爬虫遇到前端页面都是<p>标签,该怎么提取想要内容?
主要问题:网页前端代码很乱,全部都是<p>标签,python爬虫提取内容的时候很难受,BeautifulSoup4很难定位,求各位大神指导,遇到这种情况该怎么办?
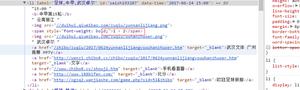
网址:http://eshu.100xuexi.com/uplo...

<body> <!--从word中提取的内容-->
<p class="ArtH2">
<a class="TocHref" name="_Toc636256162970488882">
2017年全国硕士研究生入学统一考试思想政治理论试题答案及详解
</a>
</p>
<p class="TiXing">
一、单项选择题(1~16小题,每小题1分,共16分。下列每题给出的四个选项中,只有一个选项是符合题目要求的。)
</p>
<p>
1.某地区进入供暖季后常常出现雾霾,而一旦出现大风天气或等到春暖花开后,雾霾就会散去或减少。从该地区较长时间的数据变化看,经过人们努力治霾,污染物排放总量在持续走低;但在某些时段,环境空气质量污染指数会迅速攀升,甚至“爆表”。这种看似“矛盾”的现象凸显了大气污染防治的一个特点:天帮忙很重要,但人努力才是根本。“人努力”与“天帮忙”之间对我们正确处理主观能动性和客观规律性之间辩证关系的启示是( )。
</p>
<p>
A.尊重事物的客观规律是正确发挥主观能动性的前提
</p>
<p>
B.人类有意识的思想活动是掌握客观规律的根本前提
</p>
<p>
C.认识活动是客观规律性与主观能动性相统一的基础
</p>
<p>
D.尚未认识的外在自然规律对人的实践活动起着至关重要的作用
</p>
<p class="TagBoxP">
<span class="AnsTag">
【答案】
</span>
A
</p>
<p class="TagBoxP">
<span class="KaodianTag">
【考点】
</span>
主观能动性和客观规律的关系
</p>
<p class="TagBoxP">
<span class="ResolveTag">
【解析】
</span>
主观能动性和客观规律性的关系为:
<span class="CNNum">
①
</span>
尊重客观规律是发挥主观能动性的前提;
<span class="CNNum">
②
</span>
在尊重客观规律的基础上充分发挥主观能动性。B项,实践决定认识,实践活动是人类认识和掌握客观规律的基础;C项,实践活动是客观规律性与主观能动性相统一的基础;D项,规律具有客观性,始终制约着人的实践活动,但是并不能在人类的实践活动中起着至关重要的作用。
</p>
<p>
2.有人认为,既然人的意识是对客观外部世界的反映,那么人脑里的“鬼”、“神”意识就是对外在世界上鬼、神真实存在的反映。这种观念的错误在于( )。
</p>
<p>
A.夸大了意识的能动作用
</p>
<p>
B.把意识看成是物质的产物
</p>
<p>
C.认为意识是对存在的直观反映
</p>
<p>
D.混淆了人类意识自然演化的阶段
</p>
<p class="TagBoxP">
<span class="AnsTag">
【答案】
</span>
C
</p>
<p class="TagBoxP">
<span class="KaodianTag">
【考点】
</span>
物质和意识的辩证关系
</p>
<p class="TagBoxP">
<span class="ResolveTag">
【解析】
</span>
意识从其本质来看是物质世界的主观映像,是客观内容和主观形式的统一。意识是物质的产物,但又不是物质本身,意识是特殊的物质——人脑的机能和属性,意识在内容上是客观的,在形式上是主观的。马克思指出“观念的东西不外是移入人的头脑并在人的头脑中改造过的物质的东西而已。”这表明,物质决定意识,意识依赖于物质并反作用于物质。
</p>
<p class="PSplit">
</p>
<p>
主要目的:

想把这些题目整理成包含:题目、选项、答案、解析等的数据库,比如这样:
我的代码:
import requestsfrom bs4 import BeautifulSoup
chapterurl="http://eshu.100xuexi.com/uploads/ebook/e512edf6fac442fbafa2d23e8f2c8c22/mobile/epub/OEBPS/chap9.html"
responce = requests.get(chapterurl)
print(responce.status_code)
responce.encoding = responce.apparent_encoding
res = responce.text
soup = BeautifulSoup(res,"lxml")
# 提取章节
chap = soup.find(class_="TocHref").get_text()
print(chap)
# 提取题型
TiXings = soup.findAll(class_="TiXing")
for TiXing in TiXings:
TiXing =TiXing.get_text().strip()
print(TiXing)
# 这里就该提取题目、选项、答案等,但是我不会了,找不到高效的方法。
再次感谢各位大神!
回答:
用正则表达式解析出来啊
回答:
个人觉得只能是找规律,将所有的p标签都直接去出来,按选择题和分析题进行切片,按标签规律进行提取.
以选择题为例,单选和多选的每道题都是8个p标签,每道题之间用了一个<p class="PSplit">的空标签间隔,直接上代码了:
#定义一个函数,将列表按指定长度进行切分def seg_list(l, n):
"""
:param l: List类型,需要等分的列表
:param n: 需要分割的份数
:return: 按指定份数分割好的嵌套列表
"""
if len(l) < n:
raise Exception('列表len()长度小于 被分割份数%s.请检查!' % (n,))
new_list = []
for i in range(n):
new_list.append([])
segment_num = 0
remainder = 0
segpoint = int(len(l) / n)
for num, key in enumerate(l, 1):
if segment_num < n:
if num % segpoint != 0:
new_list[segment_num].append(key)
else:
new_list[segment_num].append(key)
segment_num += 1
else:
new_list[remainder].append(key)
remainder += 1
编写爬虫,整理格式,提取选择题即可:
import requestsfrom bs4 import BeautifulSoup
url='http://eshu.100xuexi.com/uploads/ebook/e512edf6fac442fbafa2d23e8f2c8c22/mobile/epub/OEBPS/chap9.html'
res=requests.get(url)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'lxml')
total_list=soup.select('p')
mcp=total_list[2:299]#切片出所有选择题的标签
mcp.insert(8,None)#发现第一道题和第二道题之间少了一个<p class="PSplit">,补全格式统一化,
mcp.pop(144)#剔除多选题的说明,至此,格式已经统一,每9个p标签为一道题
result_list=seg_list(mcp,33)#将其切分为33道题
for i in result_list:
question=i[0].text
chioce_A=i[1].text
chioce_B=i[2].text
chioce_C=i[3].text
chioce_D=i[4].text
answer=i[5].text
test_point=i[6].text
analyze=i[7].text
print([question,chioce_A,chioce_B,chioce_C,chioce_D,answer,test_point,analyze])
至于分析题,也是有规律可循的
回答:
你的问题其实是想把HTML网页格式转化为Excel表格格式,直接可以在线转化,不用爬虫。。。
回答:
# 引入正则模块import re
# content 为你要提取的内容,爬取所有P标签的内容
content = re.findall('<p>(.*?)</p>', html.content.decode('utf-8'), re.S)
以上是 爬虫遇到前端页面都是<p>标签,该怎么提取想要内容? 的全部内容, 来源链接: utcz.com/a/163034.html