下可以有多个idArg和arg子元素,这两个子元素的DTD定义完全一致:
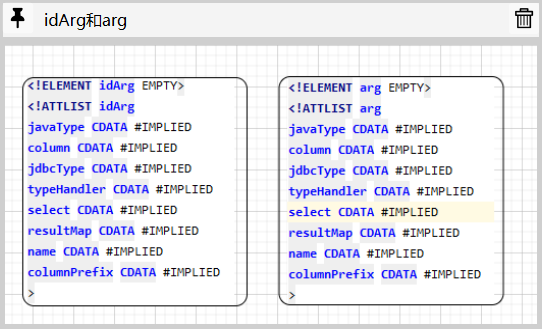
他们的主要区别就是被idArg修饰的属性将会作为ID属性存在.
鉴于idArg和arg的属性定义基本一致,因此在ConstructorArgs注解下只有一个名为Arg的注解:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public@interface ConstructorArgs {
Arg[] value() default {};
}
该注解通过一个id()属性来区分相应的属性配置是否为ID属性:
![[idArg元素/arg元素]和Arg注解的关系](/wp-content/uploads/2020/06/1727928b9156f9b6.png)
Arg注解中的属性定义基本和idArg/arg元素的属性定义是一一对应的:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target({})
public@interface Arg {
booleanid()defaultfalse;
String column()default "";
Class<?> javaType() defaultvoid.class;
JdbcType jdbcType()default JdbcType.UNDEFINED;
Class<? extends TypeHandler> typeHandler() default UnknownTypeHandler.class;
String select()default "";
String resultMap()default "";
String name()default "";
/**
* @since 3.5.0
*/
String columnPrefix()default "";
}
对应关系:
![[idArg元素/arg元素]和Arg注解的属性对应关系](/wp-content/uploads/2020/06/1727928ba04493d4.png)
Results注解
除了配置构造参数的idArg和arg元素之外,resultMap元素还有用于配置常规属性定义的id和result两个子元素,和idArg同arg的关系类似,id和result也具有完成相同的属性定义,不同之处只在于使用id元素配置属性是ID属性:
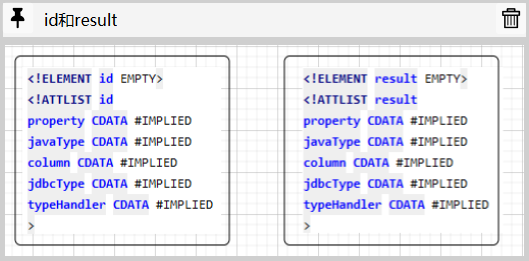
因此,myabtis基于代码复用的原则,只提供了一个Result注解,来对标这两个子元素:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target({})
public@interface Result {
booleanid()defaultfalse;
String column()default "";
String property()default "";
Class<?> javaType() defaultvoid.class;
JdbcType jdbcType()default JdbcType.UNDEFINED;
Class<? extends TypeHandler> typeHandler() default UnknownTypeHandler.class;
One one()default @One;
Many many()default @Many;
}
细看Result注解的定义,可以发现除了和id/result元素对应的属性之外,Result注解还额外提供了id(),one()以及many()三个属性,其中id()用来区分id和result类型,one()则对应着association元素,many()对应着collection元素.
注解One和Many的定义基本一致:
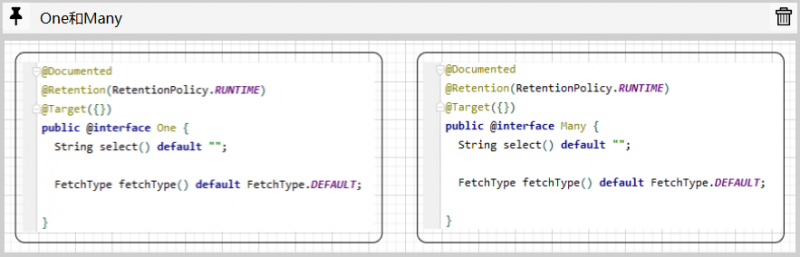
其中select()用于引用一个现有的select元素配置,fetchType则用于控制懒加载的行为.
