线上FullGC频繁,old区下不去
问题:
线上一个服务,跑了一个月挺正常的,这两天突然频繁FULLGC报警,因为fgc频繁会影响服务使用,而且报警太频繁了我就先重启系统了。下面是我自己排查过程的一些记录截图:
首先我先看了下系统内存和负载概况:
然后看一下我应用启动参数:
重要的是JAVA_OPS, 文字放一下:-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=256m -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:CMSInitiatingOccupancyFraction=80 -XX:+PrintGCDetails -XX:+PrintGCDateStamps
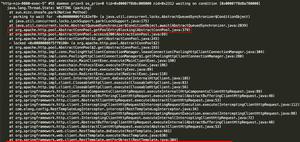
jstat -gc 看了一下(因为并没有打印gc日志到文件中,所以只能通过这种方式观察了)
可以看到最后倒数第三列是FGC的次数,几秒钟之内确实长得比较快,按理说fgc应该一天都不会出现几次的。第八列是老年代使用的情况(截图的时候已经过了一段时间了实际上1400000 多的时候FGC就开始涨了),FGC次数上涨而已使用空间不下降,说明FGC并没有有效的释放内存。
map -heap 的状态:

网上说对象太多,看看都是什么对象太大了,于是我又jmap -histo了一下,发现[C占得比重最大(这个是字符数组吧,其实就应该是字符串吧):

这个服务是操作elasticsearch的rpc服务,(不是dubbo,公司内部的一个rpc框架),调用方通过我的接口对es增删改查。我将返回的数据通过fastjson解析最后返回给调用方。代码里没有静态集合(类似static Map<String,Object> 这种对象),qps高峰期达到370/s,晚上低峰期也就30-50/s.之前出现过一次高频fullgc,我去掉了一些多余的日志输出,结果还是出来了。
求解决办法,还要从哪里着手排查呢
回答:
跟我们之前用solr好像 一个问题 关注下 可以在方法中将es查询出来的对象手动赋值null 试试
回答:
sf上难得的好问题,你贴的信息还不够全,在发生full gc的时候,登上机器用top -H找到最忙的线程pid,再用jstack dump当时的线程快照,把这个贴上来,还有开启gc.log会有更多的现场信息,看看具体是哪块不够触发了fullgc。单纯的看你描述的问题来看,有点像某些逻辑存在内存泄露,就算fullgc了也赶不上内存增长的速度。
回答:
对了顺便说一下,gc日志我这个应用没打,但是看别的应用是有的,我就看了一下发现他们的应用通过jstat -gc 观察到 FGC这一列也出现了几百次了(跑了几个月的),但是gc.log日志里面丝毫没有fullgc的字样,只有一些 cms-current-sweep-start 这种,有点糊涂,FGC这一列到底是不是代表着fullgc次数呢?
回答:
兄弟,JVM这个问题你找到问题了吗,我今天遇到和你一样的问题
以上是 线上FullGC频繁,old区下不去 的全部内容, 来源链接: utcz.com/a/166707.html