Spring Boot JPA
提到JPA操作数据库,有的人惊叹于它的简洁与强大,有些人则会觉得不够灵活,影响实战效率,那么究竟JPA为何让人又爱又恨呢?

一 原理 战前磨刀
01.认识 JPA
JPA-Java Persistence API,即Java持久化API
总得来说,JPA 为对象关系映射提供了⼀种基于 POJO 的持久化模型
简化数据持久化代码的开发⼯作
为 Java 社区屏蔽不同持久化 API 的差异
而我们常说的Hibernate又是什么呢?它其实是JPA的一种实现
02. 认识 Spring Data
以前,Spring只是在内部实现了支持JDBC、JPA等的方式。后来,Spring将所有对于数据操作的工具都整理在了Spring Data中,Spring Data 在保留底层存储属性的同时,提供相对一致的、基于Spring的编程模型。
主要模块:
Spring Data JPASpring Data JDBC
Spring Data Redis
Spring Data MongoDB
03. 认识 Spring Data JPA
Spring Data JPA,即Spring对JPA的封装。
官网上讲:Spring Data JPA旨在通过将工作量减少到实际需要的数量,来显著改善数据访问层的操作
作为开发人员,你只需要写你的repository接口,包括自定义的方法,Spring会自动提供实现
04. 常用的jpa实体类注解
通过JPA提供的一些实体类注解,我们可以配置一个对应的表,从而在程序运行时,JPA可以自动实现为我们建表的工作
常见的JPA实体类注解如下:
实体
- @Entity
- @MappedSuperclass
- @Table(name)
@Entity与@MappedSuperclass都是声明实体类的注解。
@Entity表示所声明的实体类里面定义的所有属性,均与对应的表关联
@MappedSuperclass表示所注解的类为一个父类,子类可以通过继承该父类来扩展自己的属性
@Table(name),表明该实体类与数据库中的某个表关联
主键
- @Id
- @GeneratedValue(strategy, generator)
- @SequenceGenerator(name, sequenceName)
@Id和**@GeneratedValue**常常组合起来,用于主键声明,并指定主键生成策略和生成器(若不指定,JPA会根据所引入驱动依赖的数据库进行默认策略的设置)
@SequenceGenerator注解,表示主键会采用系列号的方式生成
映射
- @Column(name,nullable,length,insertable,updatable)
- @JoinTable(name) @JoinColumn(name)
均用在属性上。@Column指定一个属性所映射的字段信息
若存在外键,可以使用**@JoinTable(name)** **@JoinColumn(name)**组合进行定义
关系
- @OneToOne @OneToMany
- @ManyToOne @ManyToMany
- @OrderBy
前四个注解用在属性上,分别表示表与该属性的对应关系。
@OrderBy同样使用在属性上,表示**@oneToMany以及@ManyToMany**,即一对多或者多对多时,字段的排序方式
05. Repository介绍
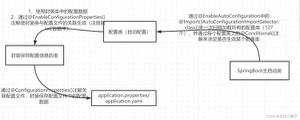
加上**@EnableJpaRepositories**,即可开启JPA的repository的支持,Spring 就会发现以下repository的扩展
- CrudRepository<T, ID> 提供基本增删改查方法
- PagingAndSortingRepository<T, ID> 用于分页、排序方法
- JpaRepository<T, ID> 用于持久化等方法
06. 查询方式
1 ) 根据方法名定义查询
查询方法,默认只提供了查询所有或者按照ID查询的方法。
若想要查询更丰富的内容,比如按照某个条件查询、统计记录数、排序展示、多条件查询、查询第一条或最后一条等,这么多复杂的场景,依旧不需要写sql,我们只需要在repository中定义如下格式的方法就可以轻而易举的实现啦~