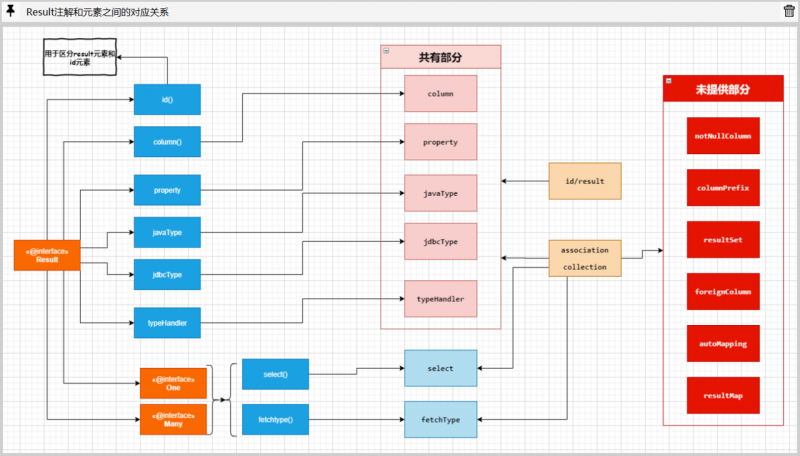
这时候,我们再回头去看association元素和collection元素的DTD定义,可以很轻易的发现,相对于XML配置而言,注解配置只能提供有限的复杂对象映射的能力:
当然,鉴于java8才开始支持重复注解功能,因此mybatis额外提供了一个Results注解,该注解用来持有多个Result注解,并提供了一个id()属性用来配置当前ResultMap对象的唯一标志:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public@interface Results {
/**
* The name of the result map.
*/
String id()default "";
Result[] value() default {};
}
TypeDiscriminator注解
和discriminator元素相对应的注解是TypeDiscriminator:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public@interface TypeDiscriminator {
String column();
Class<?> javaType() defaultvoid.class;
JdbcType jdbcType()default JdbcType.UNDEFINED;
Class<? extends TypeHandler> typeHandler() default UnknownTypeHandler.class;
Case[] cases();
}
该注解的属性定义和discriminator元素的定义一一对应:
<!ELEMENTdiscriminator (case+)><!ATTLISTdiscriminator
columnCDATA #IMPLIED
javaTypeCDATA #REQUIRED
jdbcTypeCDATA #IMPLIED
typeHandlerCDATA #IMPLIED
>
discriminator元素有一个case子元素定义,相应的TypeDiscriminator提供了一个Case注解.
在TypeDiscriminator中名为cases()的属性,用于维护一组Case注解,Case注解的定义也十分简单,基本保持着case元素的对应关系:
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target({})
public@interface Case {
String value();
Class<?> type();
Result[] results() default {};
Arg[] constructArgs() default {};
}
稍有不同的是,case子元素中的resultMap属性被拆分为了results和constructor两个属性定义:
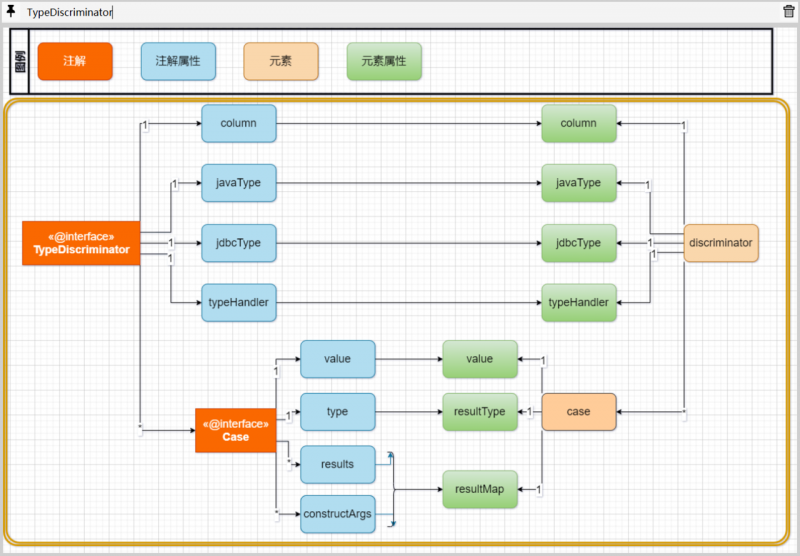
当然,认真对比查看case元素的dtd定义:
<!ELEMENTcase (constructor?,id*,result*,association*,collection*, discriminator?)><!ATTLISTcase
valueCDATA #REQUIRED
resultMapCDATA #IMPLIED
resultTypeCDATA #IMPLIED
>
我们可以发现Case注解也只提供了case元素中的部分能力.
在了解了XML配置和注解配置中关于配置ResultMap工作的关联关系之后,我们来看一下注解配置的具体解析工作.
在parseStatement()方法中,解析ResultMap对象的过程主要就是获取ResultMap对象唯一标志的过程.
// 解析ResultMapString resultMapId = null;
// 获取方法上的ResultMap注解,ResultMap注解优先级高于Results和ConstructorArgs。
ResultMap resultMapAnnotation = method.getAnnotation(ResultMap.class);
if (resultMapAnnotation != null) {
String[] resultMaps = resultMapAnnotation.value();
StringBuilder sb = new StringBuilder();
for (String resultMap : resultMaps) {
if (sb.length() > 0) {
sb.append(",");
}
sb.append(resultMap);
}
resultMapId = sb.toString();
} elseif (isSelect) {
// 如果查询语句没有指定ResultMap,根据方法返回类型自动生成ResultMap
resultMapId = parseResultMap(method);
}
通过注解配置ResultMap对象有两种方式,一种是通过ResultMap注解直接指定被引用的ResultMap集合,另一种方式就是通过ConstructorArgs等注解配置全新的ResultMap对象集合.
