深入了解Java ConcurrentHashMap
在上一篇文章【简单了解系列】从基础的使用来深挖HashMap里,我从最基础的使用中介绍了HashMap,大致是JDK1.7和1.8中底层实现的变化,和介绍了为什么在多线程下可能会造成死循环,扩容机制是什么样的。感兴趣的可以先看看。
我们知道,HashMap是非线程安全的容器,那么为什么ConcurrentHashMap能够做到线程安全呢?
底层结构
首先看一下ConcurrentHashMap的底层数据结构,在Java8中,其底层的实现方式与HashMap一样的,同样是数组、链表再加红黑树,具体的可以参考上面的HashMap的文章,下面所有的讨论都是基于Java 1.8。
transientvolatile Node<K,V>[] table;volatile关键字
对比HashMap的底层结构可以发现,table的定义中多了一个volatile关键字。这个关键字是做什么的呢?我们知道所有的共享变量都存在主内存中,就像table。
而线程对变量的所有操作都必须在线程自己的工作内存中完成,而不能直接读取主存中的变量,这是JMM的规定。所以每个线程都会有自己的工作内存,工作内存中存放了共享变量的副本。而正是因为这样,才造成了可见性的问题。
ABCD四个线程同时在操作一个共享变量X,此时如果A从主存中读取了X,改变了值,并且写回了内存。那么BCD线程所得到的X副本就已经失效了。此时如果没有被volatile修饰,那么BCD线程是不知道自己的变量副本已经失效了。继续使用这个变量就会造成数据不一致的问题。
内存可见性
而如果加上了volatile关键字,BCD线程就会立马看到最新的值,这就是内存可见性。你可能想问,凭什么加了volatile的关键字就可以保证共享变量的内存可见性?
那是因为如果变量被volatile修饰,在线程进行写操作时,会直接将新的值写入到主存中,而不是线程的工作内存中;而在读操作时,会直接从主存中读取,而不是线程的工作内存。
基础使用
首先这个使用与HashMap没有任何区别,只是实现改成了ConcurrentHashMap。
Map<String, String> map = new ConcurrentHashMap<>();map.put("微信搜索", "SH的全栈笔记");
map.get("微信搜索"); // SH的全栈笔记
取值
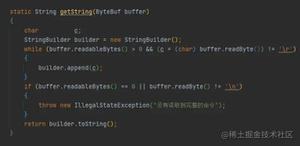
首先我们来看一下get方法的使用,源码如下。
public V get(Object key){ Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
elseif (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
returnnull;
}
大概解释一下这个过程发生了什么,首先根据key计算出哈希值,如果找到了就直接返回值。如果是红黑树的话,就在红黑树中查找值,否则就按照链表的查找方式查找。
这与HashMap也差不多的,元素会首先以链表的方式进行存储,如果该桶中的元素数量大于TREEIFY_THRESHOLD的值,就会触发树化。将当前的链表转换为红黑树。因为如果数量太多的话,链表的查询效率就会变得非常低,时间复杂度为O(n),而红黑树的查询时间复杂度则为O(logn),这个阈值在Java 1.8中的默认值为8,定义如下。
staticfinalint TREEIFY_THRESHOLD = 8;赋值
put的源码就不放出来了,放在这大家估计也不会一行一行的去看。所以我就简单的解释一下put的过程发生了什么事,并贴上关键代码就好了。
整个过程,除开并发的一些细节,大致的流程和1.8中的HashMap是差不多的。
首先会根据传入的key计算出hashcode,如果是第一次被赋值,那自然需要进行初始化table 如果这个key没有存在过,直接用CAS在当前槽位的头节点创建一个Node,会用自旋来保证成功 如果当前的Node的hashcode是否等于-1,如果是则证明有其它的线程正在执行扩容操作,当前线程就加入到扩容的操作中去 且如果该槽位(也就是桶)上的数据结构如果是链表,则按照链表的插入方式,直接接在当前的链表的后面。如果数量大于了树化的阈值就会转为红黑树。 如果这个key存在,就会直接覆盖。 判断是否需要扩容
看到这你可能会有一堆的疑问。
例如在多线程的情况下,几个线程同时来执行put操作时,怎么保证只执行一次初始化,或者怎么保证只执行一次扩容呢?万一我已经写入了数据,另一个线程又初始化了一遍,岂不是造成了数据不一致的问题。同样是多线程的情况下, 怎么保证put值的时候不会被其他线程覆盖。CAS又是什么?
