网页标签清洗
希望大佬能指点一二,小弟不胜感激
关于网页标签的清洗,在计算网页相似度的时候,哪些标签是可以过滤的,在这段代码生成的结果中
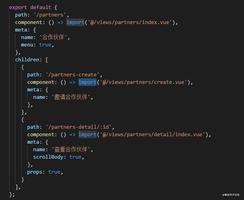
class Structure(HTMLParser): '''
pass
'''
def extract(self, html):
self.tmp = []
tag = ['script','style']
result = []
self.tagstack = []
self.feed(html)
for a in self.tmp:
if a.split('/')[-1] not in tag:
result.append(a)
return result
def handle_starttag(self, tag, attrs):
self.tagstack.append(tag)
def handle_endtag(self, tag):
self.tagstack.pop()
def handle_data(self, data):
t = ''
if data.strip():
for tag in self.tagstack:
t = t + '/' + tag
self.tmp.append(t)

用这个网页生成的结果举例,过滤/span/p结尾的标签,如果是其他的网页是不是也可以这么过滤,如果不是的话该怎么过滤,是不是还得考虑标签属性?
补充:计算的是网页结构相似度,不考虑正文相似度
回答:
假设你已经可以获得了网页标签结构,这里所说的标签结构指的是这样的情况
原网页A:
<html><head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
替换后B:
<html><head>
<title> </title>
</head>
<body>
<p class="title"><b> </b></p>
<p class="story">
<a href="http://example.com/elsie" class="sister" id="link1"> </a>
<a href="http://example.com/lacie" class="sister" id="link2"> </a>
<a href="http://example.com/tillie" class="sister" id="link3"> </a> </p>
<p class="story"> </p>
</body>
</html>
当然,如果你可以的话也可以忽略标签属性。比如C这样:
<html><head>
<title> </title>
</head>
<body>
<p><b> </b></p>
<p>
<a> </a>
<a> </a>
<a> </a> </p>
<p> </p>
</body>
</html>
假设网页D:
<html><head>
<title> </title>
</head>
<body>
<p><a> </a></p>
<p>
<b> </b>
<b> </b>
<b> </b> </p>
<p> </p>
</body>
</html>
基于以上的假设,来探讨问题,我想你需要的是有两个B类型或者C的文本,进行相似度判断。那么,我推荐你用simhash或者余弦相似性来做。
simhash,嗯广泛用于论文查重和网络爬虫里面。而余弦相似性在NLP里面属于较为容易入门的算法。
使用余弦相似性的算法,应该先考虑停止词。对于C类型的标签来说,可以忽略的我想不应该是script这种标签。而是html,head,title,body,mate这种大多数网页都会有的标签。这对于判断没有任何作用。
接下来统计一下其他标签的数目:
对于C<p></p>6
<b></b>2
<a></a>6
对于D
<p></p>6
<a></a>2
<b></b>6
根据这一组数据绘制向量:
C:<p></p>:6 <b></b>:2 <a></a>6D:<p></p>:6 <b></b>:6 <a></a>2
C:[6,2,6]
D:[6,6,2]
然后根据公式,算答案保留四位小数:0.7895
至于度量值如何需要有你自己来定~但是真的建议你使用simhash来做。
事件仓促= =有时间再来改排版填坑~
以上是 网页标签清洗 的全部内容, 来源链接: utcz.com/a/160278.html