请问用LXML为什么无法爬取到指定网页中的这条信息?
https://www.che168.com/dealer/357032/37286245.html?pvareaid=100519&userpid=0&usercid=0&offertype=0#pos=1#page=1#rtype=10#isrecom=0#filter=36a469a0_0a0_0a0_0#module=10#refreshid=0#recomid=0#queryid=#cartype=70
这个是我要爬信息的网址
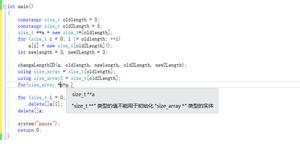
我用浏览器指定位置拷贝出来的 xpath地址为:/html/body/div[5]/div[2]/div[2]/s
我想提取出 新车价格 这个内容但是就是爬不到数据,请问这是怎么回事呢?其他的信息都能爬到。
回答:
可以将这条请求返回的html保存起来,然后查找s标签。
发现text文本中并不含实际的含税价。
<em class="price-transfer ndy">含过户费</em><s class="price-nom" id="newprice">新车含税价:0万</s>
说明实际数据,是通过返回json串加载上去的或者是通过js渲染上去的。
通过抓包工具,过滤动态请求,发现动态请求中并不包含数据。所以那一定是在返回的js文件中。
然后过滤返回js文件的请求,查看几项后找到了你要的数据。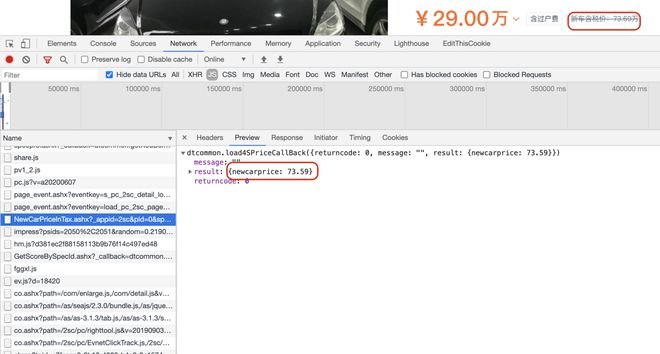
回答:
对于有js参与网页动态数据,有两种方式可抓取。一种如楼上所言,直接用js发起的访问数据源。另外一种则是获取js解析后的页面数据,然后再用你的方式像解析静态页面那样解析目标数据。这种若是python,通常借助Selenium(可进行交互)。若golang用ferret都可实现。
关键 你看到的页面是被(浏览器环境解析)js处理后的页面,抓取时得到的页面+js代码
回答:
Python爬取的是 浏览器右键 源文件 里的代码,开发工具看到的是JS解析以后的代码 两者不一样。
解决方案有2个:
1.使用支持JS解析的引擎 比如PyV8 pantomJS
2.自己找到存储价格的JS文件或者请求 另外单独写Python代码去解析。
以上是 请问用LXML为什么无法爬取到指定网页中的这条信息? 的全部内容, 来源链接: utcz.com/a/164285.html