• find…By… / read…By… / query…By… / get…By…
• count…By…
• …OrderBy…[Asc / Desc]
• And / Or / IgnoreCase
• Top / First / Distinct
2) 分页查询
• PagingAndSortingRepository<T, ID>
• Pageable / Sort
• Slice / Page
要想实现分页查询,可以使用PagingAndSortingRepository接口,与Pagable/Sort类相配合,即可实现分页查询
二 实战 实战环节
对原理有个大概的了解,接下来,就进入今天的实战环节啦~
本次实战依旧演示操作mysql数据库。
01. 引入依赖
只需要引入spring-data-jpa和mysql驱动两个主要依赖。
<dependency><groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
02. 属性配置
分别进行数据库连接信息以及jpa的相关信息配置
以下分别为大家演示了jpa的建表机制、是否打印sql语句以及是否格式化sql语句显示这3个常用的配置项
#1、数据库连接信息配置spring.datasource.url=jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=123456
#可以不用配置数据库驱动,SpringBoot 会根据引入的依赖进行自动配置
#spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#2、jpa配置信息
#建表机制
#create-drop - 运行程序新建,程序结束:删表
#create -运行程序会新建表,程序结束:表的数据会清空
#update - 没有表格时会新建表格,表内有数据不会清空,只会更新,
#valid - 运行程序会校验数据与数据库的字段类型是否相同,不同会报错
spring.jpa.hibernate.ddl-auto=update
#打印sql开关
spring.jpa.properties.hibernate.show_sql=true
#是否格式化sql
spring.jpa.properties.hibernate.format_sql=true
其中,JPA的建表机制分为四种,注释中已标出,大家可以按照实际需求,选择不同机制,一般情况建议选择update机制,比较完善,也不用怕每次清空了表或者数据
03. 创建实体类
根据我们在战前准备中所介绍的实体类的注解,我们建立好的实体类User如下:
@Entity@Table(name = "USER")
@Builder
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
@Id
@GeneratedValue
private Long id;
private String name;
@Column(updatable = false)
@CreationTimestamp
private Date createTime;
@UpdateTimestamp
private Date updateTime;
}
首先使用**@Entity与@Table(name="USER")**组合,表明该实体类与数据库中的user表关联;
@Id与@GeneratedValue组合,表明字段id被映射为主键,JPA会根据引入的数据库依赖,来配置对应的主键生成策略。
而属性createTime,分别使用注解**@Column(updatable=false)和@CreationTimestamp**表示它不可被修改,且对应表中字段的值默认为插入对应记录的时间;
注解**@UpdateTimestamp**则表示,属性updateTime会自动变为对应行记录的更新时间
04. 创建repository
创建自己的UserRepository接口,并实现CrudRepository
public interface UserRepository extends CrudRepository<User,Long> {List<User> findByNameOrderByCreateTimeDesc(String name);
}
05. 调用repository方法
