python爬虫爬取网页遇到Javascript is required
爬取网页的时候,爬取不到源码,显示<noscript>Javascript is required. Please enable javascript before you are allowed to see this page.</noscript>
去论坛里搜索了问题,发现好像只有我一个人有这个问题
下面是我的代码
// 请把代码文本粘贴到下方(请勿用图片代替代码)
def get_page(page):
url = 'http://cambb.cc/forum.php?'data={
"mod":"forumdisplay",
"fid":"37",
'filter':'',
"orderby":"lastpost",
"page":page,
"t":"1892855",
}
headers={
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'User-Agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/69.0.3497.100Safari/537.36',
'Accept':'*/*',
'Referer':'http://cambb.cc/forum.php?mod=forumdisplay&fid=37',
'X-Requested-With':'XMLHttpRequest',
'Connection':'keep-alive',
'Host':'cambb.cc',
'Cookie':'prhF_2132_saltkey=AzXzRRx7; prhF_2132_lastvisit=1541264796; prhF_2132_nofavfid=1; prhF_2132_smile=1D1; sucuri_cloudproxy_uuid_79c74ae60=0b002e4f44799010d471d1ac30792e43; prhF_2132_auth=d52cMREMy0bxoLJZpaewtEdQ5OoPl%2FMq7ObQuI3%2B%2FtX9wT3KnvTSpZ%2BLHVYBg63fBnzztNHCgpudNYlBodYOPRfY; prhF_2132_lastcheckfeed=5862%7C1541315119; prhF_2132_home_diymode=1; prhF_2132_visitedfid=37D40D2D36; vClickLastTime=a%3A4%3A%7Bi%3A0%3Bb%3A0%3Bi%3A2414%3Bi%3A1541260800%3Bi%3A2459%3Bi%3A1541260800%3Bi%3A2433%3Bi%3A1541260800%3B%7D; prhF_2132_st_p=5862%7C1541318034%7Ce7c1eea8356bda291aed74ccdb20537d; prhF_2132_viewid=tid_2303; prhF_2132_sid=zHIuFg; prhF_2132_lip=182.148.204.234%2C1541317606; prhF_2132_ulastactivity=2369H6awa8fQve9%2BQr8p8MzIVU3ieAbL9rm7Idao%2FRlbwrDEtV2S; prhF_2132_checkpm=1; prhF_2132_sendmail=1; prhF_2132_st_t=5862%7C1541339179%7C6fbad6f782ca1ec63109b566edb0888c; prhF_2132_forum_lastvisit=D_36_1541269244D_40_1541315980D_37_1541339179; prhF_2132_lastact=1541339180%09misc.php%09patch'
}
response = requests.get(url,params=data,headers=headers)
print(response.text)
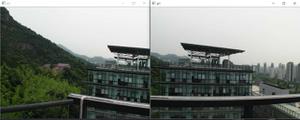
下面的图片是报错的结果

下面是浏览器展示的源码:
出线这种问题的原因是什么?是必须要先模拟加载javascript?希望能够帮忙讲解下原理?谢谢,非常感谢。
回答:
这不是错误,就算是错误也不是爬虫本身的错误。另外错误日志能复制的话就不要贴截图。
你会认为这是个错误并且无法自己解决这个问题说明你对前端完全不熟悉。你首先应该搜索noscript标签是什么,然后搞明白后面的script标签里的东西是干嘛用的。
然后回答你的问题,noscript标签的作用楼上已经说了,不过主要目的不是反爬,是在用户禁用js时给个友好的提示而不是直接白屏。注意到noscript标签底下还有script标签,这很明显就是网页的剩余内容需要由这段js加载,而爬虫不会执行页面里的js,你当然就抓不到想要的内容。
所以可以从这段js着手,如果你不想给你的爬虫加上一个浏览器依赖。这种用于加载内容的js无非使用了两种方法加载剩余内容:
- 内容本身已经在这段js中,这段js只是负责解密
- 这段js负责发送
ajax请求加载剩余内容,这段js负责渲染和/或解密请求返回的内容
所以你只要搞明白这段js干了什么就行了,然后用爬虫重复这一过程就行了。当然这种js大多经过混淆和/或压缩,研究它需要对js有一定的掌握,对于题主来说大概需要再找人帮忙解决这个问题了。
如果你不介意给你的爬虫加个浏览器依赖,可以使用谷歌浏览器的无头模式,无头chrome的python驱动找一下就有。
回答:

没搞过爬虫,仅供参考;你可以noscript和反爬虫为关键字搜搜。
以上是 python爬虫爬取网页遇到Javascript is required 的全部内容, 来源链接: utcz.com/a/157903.html