关于pyspider绕过CloudFlare验证的问题
问题在最后。
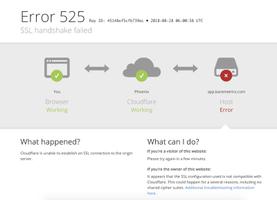
爬一个网站,遇到下图的cloudflare5秒验证
搜索了一下发现pyspider的github的issues里面已经有人指出了可以使用Anorov/cloudflare-scrape来绕过并且还提交了pull requests:
https://github.com/binux/pyspider/pull/635
但是binux指出可以直接参考https://github.com/Anorov/cloudflare-scrape#integration来使用,而不用增加一种新的fetch type。
我简单测试了一下,发现Anorov/cloudflare-scrape无法绕过我需要爬取的网站获取到内容,但是找到了看起来差不多但略有增强的一个包可以绕过:
https://github.com/VeNoMouS/cloudscraper
主要是通过使用该包的get_tokens方法获取cookies和user_agent传给pyspider来绕过,代码如下:
from pyspider.libs.base_handler import *import cloudscraper
def getheader(url):
cookie_value, user_agent = cloudscraper.get_tokens(url, browser={'browser': 'chrome', 'mobile': False})
return cookie_value, user_agent
class Handler(BaseHandler):
cookie_value, user_agent = getheader('https://somesite.com/')
crawl_config = {
'headers': {
'User-Agent': user_agent
},
'cookies': cookie_value
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://somesite.com/', callback=self.index_page)
@config(age=1 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('article').items():
url = each('a').attr.href
self.crawl(url, callback=self.book_page, save={'url1': url})
# 下一页
self.crawl(response.doc('li.next-page > a').attr.href, callback=self.index_page)
……后面省略
经过测试,该代码能够顺利绕过cloudflare并获取到result。
但是问题来了:在web测试里面基本没有问题,只有极其小的概率会出现验证问题(提示出现了recaptcha验证)。
但是让代码running起来之后,一开始能抓取一些页面,一旦中途有问题出现或者暂停了一段时间后面就是大面积错误,事实上代码此后就等同于失效了。
我想是不是获取的headers和cookies存储在scheduler里面,出错或者暂停之后下次再运行的时候还是用之前获取的headers和cookies,结果就造成了无法通过验证。
或者也许是同一个ip访问太过频繁被封锁,但是出现错误之后我用web调试还是能够获取结果的。
不知道哪里不对,哪位热心的朋友能够给点建议吗?
以上是 关于pyspider绕过CloudFlare验证的问题 的全部内容, 来源链接: utcz.com/a/159859.html