使用 Python 如何爬取这样的数据 BeautifulSoup?request?
用于测试的链接是这样的
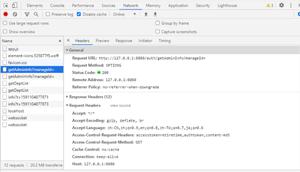
http://www.zhcw.com/ssq/kjgg/10006509.shtml
回答:
通过查找,发现这些数据是加载完页面再由JS动态写入的:
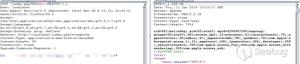
接着来找zj,上面两行有:
zj = obj[0];obj = con;
// 所以
zj = con[0];
// 又因为
con = eval((con.substring(con.indexOf("["), con.indexOf("]") + 1)));
其中,con为$.trim($('#currentScript').html().replace('<div>', '').replace('</div>', ''))
也就是,将$('#currentScript').html()的内容,去掉div标签后,过滤首尾空白字符后,取[到]中的数据,当做JSON解析。
这部分操作可以通过Python完成,所以,先用Python的BeautifulSoup找到#currentScript,再手动替换,然后当做JSON解析即可
code = '....' # HTML代码soup = BeautifulSoup(code, ...) # 创建soup对象
json = soup.find(id = 'currentScript'); # 此处,等价于获取con初始值
# 替换div
json = json.replace('<div>', '')
json = json.replace('</div>', '')
# $.trim等价
json = json.strip()
# 找到[和]中间的数据,拆成JSON
# cut_start和cut_end只是用于标记起始位置,类似上面的con.indexOf("[")和con.indexOf("]")
# 为了方便理解,单独写了
cut_start = json.find('[')
cut_end = json.find(']')
json = json[cut_start:cut_end + 1]
这样,就可以得到一个JSON字符串了,然后放到python的JSON解析器解析成JSON对象,这个你自己写吧。
回答:
from pyquery import PyQuery as Qimport requests
import json
r = requests.get('http://www.zhcw.com/ssq/kjgg/10006509.shtml')
str = Q(r.content)('#currentScript').html()
info = json.loads(str)[0]
print info
以上是 使用 Python 如何爬取这样的数据 BeautifulSoup?request? 的全部内容, 来源链接: utcz.com/a/165257.html