数据抓包的时候数据过滤问题

https://china.guidechem.com/datacenter/msds/c/732.html
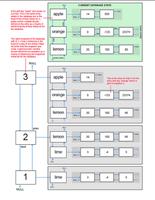
显示是这样
C4H8O;CH2CHOCH2CH3
但是抓到的数据是('分子式:', 'C', '4', 'H', '8', 'O;CH', '2', 'CHOCH', '2', 'CH', '3',) 这种改如何处理呢?求解答谢谢
回答:
你用哪个库爬取的。建议xpath:/html/body/div[2]/div[4]/div[2]/table/tbody/tr/td[3]/table/tbody/tr[6]/td[2];
结果是 C4H8O;CH2CHOCH2CH3
回答:
如果不考虑后续对分子式上下标的格式化处理,你直接抓取对应的td对象集就好了,然后用列表生成式处理td的文本节点内容。可以考虑google辅助xpath插件,直观简洁,自动生成xpath或CSS节点表达式
以上是 数据抓包的时候数据过滤问题 的全部内容, 来源链接: utcz.com/a/163832.html