如何爬万达电影官网上的订票信息
想在万达电影官网上订《霍比特人2:史矛革之战》的影票(明天、IMAX-3D),但现在还没开始卖。
网址是http://www.wandafilm.com/trade/movie_times.jsp,网页截图如下: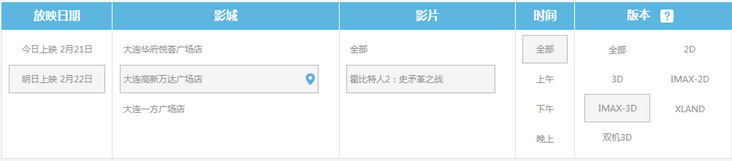
我想写个小程序每过几分钟就按图中的选项检查一下是否有票了
想法是这样的:
1.因为只要是这个订票页面,不管你选择哪个选项网址都不会变,所以应该不能取得整个网页然后解析。
2.然后通过wireshark监听了一下http数据,发现发送请求是:
GET /trade/time.do?m=init&city_code=undefined&cinema_id=842&day=2014_02_22&rond=0.22890089126303792&_=1392950290319 HTTP/1.1
在这个GET请求中并没有看到与影片名/时间/版本相关的数据,另外我点击“影片”/“时间”/“版本”时wireshark都监听不到流量
到这里就不知道怎么做了,之前只用python和c#爬过一次网页,所以没什么这方面的经验,请赐教。
回答:
在你打开网页的时候(还没有选择的时候),已经加载了所有的电影信息,通过如下URL:
http://www.wandafilm.com/js/jsArray/cinemaArray.js
回答:
我想你该试试phantom
回答:
scrapy是python的一个不错爬虫框架。
以上是 如何爬万达电影官网上的订票信息 的全部内容, 来源链接: utcz.com/a/160108.html