1)开启jpa的repossitory注解
在启动类上添加注解:
@EnableJpaRepositories
2)注入自定义的Repository
3) 调用具体数据库操作方法
@SpringBootApplication@Slf4j
@EnableJpaRepositories
public class SpringBootJpaApplication implements ApplicationRunner {
@Autowired
private UserRepository userRepository;
@Override
public void run(ApplicationArguments args) throws Exception {
User user = User.builder()
.name("小米")
.createTime(new Date())
.updateTime(new Date())
.build();
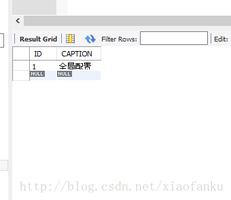
userRepository.save(user);
log.info("one user added :{}",user);
Iterable<User> users = userRepository.findAll();
users.forEach(System.out::println);
}
- 运行项目
通过运行项目,我们可以通过打印出的sql语句看到,JPA在服务启动时,分别为我们创建了对应于实体类User的user表,并生成了序列化主键id
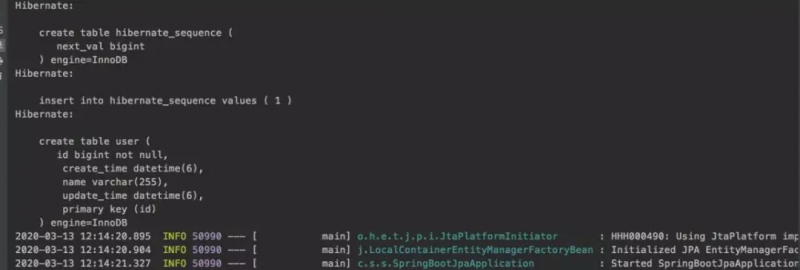
接着执行了数据库的插入操作,成功插入一条数据
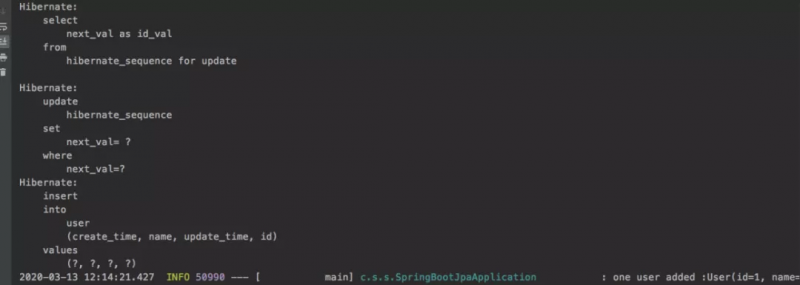
最后,执行数据库的查询语句,查询出我们所添加的一条user记录
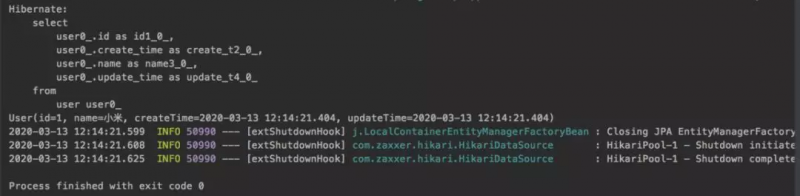
回顾一下,我们的主要的操作其实就只是实现了@CrudRepository接口,然后直接调用其方法,就可以操作数据库了
那么,简单的数据库操作就实现啦~

庆祝一会儿,然后开始接下来的进阶操作
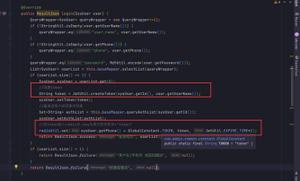
我们试着自定义一个查询方法根据姓名查询,并以CreateTime降序排序的方法:
findByNameOrderByCreateTimeDesc(String name)
调用,并运行服务之后,结果如下:
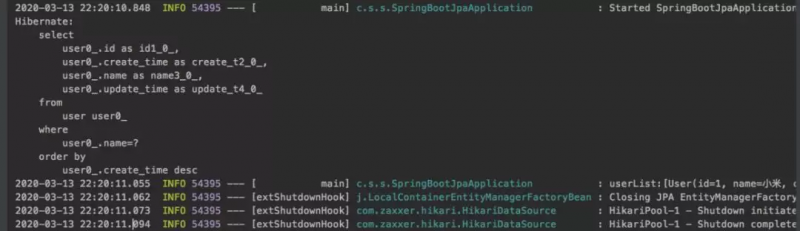
打印出的sql语句表示:根据姓名查询,并以CreateTime降序排序
相应地,如果要定义其他查询方法,只需要直接在自定义的Repository中直接按照第一节中的方法定义规则进行定义即可,具体规则可以查看包org.springframework.data.repository.query.parser中的各类,比如PartTree类:
Tips:
JPA也有专门的**@Query注解以及JPA Named Queries**,可以分别在方法上或者xml文件中自定义sql,实现更多操作场景,感兴趣的话,大家可以参考官网查看哦~
三 总结 总而言之
相对于Mybatis来说,我们可以看到,JPA不知方便多少倍了。它可以说是真正意义上的ORM框架,有以下两大优势:
I.直接可以通过实体类与表、实体属性与表的字段之间的关联,自动为我们建表
II.使用时不需要再考虑使用的是何种数据库,也基本不需要写sql语句
大大解放了 coding的劳动人民!有木有

但是呢,正如我们所看到的那样,正因为JPA将ORM封装的太完善了,使得我们操作数据库的灵活性大大降低了。比如我们如果想要实现多表关联的查询、多条件查询等等,都会变得更加复杂
所以,项目中要想使用JPA,一定得预先根据项目实际需求,来权衡这些特点
恭喜你,又get到了几个技能点:
1、JPA、Spring DATA的定位与功能
2、Spring DATA JPA操作数据库的方式
3、JPA让人又爱又恨的原因
嗯,就这样。每天学习一点,时间会见证你的成长
以上是 Spring Boot JPA 的全部内容, 来源链接: utcz.com/a/19599.html