
如何在python中用正则表达式匹配md文件中所有的二级标题
import reregex = re.compile("##[\s,\w]\w+[\r,\n,\r\n,\w]$")
str1 = r"#标题\r\n## 标题一号\n##标题二号\r## 标题三号\r\n##标题四号"
print(re.findall(str1))
尝试这么写,想要的规则是:
以"##"开头,后面跟一个空格或字母/汉字,再跟上若干个任意字符(空格也行),最后以r或n或rn回车换行符结束
最后要求返回值是一个列表,每一项代表一个二级标题
回答:
为什么要用正则表达式匹配,直接读整个文件,然后把以##开头的行取出来然后去掉##不就行了吗。
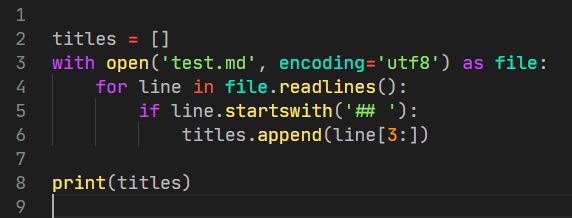
回答:
import restr='''
#标题
## 标题一号
##标题二号
## 标题三号
##标题四号
'''
result=re.findall(r'^##\s*([^#\n]+)',str,re.M)
print(result)
以上是 如何在python中用正则表达式匹配md文件中所有的二级标题 的全部内容, 来源链接: utcz.com/a/162177.html