接下来我们就来看一下在多线程的情况下,ConcurrentHashMap是如何保证线程安全的。
初始化的线程安全
首先我们来看初始化的源码。
privatefinal Node<K,V>[] initTable() { Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
elseif (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
可以看到有一个关键的变量,sizeCtl,其定义如下。
privatetransientvolatileint sizeCtl;sizeCtl使用了关键字volatile修饰,说明这是一个多线程的共享变量,可以看到如果是首次初始化,第一个判断条件if ((sc = sizeCtl) < 0)是不会满足的,正常初始化的话sizeCtl的值为0,初始化设定了size的话sizeCtl的值会等于传入的size,而这两个值始终是大于0的。
CAS
然后就会进入下面的U.compareAndSwapInt(this, SIZECTL, sc, -1)方法,这就是上面提到的CAS,Compare and Swap(Set),比较并交换,Unsafe是位于sun.misc下的一个类,在Java底层用的比较多,它让Java拥有了类似C语言一样直接操作内存空间的能力。
例如可以操作内存、CAS、内存屏障、线程调度等等,但是如果Unsafe类不能被正确使用,就会使程序变的不安全,所以不建议程序直接使用它。
compareAndSwapInt的四个参数分别是,实例、偏移地址、预期值、新值。偏移地址可以快速帮我们在实例中定位到我们要修改的字段,此例中便是sizeCtl。如果内存当中的sizeCtl是传入的预期值,则将其更新为新的值。这个Unsafe类的方法可以保证这个操作的原子性。当你在使用parallelStream进行并发的foreach遍历时,如果涉及到修改一个整型的共享变量时,你肯定不能直接用i++,因为在多线程下,i++每次操作不能保证原子性。所以你可能会用到如下的方式。
AtomicInteger num = new AtomicInteger();arr.parallelStream().forEach(item -> num.getAndIncrement());
你可能会好奇,为什么使用了AtomicInteger就可以保证原子性,跟Unsafe类和CAS又有什么关系,让我们接着往下,看getAndIncrement方法的底层实现。
publicfinalintgetAndIncrement(){return unsafe.getAndAddInt(this, valueOffset, 1);
}
可以看到,底层调用的是Unsafe类的方法,这不就联系上了吗,而getAndIncrement的实现又长这样。
publicfinalintgetAndAddInt(Object var1, long var2, int var4){int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
没错,这里底层调用了compareAndSwapInt方法。可以看到这里加了while,如果该方法返回false就一直循环,直到成功为止。这个过程有个🐂🍺的名字,叫自旋。特别高端啊,说人话就是无限循环。
什么情况会返回false呢?那就是var5变量存储的值,和现在内存中实际var5的值不同,说明这个变量已经被其他线程修改过了,此时通过自旋来重新获取,直到成功为止,然后自旋结束。
结论
聊的稍微有点多,这小节的问题是如何保证不重复初始化。那就是执行首次扩容时,会将变量sizeCtl设置为-1,因为其被volatile修饰,所以其值的修改对其他线程可见。
其它线程再调用初始化时,就会发现sizeCtl的值为-1,说明已经有线程正在执行初始化的操作了,就会执行Thread.yield(),然后退出。
yield相信大家都不陌生,和sleep不同,sleep可以让线程进入阻塞状态,且可以指定阻塞的时间,同时释放CPU资源。而yield不会让线程进入阻塞状态,而且也不能指定时间,它让线程重新进入可执行状态,让出CPU调度,让CPU资源被同优先级或者高优先级的线程使用,稍后再进行尝试,这个时间依赖于当前CPU的时间片划分。
如何保证值不被覆盖
我们在上一节举了在并发下i++的例子,说在并发下i++并不是一个具有原子性的操作,假设此时i=1,线程A和线程B同时取了i的值,同时+1,然后此时又同时的写回。那么此时i++的值会是2而不是3,在并发下1+1+1=2是可能出现的。
让我们来看一下ConcurrentHashMap在目标key已经存在时的赋值操作,因为如果不存在会直接调用Unsafe的方法创建一个Node,所以后续的线程就会进入到下面的逻辑中来,由于太长,我省略了一些代码。
......V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
......
