『前端面试100问』之浏览器从输入URL到页面展示发生了什么
『浏览器从输入URL到页面渲染发生了什么』作为一个经典题目,在前端面试中高频出现,很多大厂的面试都会从这个面试题出发,考察候选人对知识的掌握程度,这其中涉及到了网络、操作系统、Web等一系列的知识,很多同学认为只需要掌握一个大概,能够把流程说下来就可以了,实际上不是,面试官期望的是系统而全面的回答。
那么,如果你还不能『系统而全面』地回答这个问题,就跟我一起来梳理一下吧
1.浏览器进程
首先需要明确,浏览器是多进程的,以Chrome浏览器为例,Chrome有5个进程,这5个进程以及各自的功能分别是:
- 浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储等功能
- 渲染进程:核心任务是将 HTML、CSS 和 JavaScript转换为用户可以与之交互的网页
- 网络进程:负责页面的网络资源加载
- GPU进程:绘制UI界面
- 插件进程:负责插件的运行
2.页面展示过程
从用户输入信息到页面展示的不同阶段,是不同的进程在发挥作用,示意图如下:
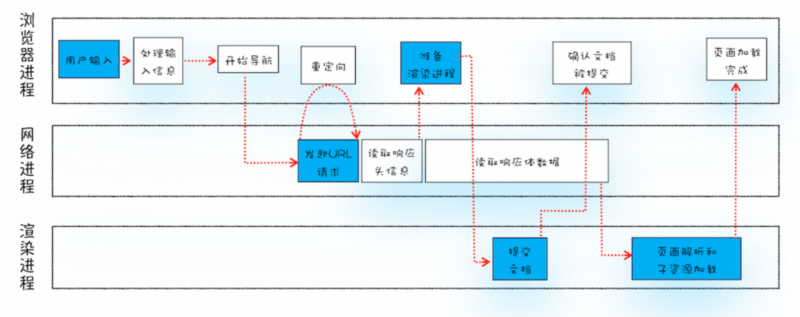
从图中可以看出,整个过程是需要各个进程之间相互配合完成的,过程大致可以描述为:
- 首先用户在浏览器进程里输入请求信息;
- 然后网络进程发起URL请求;
- 服务器相应URL请求之后,浏览器进程开始准备渲染进程
- 渲染进程准备好之后,网络进程向渲染进程提交页面数据,此时处于提交文档阶段,渲染进程接收完毕之后,便开始解析页面和加载子资源,完成页面渲染
这其中,用户发起URL请求到页面开始解析的这个过程,就叫做导航,而导航过程中发生的事情,就构成了本文开头提到的那道经典的面试题。
3.具体过程
3.1 从输入URL到页面展示
首先用户从地址栏输入一个查询关键字,地址栏会判断关键字是搜索内容,还是URL:
1. 如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的URL2.如果输入内容符合URL规则,那么地址栏会根据规则,把这段内容加上协议,合成完整的URL
用户输入完毕并键入回车之后,浏览器就进入加载状态:
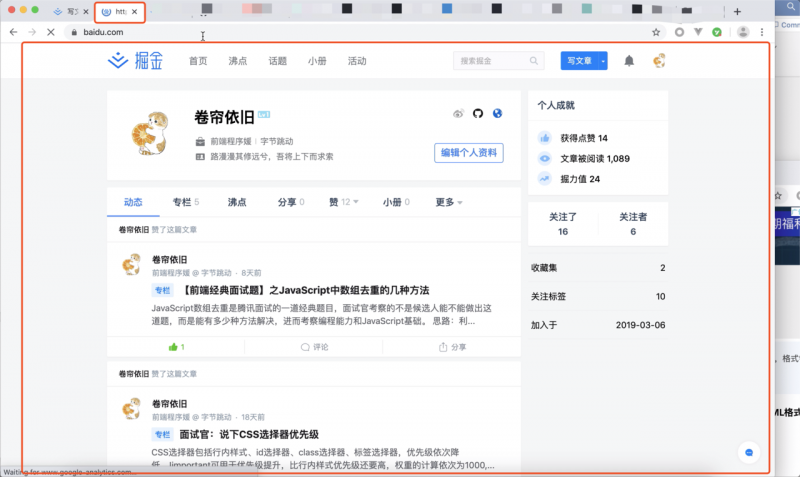
从图中可以看出,当浏览器刚开始加载一个地址之后,标签页上的图标便进入了加载状态。但此时图中页面显示的依然是之前打开的页面内容,并没立即替换为百度首页的页面。因为需要等待提交文档阶段,页面内容才会被替换。
