ThreadDump性能瓶颈分析
一、回顾
在前面我们了解了ThreadDump的查看方式,也大概了解了其能够做些什么,下面我们来继续探讨这个问题,不了解的同学回顾下以前的资料
ThreadDump分析笔记(一) 解读堆栈
ThreadDump分析笔记(二) 分析堆栈
二、瓶颈在哪里
改善资源也就是我们常说的性能优化,改善也就是需要在有限的资源内去做更多的事情。线程的运行因某个特定资源受阻时,我们称之为受限于该资源比如受限于数据库,受限于对端的处理能力等。
其实利用并发来提高系统性能,就是意味着我们要使CPU尽可能的处于忙碌的状态。如果程序受限于当前CPU的计算能力,那我们通过增加处理器或者集群就可以解决问题了。但如果不能的利用CPU,使其处于忙碌状态,那么增加处理器也没是无济于事的。所以要充分的使用多线程,使空闲的处理器进行未完成的工作。
总体来说,性能提高,就是要解决受限资源,受限资源可能是:
CPU
如果当前CPU已经能够接近100%的利用率,并且代码业务逻辑无法再简化,那么说明 该系统的已经达到了性能最大化,如果再想提高性能,只能增加处理器或者集群。
其他资源
如数据库连接数量等,如果CPU利用率没有接近100%,那么通过修改代码尽量提高CPU的使用率,那么整体性能也会获得极大提高。
下面我们来看一张图,随着系统压力增大,但CPU使用率无法趋近于100%,如图
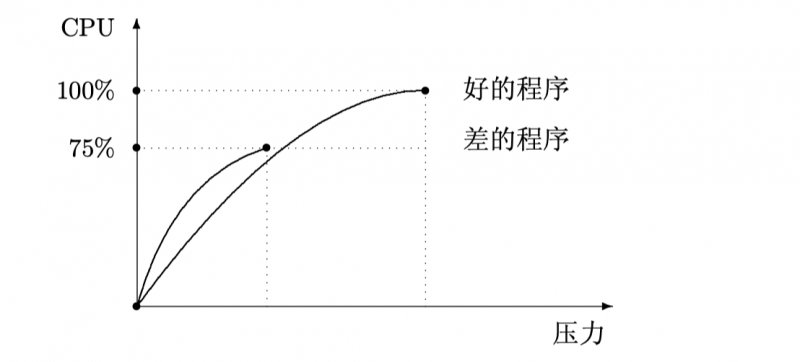
如果在单CPU机器上无论多大压力的情况下都无法令CPU使用率趋近于100%,那就说明这个程序还是有优化的空间的。一个系统性能瓶颈的分析过程大致如下:
- 先进行单流程的性能瓶颈分析,首先让单流程的性能达到最优。(可以通过硬编码增加时间戳来找出哪里耗时最多,这种没啥技巧,可具体问题具体分析)
- 进行整体性能瓶颈分析(这次的重点)
话说什么是高性能?其实高性能在不同的场景下有不同的概念:
- 有的场合高性能意味着用户速度的体验,如界面操作,点击一个菜单,响应很快我们就说性能很高
- 有的场合,高吞吐量意味着高性能,如短信,系统更看重吞吐量,而对每一个消息的处理时间不敏感
- 有的场合,是二者的结合,不但要求系统有很大的吞吐量,还要求每个消息在指定的时间内完成处理,不允许有延迟
性能调优的终极目标是:系统的CPU利用率接近100%.如果你的CPU没有被充分利用,那 么有如下几个可能:
施加的压力不足
可能是应用程序没有足够的负载,这时可以增加其压力,观察系统的响应时间,服务失败率,和CPU的使用率情况。如果增加压力,系统开始出现部分服务失败,系统的响应时间变慢,或者CPU的使用率无法再上升,那么此时的 压力应该是系统的饱和压力。即此时的能力是系统当前的最大能力。
系统存在瓶颈
当系统在饱和压力下,如果CPU的使用率没有接近100%,那么说明这个系统的 性能还有提升的空间。
系统存在瓶颈的几种表现:
- 持续运行缓慢。(时常发现应用程序运行缓慢,通过改变负载量、数据库连接数等也无法有效提升整体响应时间)
- 系统性能随时间的增加逐渐下降。(在负载稳定的情况下,系统运行时间越长速度越慢。可能是由于超出某个阈值范围,系统运行频繁出错从而导致系统死锁或崩溃)
- 系统性能随负载的增加逐渐下降(随着用户数目的增多,运行越发缓慢。若干个用户退出系统后,程序便能够恢复正常运行状态)
下面就来说说常见的集中性能瓶颈
三、几种常见的性能瓶颈
不恰当的同步导致的资源争用
- sychronized使用不当导致,不相关的方法用了同一锁或者不同的共享变量用了同一把锁,造成无谓的资源竞争。
class MyClass {Object sharedObj;
synchronized void fun1() {...} //访问共享变量sharedObj
synchronized void fun2() {...} //访问共享变量sharedObj