}
}
elseif (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
上述代码在赋值的逻辑外层包了一个synchronized,这个有什么用呢?
synchronized关键字
这个地方也可以换一个方式来理解,那就是synchronized如何保证线程安全的。线程安全,我认为更多的是描述一种风险。在堆内存中的数据由于可以被任何线程访问到,在没有任何限制的情况下存在被意外修改的风险。
而synchronized是通过对共享资源加锁的方式,使同一时间只能有一个线程能够访问到临界区(也就是共享资源),共享资源包括了方法、锁代码块和对象。
那是不是使用了synchronized就一定能保证线程安全呢?不是的,如果不能正确的使用,很可能就会引发死锁,所以,保证线程安全的前提是正确的使用synchronized。
自动扩容的线程安全
除了初始化、并发的写入值,还有一个问题值得关注,那就是在多线程下,ConcurrentHashMap是如何保证自动扩容是线程安全的。
扩容的关键方案是transfer,但是由于代码太多了,贴在这个地方可能会影响大家的理解,感兴趣的可以自己的看一下。
还是大概说一下自动扩容的过程,我们以一个线程来举例子。在putVal的最后一步,会调用addCount方法,然后在方法里判读是否需要扩容,如果容量超过了实际容量 * 负载因子(也就是sizeCtl的值)就会调用transfer方法。
计算分区的范围
因为ConcurrentHashMap是支持多线程同时扩容的,所以为了避免每个线程处理的数量不均匀,也为了提高效率,其对当前的所有桶按数量(也就是上面提到的槽位)进行分区,每个线程只处理自己分到的区域内的桶的数据即可。
当前线程计算当前stride的代码如下。
stride = (NCPU > 1) ? (n >>> 3) / NCPU : n);如果计算出来的值小于设定的最小范围,也就是private static final int MIN_TRANSFER_STRIDE = 16;,就把当前分区范围设置为16。
初始化nextTable
nextTable也是一个共享变量,定义如下,用于存放在正在扩容之后的ConcurrentHashMap的数据,当且仅当正在扩容时才不为空。
privatetransientvolatile Node<K,V>[] nextTable;如果当前transfer方法传入的nextTab(这是个局部变量,比上面提到的nextTable少了几个字母,不要搞混了)是null,说明是当前线程是第一个调用扩容操作的线程,就需要初始化一个size为原来容量2被的nextTable,核心代码如下。
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; // 可以看到传入的初始化容量是n << 1。初始化成功之后就更新共享变量nextTable的值,并设置transferIndex的值为扩容前的length,这也是一个共享的变量,表示扩容使还未处理的桶的下标。
设置分区边界
一个新的线程加入扩容操作,在完成上述步骤后,就会开始从现在正在扩容的Map中找到自己的分区。例如,如果是第一个线程,那么其取到的分区就会如下。
start = nextIndex - 1;end = nextIndex > stride ? nextIndex - stride : 0;
// 实际上就是当还有足够的桶可以分的时候,线程分到的分区为 [n-stride, n - 1]
可以看到,分区是从尾到首进行的。而如果是首次进入的线程,nextIndex 的值会被初始化为共享变量transferIndex 的值。
Copy分区内的值
当前线程在自己划分到的分区内开始遍历,如果当前桶是null,那么就生成一个 ForwardingNode,代码如下。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);并把当前槽位赋值为fwd,你可以把ForwardingNode理解为一个标志位,如果有线程遍历到了这个桶, 发现已经是ForwardingNode了,就代表这个桶已经被处理过了,就会跳过这个桶。
如果这个桶没有被处理过,就会开始给当前的桶加锁,我们知道ConcurrentHashMap会在多线程的场景下使用,所以当有线程正在扩容的时候,可能还会有线程正在执行put操作,所以如果当前Map正在执行扩容操作,如果此时再写入数据,很可能会造成的数据丢失,所以要对桶进行加锁。
总结
对比在1.7中采用的Segment分段锁的臃肿设计,1.8中直接使用了CAS和Synchronized来保证并发下的线程安全。总的来说,在1.8中,ConcurrentHashMap和HashMap的底层实现都差不多,都是数组、链表和红黑树的方式。其主要区别就在于应用场景,非并发的情况可以使用HashMap,而如果要处理并发的情况,就需要使用ConcurrentHashMap。关于ConcurrentHashMap就先聊到这里。
以上是 深入了解Java ConcurrentHashMap 的全部内容, 来源链接: utcz.com/a/19696.html