3.2 URL请求过程
接下来,开始进入页面资源请求过程,这时候,浏览器进程会通过进程间通信(IPC)把URL请求发送到网络进程,网络进程接收到URL请求后,会发起真正的URL请求:
1.查找浏览器缓存网络进程会查找本地缓存是否缓存了该资源,如果有缓存资源,那么会直接返回资源给浏览器进程;
如果缓存中没有查找到资源,那么直接进入网络请求流程;
2.DNS解析
之后就要进行DNS解析,以获取请求域名的服务器IP地址,
如果请求协议是HTTPS,那么还需要建立TLS连接
3.TCP连接
接下来就是利用IP地址和服务器建立TCP连接。连接建立之后,浏览器会构建请求行、请求头等信息,
并把和该域名相关的Cookie等数据附加到请求头中,然后向服务器发送构建的请求信息。
4.服务器相应
服务器收到请求信息之后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),
发送给网络进程。网络进程接收了响应行和响应头信息之后,就开始解析响应头的内容了
网络进程解析响应行和响应头信息的过程:
4.1 重定向
如果响应行状态码为301或302,那么说明服务器需要浏览器重定向到其它URL,这时候网络进程会从
响应头的 Location 字段里面读取重定向的地址,然后再发起网络请求(http或https),重新开始
请求。
关于重定向状态码的补充:
301:永久重定向
302:临时重定向
4.2响应数据类型处理
跳转信息处理完毕,继续导航流程分析:
URL请求的数据类型,有时候是下载类型,有时候是HTML页面,那么浏览器怎么区分呢?
答案是通过 Content-Type 字段。Content-Type是HTTP头部中的重要字段,它告诉浏览器服务器
返回的响应体数据是什么类型,然后浏览器会根据Content-Type的值来决定如何显示响应体的内容。
比如Content-Type的值是application/octet-stream,通常情况下,浏览器会按照下载类型来
处理该请求,该请求被提交给浏览器的下载管理器,同时该URL请求的导航流程就此结束;如果
Content-Type字段的值是text/html,这就是告诉浏览器,服务器返回的数据是HTML格式,浏览器
会继续导航流程,接下来渲染进程登场了。
3.准备渲染进程
默认情况下,Chrome会为每个页面分配一个渲染进程,也就是说,每打开一个新页面就会创建一个新的渲染进程。但是如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。