synchronized void fun3() {...} //不访问共享变量sharedObj
synchronized void fun4() {...} //不访问共享变量sharedObj
synchronized void fun5() {...} //不访问共享变量sharedObj
}
Java缺省提供了this锁,多人喜欢直接在方法上使用synchronized加锁,很多情况下这样做是不恰当的,如果不考虑清楚就这样做,很容易造成锁粒度过大。要知道方法上的synchronized 是对象锁,要是再加个static 就是class锁,会锁定所有创建的对象。所以在使用的时候一定要控制好边界。
上面的代码将sychronized加在类的每一个方法上面,违背了保护什么锁什么的原则。 对于无共享资源的两个方法,使用了同一个锁,人为造成了不必要的锁等待。
- 锁的粒度过大,对共享资源访问完成后,没有将后续的代码放在synchronized同步代码块之外。从而导致资源占用时间过长,其他争用锁的线程只能等待。如下:
void fun1() {synchronized(lock){
//1 正在访问共享资源 ... ...
//2 做其它耗时操作,但这些耗时操作与共享资源无关... ...
}
}
上面的代码会导致线程长时间占用锁,从而导致其他线程只能等待。但这种写法在不同的场合优化的方式也是不一样的,需要注意下:
单CPU 将耗时操作拿到同步块之外,有的情况下可以提升性能,有的场合则不能。
同步块中的耗时代码是CPU密集型代码(如纯CPU运算等),不存在磁盘IO/网 络IO等低CPU消耗的代码,这种情况下,由于CPU执行这段代码是100%的使用率,因此缩小同步块也不会带来任何性能上的提升。但是,同时缩小同步块也不会带来性能上的下降。
同步块中的耗时代码属于磁盘/网络IO等低CPU消耗的代码,当当前线程正在执 行不消耗CPU的代码时,这时候CPU是空闲的,如果此时让CPU忙起来,可以带来整体性能上的提升,所在在这种场景下,将耗时操作的代码放在同步块中,肯定是可以提高整个性能的。
多CPU 将耗时操作拿到同步块之外,总是可以提升性能
同步块中的耗时代码是纯CPU运算,不存在磁盘IO/网络IO等可能不消耗CPU的 代码,这种情况下,由于是多CPU,其它CPU也许是空闲的,因此缩小同步块可 以让其它线程马上得到执行这段代码,可以带来性能的提升。
同步块中的耗时代码存在磁盘/网络IO等不消耗CPU的代码,当当前线程正在执 行不消耗CPU的代码时,这时候总有CPU是空闲的,如果此时让CPU忙起来,可 以带来整体性能上的提升,所在在这种场景下,将耗时操作的代码放在同步块 中,肯定是可以提高整个性能的。
所以,不管如何,缩小同步范围只会带来好处,那我们上面的代码优化如下:
void fun1() {synchronized(lock){
//1 正在访问共享资源 ... ...
}
//2 做其它耗时操作,但这些耗时操作与共享资源无关... ...
}
sleep的滥用
sleep只适合用在等待固定时长的场合,如果轮询代码中夹杂着sleep()调用,这 种设计必然是一种糟糕的设计。
这种设计在某些场合下会导致严重的性能瓶颈,如果是用户交互的系统,那么用户会必然会直接感觉系统变慢。
如果是后台消息处理系统,那么必然消息处 理会很慢。这种设计肯定可以使用notify()和wait()来完成同样的功能
String +的滥用
String c = new String("abc") + new String("efg") + new String("12345");
每一次+操作都会产生一个临时对象,并伴随着数据拷贝,这个对性能是一个极大的消耗。这 个写法常常成为系统的瓶颈,如果这个地方恰好是一个性能瓶颈,修改成StringBuffer之后,性 能会有大幅的提升.
