中文URL的编码问题
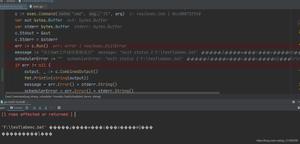
在自己的网站中(基于tornado),如果URL中含有中文,没有urlencode的话,搜索引擎爬过来会出现decode的异常:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xe5 in position 6: invalid continuation byte
如果是urlencode过的便可以正常解析。但是,我发现豆瓣的tag好多也都是没有urlencode的URL(如下图),请问这样不会出现问题吗?
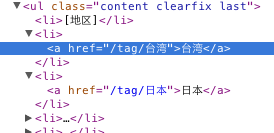
可以在nginx上做统一转换吗?
回答:
把代码的编码格式换成utf8试试
回答:
如果使用urllib2,可以用下面的方法进行encode
urllib2.quote(s.encode("utf-8"))
回答:
网页里可以这样写是因为浏览器会自动用UTF-8或者当前页面的编码来对URL编码。你用HTTP抓包工具看一下,可以看到发给服务器的URL实际上是经过编码的,类似于这样:
http://movie.douban.com/tag/%E7%BE%8E%E5%9B%BD
服务器收到的已经是编码过的URL了。
至于爬虫会怎么处理这样的URL,那就得看各家公司怎么实现了。至少Google的爬虫应该足够智能,会自动替你做URL编码。
以上是 中文URL的编码问题 的全部内容, 来源链接: utcz.com/a/158146.html