同一站点:根域名+协议相同,就属于同一站点
渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,所以下一步就进入了提交文档阶段。
4.提交文档
『文档』是指URL请求的响应体数据,“提交文档”的消息是由浏览器进程发出的,渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”。
等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程。 浏览器进程在收到“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
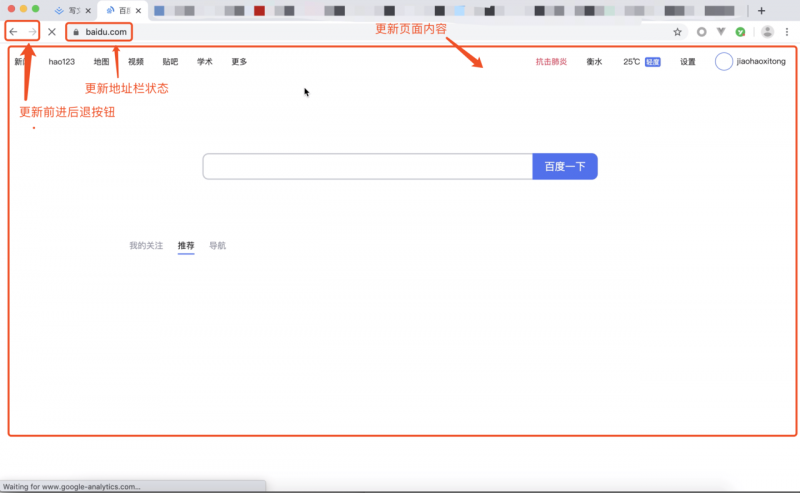
到这里,导航流程就结束了,之后进入渲染阶段。
5.渲染阶段
一旦文档被提交,渲染进程便开始页面解析和子资源加载了,一旦页面生成完成,渲染进程会发送一个消息给浏览器进程,浏览器接收到消息后,会停止标签图标上的加载动画,渲染流程大致可以描述为如下阶段:
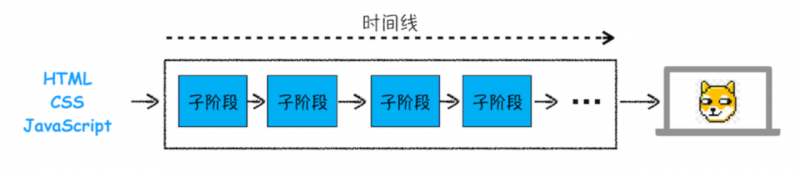
即流水线式的渲染,当然这是简化后的描述,实际上渲染机制是很复杂的。
按照渲染的时间顺序,流水线可以分为以下子阶段:构建DOM树、样式计算、布局阶段、分层、绘制、分块、光栅化和合成
5.1 DOM生成
浏览器无法直接理解和使用 HTML,所以需要将HTML 转换为浏览器能够理解的结构—DOM 树,DOM树的构建过程可以参考下图:
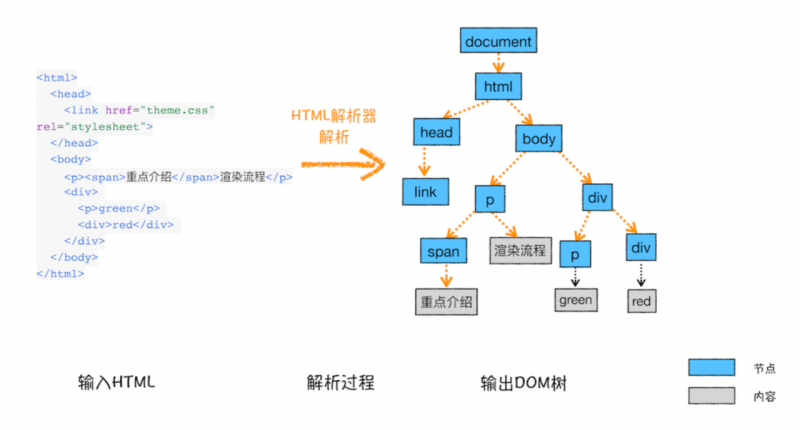
5.2 样式计算
这个阶段的目的是计算出DOM节点中每个元素的具体样式,渲染引擎会将接收到 CSS 文本转换为浏览器可以理解的结构—— styleSheets,在Chrome控制台中查看其结构,可以看到下图所示的结构
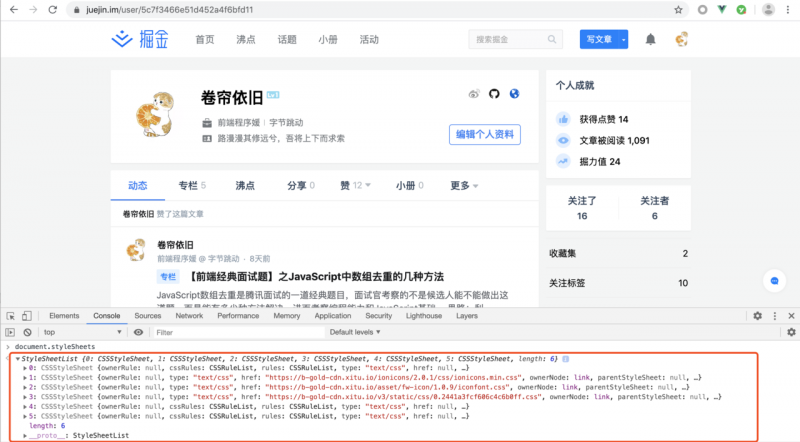
接下来渲染进程就会进行属性值标准化,也就是将所有值转换为渲染引擎容易理解的、标准化的计算值,从下图可以看出,2em被解析成了32px,red 被解析成了 rgb(255,0,0),bold 被解析成了700
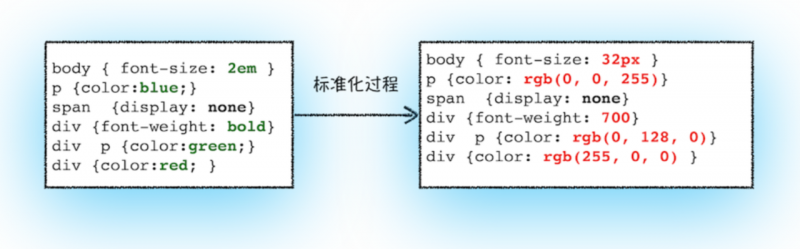
之后会根据CSS的继承规则和层叠规则计算DOM树中每个节点的样式属性。