不恰当的线程模型
在多线程场合下, 如果线程模型不恰当, 也会使性能低下。 如在网 络IO的场合,我们一定要使用消息发送队列和消息接收队列来进行异步IO. 这种修改之后, 性能可能会有几十倍的上升。
线程数量不足
在使用线程池的场合,如果线程池的线程配置太少,也会导致性能低下
内存泄漏导致的频繁GC
内存泄漏会导致GC越来越频繁,而GC操作是CPU密集型操作,频 繁GC会导致系统整体性能严重下降,这也是我们会经常遇到的问题。
四、分析的手段和工具
上面提到的所有这些原因形成的性能瓶颈,都可以通过线程堆栈分析,找到根本的原因,论ThreadDump的重要性,注意ThreadDump比较适合多线程场景下的问题分析。
怎么模拟发现瓶颈
性能瓶颈的几个特征:
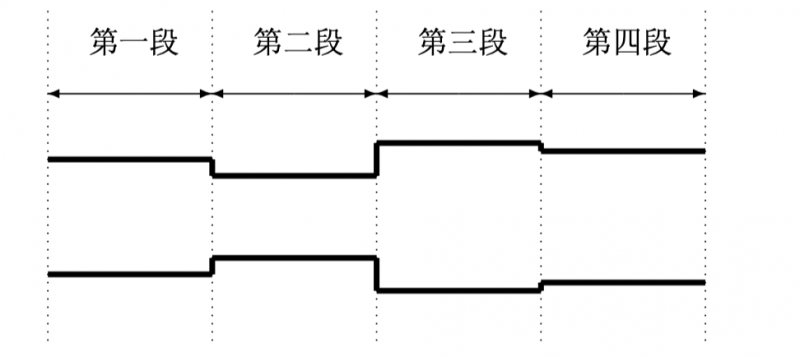
- 当前的性能瓶颈只有一处,只有当解决的这一处,才知道下一处。没有解决当前的性能瓶 颈,下一处性能瓶颈是不会出现的。在公路上,最窄的一处决定了该道路的通车能力。只有拓宽了最窄的地方,整个的交通的通车能力才能上去,而如果直接拓宽次窄(即第二 窄)的路段,整个路段的通车能力不会有任何的提升,如图:
- 性能瓶颈是动态的,低负载下不是瓶颈的地方,在高负载下可能成为瓶颈。在高压力下才 能出现的瓶颈,由于JProfiler等性能剖析工具依附在JVM上带来的开销,使系统根本就无 法达到该瓶颈出现时需要的性能。因此这种类型的性能瓶颈在JProfiler 或者OptimizeIt等 性能剖析工具下压根无法出现,也就无法找到这个性能瓶颈。在这种场合下,进行线程堆 栈分析才是一个真正有效的办法。
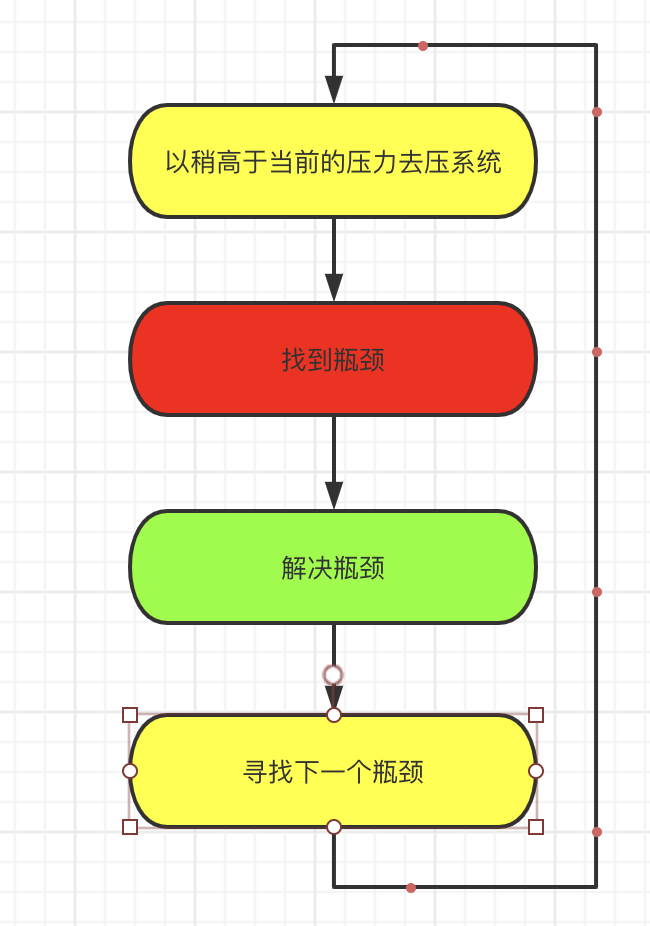
鉴于性能瓶颈的以上特点,进行性能模拟的时候,一定要使用比系统当前稍高的压力下 进行模拟,否则性能瓶颈不会现形。具体的步骤如下:
如何通过线程堆栈找到性能瓶颈?
