请教如何把HTML中的文本提取出来 放入字典中
请教python如何把下面网页中的文本提取出来并写入到字典中:例如 movie={"导演":"李志毅","编剧":"李志毅","主演":"梁家辉/郑伊健/陈慧琳",.....} 谢谢!
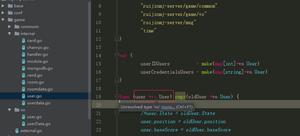
【HTML网页源码】如下:
<div id="movie_info" style="height: 100%;">导演:
<a href="https://www.btdx8.com/tag/%e6%9d%8e%e5%bf%97%e6%af%85" rel="bookmark">李志毅</a>
<br>
编剧: 李志毅
<br>
主演:
<a href="https://www.btdx8.com/tag/%e6%a2%81%e5%ae%b6%e8%be%89" rel="bookmark">梁家辉</a>
/
<a href="https://www.btdx8.com/tag/%e9%83%91%e4%bc%8a%e5%81%a5" rel="bookmark">郑伊健</a>
/
<a href="https://www.btdx8.com/tag/%e9%99%88%e6%85%a7%e7%90%b3" rel="bookmark">陈慧琳</a>
/
<a href="https://www.btdx8.com/tag/%e6%9b%be%e5%bf%97%e4%bc%9f" rel="bookmark">曾志伟</a>
/
<a href="https://www.btdx8.com/tag/%e7%8e%8b%e7%a5%96%e8%93%9d" rel="bookmark">王祖蓝</a>
/
<a href="https://www.btdx8.com/tag/%e7%8e%8b%e7%b4%ab%e9%80%b8" rel="bookmark">王紫逸</a>
/
<a href="https://www.btdx8.com/tag/%e7%8e%8b%e6%a7%8a" rel="bookmark">王槊</a>
/
<a href="https://www.btdx8.com/tag/%e5%88%98%e7%a2%a7%e4%b8%bd" rel="bookmark">刘碧丽</a>
/
<a href="https://www.btdx8.com/tag/%e5%bb%96%e5%90%af%e6%99%ba" rel="bookmark">廖启智</a>
/
<a href="https://www.btdx8.com/tag/%e8%bd%a6%e5%a9%89%e5%a9%89" rel="bookmark">车婉婉</a>
/
<a href="https://www.btdx8.com/tag/%e9%bb%8e%e8%8a%b7%e7%8f%8a" rel="bookmark">黎芷珊</a>
/
<a href="https://www.btdx8.com/tag/%e9%99%88%e6%bb%a2" rel="bookmark">陈滢</a><br>
类型: 喜剧 / 动作 / 爱情 / 悬疑
<br>
制片国家/地区: 中国大陆 / 香港
<br>
语言: 汉语普通话 / 粤语
<br>
上映日期: 2014-03-21(中国大陆) / 2014-03-27(香港)
<br>
片长: 105分钟
<br>
又名: 贩马记 / Horseplay</div>
【原图样式】:

回答:
参考 https://segmentfault.com/a/11...
回答:
太久没用python了, 提一个思路。
你可以先找到 div 这个元素,在得到他的文本值(不包含html内容),在使用正则
回答:
使用爬虫,针对标签进行解析,解析完保存到数据库中;
scrapy爬虫例子:https://segmentfault.com/a/11...
回答:
把每个字段提取出来没问题吧,比如主演、导演等信息。
例如:
导演 = re.search('>(.*?)<',html).group(1) #实际情况不能用中文作为变量名
先可以创建一个空字典:
data = {}
data['导演'] = 导演
这样就把导演这个值写入了字典。
以上是 请教如何把HTML中的文本提取出来 放入字典中 的全部内容, 来源链接: utcz.com/a/159289.html