5.3 布局
此时,我们已经获取了DOM树和DOM树中元素的样式,但还并不知道DOM元素的几何位置信息,接下来就需要计算出 DOM 树中可见元素的几何位 置,这个计算过程叫做布局。具体过程为:
5.3.1 创建布局树渲染进程会根据DOM树和ComputedStyle(计算样式)生成一棵布局树,树中的节点描述节点的样式和
父子关系,需要注意的是,不可见元素不会被包含进布局树。
5.3.2 布局计算
布局的过程描述起来也是很复杂的,因为页面中有很多复杂的效果,如一些复杂的 3D 变换、页面
滚动,或者使用 z-indexing 做z轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定
的节点生成专用的 图层,并生成一棵对应的图层树(LayerTree)
(1)分层
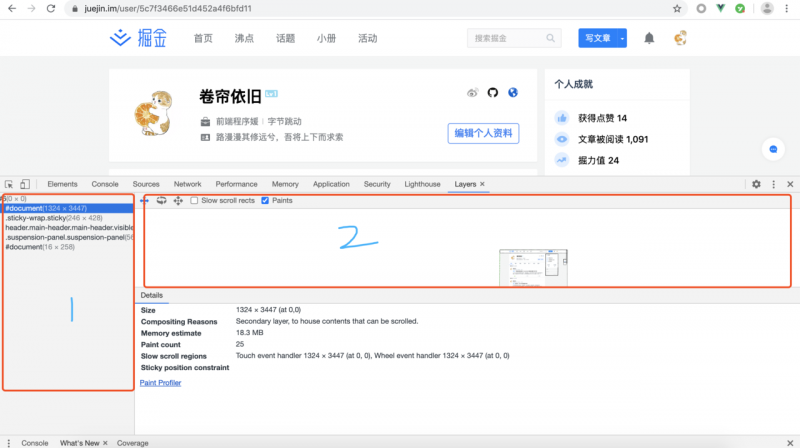
通过 Chrome 的『开发者工具』-> 『Layers』就可以可视化页面的分层情况,如下图所示:
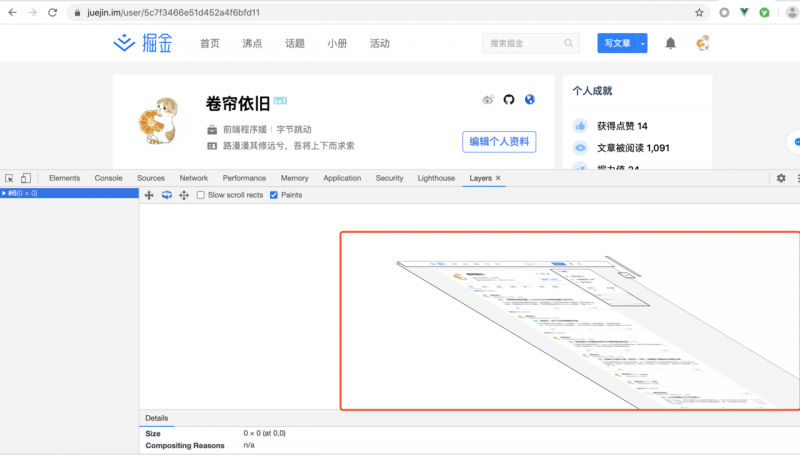
现在我们知道浏览器的页面实际上被分成了很多图层,这些图层叠加后合成了最终的页面图层和布局树节点之间的关系,如下图所示:
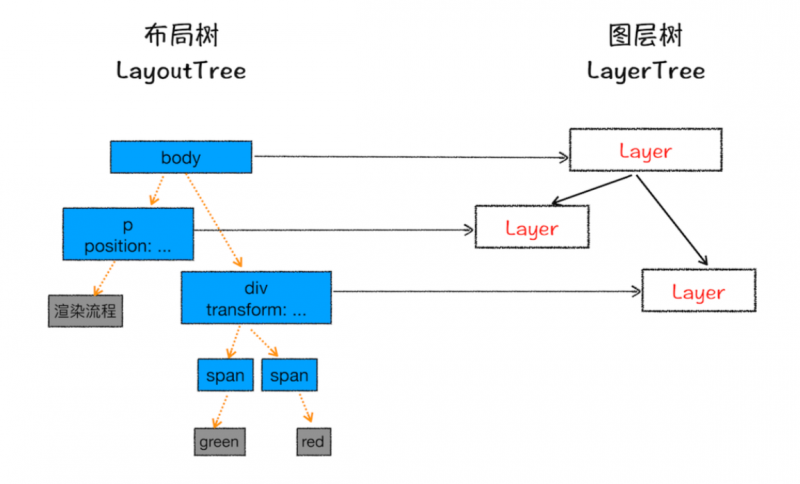
通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么 这个节点就从属于父节点的图层。
通常满足下面两点中任意一点的元素就可以被提升为单独的一个图层:1.拥有层叠上下文属性
比如position为absolute,设置了opacity、filter属性的元素
2.需要裁剪的地方
(2)图层绘制渲染引擎实现图层的绘制与之类似,会把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令
按照顺序组成一个待绘制列表,如下图所示:
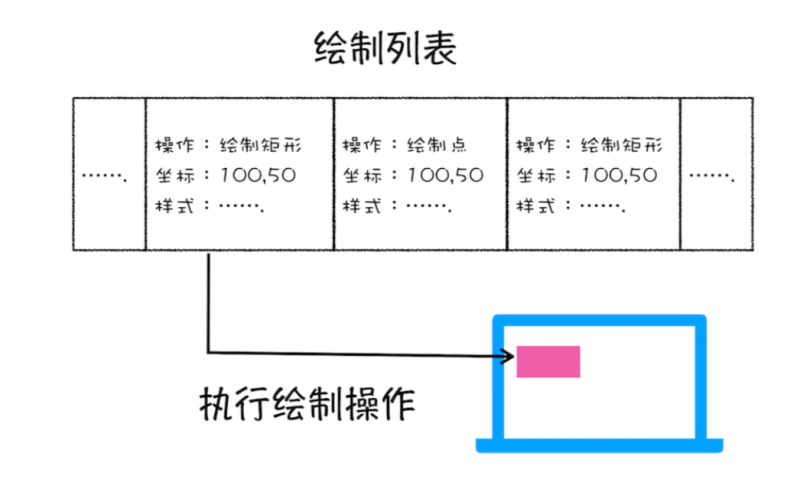
从图中可以看出,绘制列表中的指令其实非常简单,就是让其执行一个简单的绘制操作,比如绘制粉色矩形或者黑色的线等。而绘制一个元素通常需要好几条绘制指令,因为每个元素的背景、前景、边框都
需要单独的指令去绘制。所以在图层绘制阶段,输出的内容就是这些待绘制列表。
通过『开发者工具』-> 『Layers』,选择『document』,可以实际体验下绘制列表,如下图所示:
(3)删格化操作绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来
完成的。通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分
叫做视口(viewport),在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久
才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所
有图层内容的话,就会产生太大的开销,而且也没有必要。基于这个原因,合成线程会将图层划分为
图块(tile),然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格
化来执行的。所谓栅格化,是指将图块转换为位图,通常,栅格化过程都会使用 GPU 来加速生成,
使用 GPU 生成位图的过程叫快速栅格化, 或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
(4)合成和显示
一旦所有图块都被光栅化,合成线程就会生成一个绘制图块的命令——“DrawQuad”, 然后将该命令
提交给浏览器进程。浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的
DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在
屏幕上。
总结:
到这里,经过这一系列的阶段,页面最终会显示在浏览器上,整个加载和解析过程是浏览器的各进程间相互配合完成的,需要注意:
1.网络进程发起请求之后会先判断本地是否有缓存;
2.DNS解析过程会判断DNS缓存,如果是HTTPS协议,还会进行TLS连接;
3.浏览器进程、网络进程、渲染进程是主力;
4.图层的删格化过程用到了 GPU 加速
5.网络进程和渲染进程间的通信用到了进程间通信(IPC)
❤️❤️❤️
最后我想说,如果这篇文章对你有帮助,那就请你帮我三个小忙:
1.点个赞❤️,使这篇文章让更多的人看到
2.关注公众号「我是前端喵」,定期为你推送精选好文,上下班路上看一看,有用的知识不知不觉就增加了😊😊😊
3.向你的朋友推荐「我是前端喵」,一起进步吧🌞🌞🌞
以上是 『前端面试100问』之浏览器从输入URL到页面展示发生了什么 的全部内容, 来源链接: utcz.com/a/20238.html