一般一个系统一旦出现性能瓶颈,从堆栈 上分析,有如下三种最为典型的堆栈特征:
- 绝大多数线程的堆栈都表现为在同一个调用上下文上,且只剩下非常少的空闲线程。可能的原因如下:
(a) 线程的数量过少
(b) 锁的粒度过大导致的锁竞争
(c) 资源竞争(如数据库连接池中连接不足,导致有些获取连接的线程被阻塞)
(d) 锁范围内有大量耗时操作(如大量的磁盘IO),导致锁争用。
(e) 远程通信的对方处理缓慢(dubbo 提供者变慢),如数据库侧的SQL代码性能低下。
- 绝大多数线程处于等待状态,只有几个工作的线程,总体性能上不去。可能的原因是,系统存在关键路径,在该关键路径上没有足够的能力给下个阶段输送大量的任务,导致其它地方空闲。如在消息分发系统,消息分发一般是一个线程,而消息处理是多个线程,这 时候消息分发是瓶颈的话,那么从线程堆栈就会观察到上面提到的现象:即该关键路 没有足够的能力给下个阶段输送大量的任务,导致其它地方空闲。
- 线程总的数量很少。导致性能瓶颈的原因与上面的类似。这里线程很少,是由于某些线程池实现使用另一种设计思路,当任务来了之后才new出线程来,这种实现方式下,线程的数量上不去,就意味有在某处关键路径上没有足够的能力给下个阶段输送大量的任务, 从而不需要更多的线程来处理。
下面是一个出现了性能瓶颈的堆栈的例子:
"Thread-243" prio=1 tid=0xa58f2048 nid=0x7ac2 runnable [0xaeedb000..0xaeedc480]at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(SocketInputStream.java:129) at oracle.net.ns.Packet.receive(Unknown Source) ... ...
at oracle.jdbc.driver.LongRawAccessor.getBytes() at oracle.jdbc.driver.OracleResultSetImpl.getBytes()
- locked <0x9350b0d8> (a oracle.jdbc.driver.OracleResultSetImpl) at oracle.jdbc.driver.OracleResultSet.getBytes(O) ... ...
at org.hibernate.loader.hql.QueryLoader.list() at org.hibernate.hql.ast.QueryTranslatorImpl.list() ... ...
at com.wes.NodeTimerOut.execute(NodeTimerOut.java:175) at com.wes.timer.TimerTaskImpl.executeAll(TimerTaskImpl.java:707) at com.wes.timer.TimerTaskImpl.execute(TimerTaskImpl.java:627)
- locked <0x80df8ce8> (a com.wes.timer.TimerTaskImpl) at com.wes.threadpool.RunnableWrapper.run(RunnableWrapper.java:209) at com.wes.threadpool.PooledExecutorEx$Worker.run() at java.lang.Thread.run(Thread.java:595)
"Thread-248" prio=1 tid=0xa58f2048 nid=0x7ac2 runnable [0xaeedb000..0xaeedc480]
at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(SocketInputStream.java:129) at oracle.net.ns.Packet.receive(Unknown Source) ... ...
at oracle.jdbc.driver.LongRawAccessor.getBytes() at oracle.jdbc.driver.OracleResultSetImpl.getBytes() - locked <0x9350b0d8> (a oracle.jdbc.driver.OracleResultSetImpl) 2
at oracle.jdbc.driver.OracleResultSet.getBytes(O) ... ...
at org.hibernate.loader.hql.QueryLoader.list() at org.hibernate.hql.ast.QueryTranslatorImpl.list() ... ...
a com.wes.NodeTimerOut.execute(NodeTimerOut.java:175) at com.wes.timer.TimerTaskImpl.executeAll(TimerTaskImpl.java:707) at com.wes.timer.TimerTaskImpl.execute(TimerTaskImpl.java:627) - locked <0x80df8ce8> (a com.wes.timer.TimerTaskImpl) at com.wes.threadpool.RunnableWrapper.run(RunnableWrapper.java:209) at com.wes.threadpool.PooledExecutorEx$Worker.run() at java.lang.Thread.run(Thread.java:595)
... ...