其中关于ResultMap注解的解析工作相对比较简单,主要就是获取ResultMap注解中的value()值集合,并将集合中的每个值视为一个有效ResultMap对象的引用.
而通过ConstructorArgs等注解配置ResultMap对象的过程,相对较复杂一些,实现逻辑主要在parseResultMap()方法中,需要注意的是两种方式里ResultMap注解的优先级较高一些.
在忽略掉parseResultMap()方法实现细节的前提下,当parseStatement()方法拿到有效的ResultMap引用标志之后,就会利用上述过程中得到的有效数据作为参数传递给MapperBuilderAssistant对象的addMappedStatement()方法完成MappedStatement对象的创建和注册工作.
现在我们回头看一下parseResultMap()方法的实现:
private String parseResultMap(Method method){// 获取方法的返回类型
Class<?> returnType = getReturnType(method);
// 获取方法上的ConstructorArgs注解
ConstructorArgs args = method.getAnnotation(ConstructorArgs.class);
// 获取方法上的Results注解
Results results = method.getAnnotation(Results.class);
// 获取方法上的TypeDiscriminator注解
TypeDiscriminator typeDiscriminator = method.getAnnotation(TypeDiscriminator.class);
// 生成ResultMap的名称
String resultMapId = generateResultMapName(method);
// 应用并注册当前ResultMap
applyResultMap(resultMapId, returnType, argsIf(args), resultsIf(results), typeDiscriminator);
// 返回生成的ResultMap的名称
return resultMapId;
}
parseResultMap()方法的主要作用就是加载方法上的有效注解,创建该方法对应的ResultMap对象并返回相应的resultMapId.
生成resultMapId的工作是generateResultMapName()方法来完成的,创建注册ResultMap对象的工作是applyResultMap()方法完成的.
我们先看generateResultMapName()方法的实现:
private String generateResultMapName(Method method){// 获取Results注解
Results results = method.getAnnotation(Results.class);
if (results != null && !results.id().isEmpty()) {
// 构建本对象中的唯一标志
return type.getName() + "." + results.id();
}
StringBuilder suffix = new StringBuilder();
for (Class<?> c : method.getParameterTypes()) {
// 通过方法参数构建
suffix.append("-");
suffix.append(c.getSimpleName());
}
if (suffix.length() < 1) {
// 构建-void参数
suffix.append("-void");
}
// 生成类名+.+方法名+参数的唯一标志
return type.getName() + "." + method.getName() + suffix;
}
整个方法的实现原理比较简单,优先使用Results注解的id()属性作为resultMapId,如果不存在,那就使用类名+方法名+参数列表自动生成resultMapId.
applyResultMap()方法的实现也不算复杂,依次处理了创建构造方法的Arg注解,普通属性配置的Result注解,以及鉴别器对象TypeDiscriminator注解:
privatevoidapplyResultMap(String resultMapId, Class<?> returnType, Arg[] args, Result[] results, TypeDiscriminator discriminator){List<ResultMapping> resultMappings = new ArrayList<>();
// 处理构造参数
applyConstructorArgs(args, returnType, resultMappings);
// 处理ResultMap
applyResults(results, returnType, resultMappings);
// 处理鉴别器
Discriminator disc = applyDiscriminator(resultMapId, returnType, discriminator);
// 构建ResultMap
// TODO add AutoMappingBehaviour
assistant.addResultMap(resultMapId, returnType, null, disc, resultMappings, null);
// 创建包含鉴别器的ResultMap
createDiscriminatorResultMaps(resultMapId, returnType, discriminator);
}
整个方法的实现过程实际上和处理XML配置时差不多,负责处理Arg注解的applyConstructorArgs() 方法将每一个Arg注解都转换成了对应的ResultMapping对象:
privatevoidapplyConstructorArgs(Arg[] args, Class<?> resultType, List<ResultMapping> resultMappings){for (Arg arg : args) {
// 遍历处理每一个构造参数
List<ResultFlag> flags = new ArrayList<>();
// 添加resultMap的构造参数标志
flags.add(ResultFlag.CONSTRUCTOR);
if (arg.id()) {
// 添加ResultMap的ID标志
flags.add(ResultFlag.ID);
}
// 获取类型转换处理器
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandler = (Class<? extends TypeHandler<?>>)
(arg.typeHandler() == UnknownTypeHandler.class ? null : arg.typeHandler());
// 解析成ResultMap
ResultMapping resultMapping = assistant.buildResultMapping(
resultType,
nullOrEmpty(arg.name()),
nullOrEmpty(arg.column()),
arg.javaType() == void.class ? null : arg.javaType(),
arg.jdbcType() == JdbcType.UNDEFINED ? null : arg.jdbcType(),
