python 文件里的中文在 windows 下运行乱码
在 py 文件的头部加了
#!/usr/bin/env python# -*- coding: utf-8 -*-
而且有中文字符串的地方都用了u'中文字符串',但是在 windows 下还是乱码,linux 下不会,如何解决?
raw_input('中文字符串') 这个容易乱码,可以用这个来测试
回答:
我认为楼上的回答是不准确的.
以下是我在一个干净的XP(虚拟机)里用cmd跑python 2.7.3测试的结果:
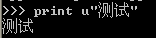
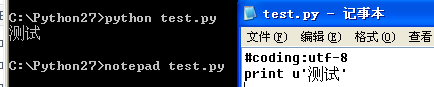
(文件另存为选择了UTF-8编码)
建议楼主在文件头加上
from __future__ import unicode_literals
然后去掉所有字符串前的 u, 这样所有字符串均默认为unicode串 :)
关于中文编码相关问题, 还可以参考 http://segmentfault.com/q/10100000000...
华丽的分割线raw_input 的地方我测试了, 确实得encode. 建议用mbcs(其实用sys的那几个get方法拿到的也是这个), 表示微软的格式.
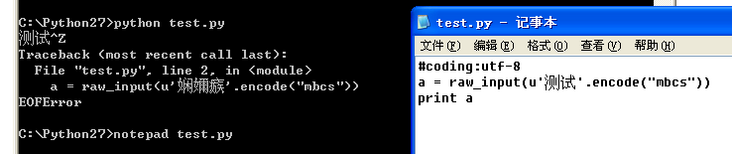
回答:
其实你用IDLE,不用微软的垃圾CMD就行了
回答:
修改成GBK即可
例如:

回答:
下面这个方法可以彻底解决!
1、确保py文件是UTF-8编码存档的。
2、在CMD窗口输入CHCP 65001 回车。(65001是win系统UTF-8的代码)
3、选择字体Lucida Console。说明:如果想在CMD显示更多的字体,在注册表(路径:HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionConsoleTrueTypeFont)中添加就好了。添加的字体需要是定宽的(fixed-width)。问题彻底解决。
以上是 python 文件里的中文在 windows 下运行乱码 的全部内容, 来源链接: utcz.com/a/162340.html