Python selenium 如何爬取页面折叠数据 (read more按钮)
大家好
这个是示例页面
https://www.edmunds.com/bmw/1...
想请问中间那个expert review里面的read more怎么展开 目标是爬取所有文字评论内容 现在只能爬到一部分
rev=driver.find_elements_by_xpath("//div[@class='size-16']//p")
for p in expertrev:rev0=p.textprint(rev0)
回答:
两种思路:①不要去做渲染,也就是直接请求原始页面。然后用lxml或者BS去做解析。②使用Selenium模拟浏览器请求,然后再做解析。
# 获取数据前 模拟点击一下`Read more`按钮即可。read_more_btn = driver.find_element_by_xpath('//div[@class="container"]//button/span')
read_more_btn.click()
查看网页原始数据时,使用右键 --> 显示网页源代码
回答:
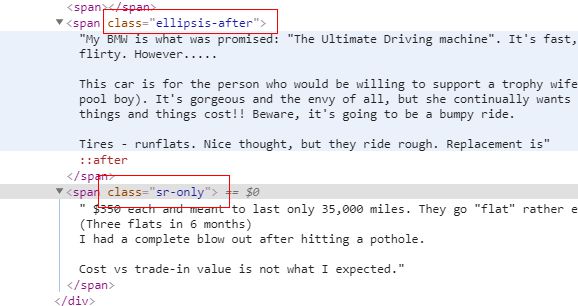
不是2种span嘛
你依次获取拼接即可
以上是 Python selenium 如何爬取页面折叠数据 (read more按钮) 的全部内容, 来源链接: utcz.com/a/158483.html