nullOrEmpty(arg.select()),
nullOrEmpty(arg.resultMap()),
null,
nullOrEmpty(arg.columnPrefix()),
typeHandler,
flags,
null,
null,
false);
resultMappings.add(resultMapping);
}
}
负责处理Result注解的applyResults() 方法同样是将每个Result注解都转换成了对应的ResultMapping对象:
privatevoidapplyResults(Result[] results, Class<?> resultType, List<ResultMapping> resultMappings){for (Result result : results) {
// 遍历处理每一个字段的定义
List<ResultFlag> flags = new ArrayList<>();
if (result.id()) {
flags.add(ResultFlag.ID);
}
// 获取类型转换处理器
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandler = (Class<? extends TypeHandler<?>>)
((result.typeHandler() == UnknownTypeHandler.class) ? null : result.typeHandler());
ResultMapping resultMapping = assistant.buildResultMapping(
resultType,
nullOrEmpty(result.property()),
nullOrEmpty(result.column()),
result.javaType() == void.class ? null : result.javaType(),
result.jdbcType() == JdbcType.UNDEFINED ? null : result.jdbcType(),
hasNestedSelect(result) ? nestedSelectId(result) : null,
null,
null,
null,
typeHandler,
flags,
null,
null,
isLazy(result));
resultMappings.add(resultMapping);
}
}
负责处理TypeDiscriminator注解的applyDiscriminator()方法简单的利用TypeDiscriminator注解中的属性创建并注册了相应的Discriminator对象:
private Discriminator applyDiscriminator(String resultMapId, Class<?> resultType, TypeDiscriminator discriminator){if (discriminator != null) {
// 获取鉴别器处理时依据的列名称
String column = discriminator.column();
// 获取java类型
Class<?> javaType = discriminator.javaType() == void.class ? String.class : discriminator.javaType();
// 获取jdbc类型
JdbcType jdbcType = discriminator.jdbcType() == JdbcType.UNDEFINED ? null : discriminator.jdbcType();
// 获取对应的类型转换处理器
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandler = (Class<? extends TypeHandler<?>>)
(discriminator.typeHandler() == UnknownTypeHandler.class ? null : discriminator.typeHandler());
// 获取鉴别器的分支集合
Case[] cases = discriminator.cases();
Map<String, String> discriminatorMap = new HashMap<>();
// 处理分支
for (Case c : cases) {
String value = c.value();
// 生成分支语句的唯一标志
String caseResultMapId = resultMapId + "-" + value;
discriminatorMap.put(value, caseResultMapId);
}
// 生成鉴别器
return assistant.buildDiscriminator(resultType, column, javaType, jdbcType, typeHandler, discriminatorMap);
}
returnnull;
}
但是这一过程,并不包含Case注解的转换处理工作.
在完成了对上述涉及到的注解的处理工作之后,applyResultMap()方法就会调用MapperBuilderAssistant对象的addResultMap()方法完成ResultMap对象的创建工作.
最后再调用createDiscriminatorResultMaps()方法解析TypeDiscriminator的Case子注解,完成内嵌ResultMap对象的创建工作:
privatevoidcreateDiscriminatorResultMaps(String resultMapId, Class<?> resultType, TypeDiscriminator discriminator){if (discriminator != null) {
for (Case c : discriminator.cases()) {
// 处理鉴别器的每一个分支
// 生成鉴别器唯一标志
String caseResultMapId = resultMapId + "-" + c.value();
List<ResultMapping> resultMappings = new ArrayList<>();
// issue #136
// 处理内部的ConstructorArgs
applyConstructorArgs(c.constructArgs(), resultType, resultMappings);
// 处理嵌套的Results
applyResults(c.results(), resultType, resultMappings);
// TODO add AutoMappingBehaviour
// 添加一个ResultMap
assistant.addResultMap(caseResultMapId, c.type(), resultMapId, null, resultMappings, null);
}
}
}
从本质上来讲,解析XML配置的过程和注解配置的过程是十分相似的,因此,在了解了XML配置的解析工作之后,相对而言,解析注解配置的过程应该十分容易理解.
至此,我们算是完成了整个Mybatis源码之美系列博文的前半部分---mybatis运行环境的准备工作.
在后面的文章中,我们将开始逐渐深入到mybatis的调用过程中,查缺补漏,逐渐完善整个mybatis的知识体系.
学习任重而道远,加油!
以上是 Mybatis源码Mapper接口定义 的全部内容, 来源链接: utcz.com/a/20475.html