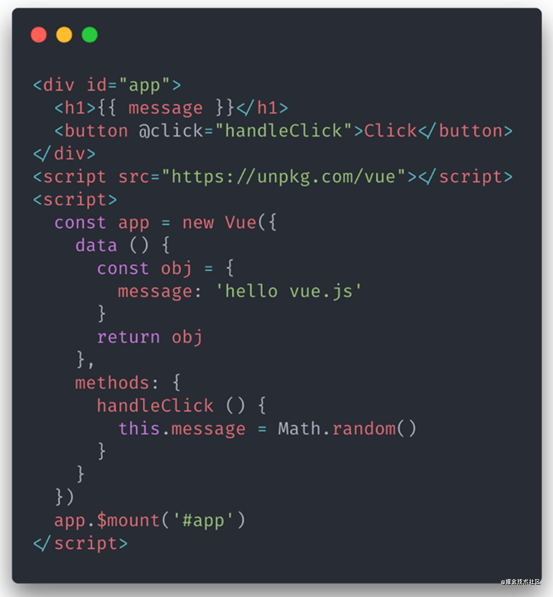
为什么tcp套接字是需要IP和端口号,UDP只要端口号?
计算机网络自顶向下方法,多路复用和多路分解那段说,TCP套接字是有一个四元组(源IP地址,源端口号,目的IP地址,目的端口号)标识的,UDP套接字是源端口号,目的端口号标识的?
为什么一个需要IP地址,一个不需要?
然后下图的TCP报文里也没IP地址啊,为什么?

回答:
不管是tcp还是udp, 都是一个四元组确定一个连接! 或许是书上阐述的不够详细的缘故导致题主有这样疑惑.
或许简单了解下网络层和传输层分别负责的工作, 可以帮助理解:
网络层: 目的是实现两个端系统之间的数据透明传送, 包括寻址和路由选择、连接的建立、保持和终止等.(主机与主机间)
报文在网络中传输, 路由器将根据ip头的目的ip, 为该报文选择合适的路由, 选择合适的线路, 来让其可以到达最终的目的主机. 就好比写信, 我写了一封信, 寄往xxx市yyy区zzz镇aaa号kkk人收,邮差就会根据前面的地址,将信派发到aaa号的地方, 在这里,邮差就相当于路由器,根据信上的地址, 来选址选方向, 网络层就是提供这样的服务,只要报文段是在网络层以上的, 它就会有这样的功能和义务. 每个ip地址,都是一个实实在在的个体, 是确切可以通信的.
传输层: 实现端到端的数据传输(程序与程序间)
接着上面的例子, 当邮差把信投递到aaa号, 他遍不管了,因为他不知道谁叫kkk,这时候谁来管? 肯定就是aaa号里面的人, 他知道kkk是谁, 所以他就直接把收到的信, 拿给kkk, 到了这一步, 整个通信才算完成, 因为kkk此刻才确切看到信(数据), 如果aaa地方里面, 有好几个叫kkk的人, 那这样就混乱了, 压根不知道给谁, 现实世界如此,在操作系统便是, 所以直接定义端口号不能重复.
所以总结的一点就是:
数据包中:
ip头部, 是为了让报文能够顺利从源主机, 到达目的主机tcp/udp头部, 是为了让报文在目的主机, 能够正确被投递到正确的程序
但是不管是tcp还是udp, 他们都是四元组来确定一个连接, 他们的区别,更多是在于对连接管理方式而已, 包括可靠性,创建与销毁等等
回答:
一个是对点,一个是广播,广播当然不需要具体的IP地址
回答:
@Lin_R 对于tcp udp的回答我是赞同的。
然后给你解答问题:
先确定什么叫套接字:
在3.2小节中说接收主机的运输层并没有将数据传递给进程去处理,而是传递给一个套接字。根据后文书进程和套接字的关系明显是一个一对多的关系。
什么叫多路复用和多路分解
多路复用和多路分解是套接字发送数据和接收数据的两个过程。
关于多路复用的定义指的是将运输层报文段的数据交付到正确的套接字工作,请注意数据这两个字,数据中有着封装着网络层的报文。在网络层的报文的字段中有着标识套接字的所需内容。
再看一下多路分解,指的是从不同套接字收集数据块并为每个数据块封装首部信息从而生成报文段
然后将报文段传递给网络层,这些工作称为多路分解。可能你想问应用层和运输层去哪了?这个交给你自己去解答。
说到这很遗憾,我无法解答你的问题
请原谅,我无法把这个你所说的标识通过我的语言为你解释的更加透彻。
还是看书吧:
书中对于你标识的描述是这样的
在无连接的多路复用和多路分解这一节:
一个udp套接字是由一个二元组来**全面标识**的,该二元组包含一个目的IP地址和一个目的端口号。在面向连接的多路复用和多路分解这一节:
一个Tcp套接字是由一个四元组来**全面标识**的。指出你一点问题,这个书好不好,好,经不经典,经典,这么好的书你可别把它读死了。
回答:
因为 IP 地址在 IP 头里呀。
因为 UDP 不需要保持连接状态,所以它只要投递对了端口就 OK 了。(其实也是五元组)
TCP 是要保持连接状态的。一个端口可以有多个连接。所以需要四元组(其实是五元组。因为这里特定了 TCP 协议,所以是四元组),才能标识一个连接是独一无二的。
回答:
补充说明一下:TCP是有一个伪header的,可以参照rfc793,这个伪header含有IP信息,会被用到计算checksum里面的。
回答:
TCP和UDP的区别就是TCP需要对方回应,保持连接。UDP就是发一下就不管结果了,简答地理解就行了。都需要IP和端口,逃不脱的。
回答:
标识一个套接字
UDP无连接,只要目的ip地址,目的端口号相同就送到相同的目的套接字,送到相同的目的进程
TCP套接字由四元组才能确定,源ip地址或者源端口号不一样会定向到不同的套接字。目的进程可以有多个会话socket建立多个tcp连接,参考socket编程。
以上是 为什么tcp套接字是需要IP和端口号,UDP只要端口号? 的全部内容, 来源链接: utcz.com/a/166519.html