"Thread-238" prio=1 tid=0xa4a84a58 nid=0x7abd in Object.wait() [0xaec56000..0xaec57700]
at java.lang.Object.wait(Native Method) at com.wes.collection.SimpleLinkedList.poll(SimpleLinkedList.java:104)
- locked <0x6ae67be0> (a com.wes.collection.SimpleLinkedList) at com.wes.XADataSourceImpl.getConnection_internal(XADataSourceImpl.java:1642) ... ...
at org.hibernate.impl.SessionImpl.list() at org.hibernate.impl.SessionImpl.find() at com.wes.DBSessionMediatorImpl.find() at com.wes.ResourceDBInteractorImpl.getCallBackObj() at com.wes.NodeTimerOut.execute(NodeTimerOut.java:152) at com.wes.timer.TimerTaskImpl.executeAll() at com.wes.timer.TimerTaskImpl.execute(TimerTaskImpl.java:627)
- locked <0x80e08c00> (a com.facilities.timer.TimerTaskImpl) at com.wes.threadpool.RunnableWrapper.run(RunnableWrapper.java:209) at com.wes.threadpool.PooledExecutorEx$Worker.run() at java.lang.Thread.run(Thread.java:595)
"Thread-233" prio=1 tid=0xa4a84a58 nid=0x7abd in Object.wait() [0xaec56000..0xaec57700]
at java.lang.Object.wait(Native Method)
at com.wes.collection.SimpleLinkedList.poll(SimpleLinkedList.java:104) - locked <0x6ae67be0> (a com.wes.collection.SimpleLinkedList) at com.wes.XADataSourceImpl.getConnection_internal(XADataSourceImpl.java:1642) ... ...
at org.hibernate.impl.SessionImpl.list() at org.hibernate.impl.SessionImpl.find() at com.wes.DBSessionMediatorImpl.find() 48
at com.wes.ResourceDBInteractorImpl.getCallBackObj() at com.wes.NodeTimerOut.execute(NodeTimerOut.java:152) at com.wes.timer.TimerTaskImpl.executeAll() at com.wes.timer.TimerTaskImpl.execute(TimerTaskImpl.java:627) - locked <0x80e08c00> (a com.facilities.timer.TimerTaskImpl) at com.wes.threadpool.RunnableWrapper.run(RunnableWrapper.java:209) at com.wes.threadpool.PooledExecutorEx$Worker.run() at java.lang.Thread.run(Thread.java:595) ... ...
从堆栈中看,其中有N多个是JDBC数据库访问占用的。这说明有可能把链接已经耗尽,其它所有http请求由于获取不到链接,而被阻塞在java.lang.Object.wait()方法 上. 从这个堆栈中看,性能瓶颈出现在数据库访问上,数据库访问耗尽了所有的连接。找到瓶 颈后,下一步结合源代码分析,具体是什么原因导致了数据库的访问需要过长的时间? 没有创建索引,还是使用了效率过低的SQL语句?
性能调优的终结条件
性能调优的过程总是有一个止点,那么满足什么条件,就说明已经没有优化的空间?总结下就有如下俩个:
- 算法足够优化,代码的优化已到极致了
- 线程充分的使用了cpu
如果达到上面的条件,性能仍然无法满足应用的要求,只能通过考虑购买更好的机器,或 者集群来实现更大的容量支持
性能调优工具
耳熟能详的几个 JProfiler VisualVM和JDK自带的一些工具。但这些分析工具一旦挂到系统上之后,会导致整体性能的大幅下降,在多线程场合下,由于整体的压力无法上去,导致性能瓶颈根本就不会出现,因此这种场合下进行性能 分析,这些工具基本上是没有帮助的。这些性能剖析工具比较适合于单线程下的代码段分析, 找到比较耗时的算法和代码,但对于多线程场合下锁使用不当的分析,往往无能为力。
以上是 ThreadDump性能瓶颈分析 的全部内容, 来源链接: utcz.com/a/19721.html