读者提问:为什么 HashMap 会发生数据覆盖问题
在 面试官你能不能别问我 HashMap 了? 这篇文章中,有读者问阿粉,不同的值相同的 hash 值为什么会被覆盖, hashmap 不是对相同的 hash 值有链表结构处理吗
阿粉今天就来谈谈这个,这个问题在 1.7 版本和 1.8 版本中都有,阿粉分别来说说
在说之前,咱们先要达成一个共识: HashMap 发生数据覆盖的问题,是在多线程环境 & 扩容下产生的,接下来咱们具体来看
jdk 1.7
1 | |
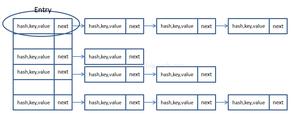
在扩容时,发生数据覆盖问题主要核心就是上面的代码,我们假设一下,刚开始时,结构是这样的:

现在有两个线程 A 和 B ,它们都要进行插入操作,首先 A 进行插入操作,经过 Hash 之后就得到了要落到的桶的索引坐标,运行到 newTable[i] = e; 这行代码时, CPU 时间片用完了,此时线程 A 就停止运行被挂起,这个时候是这个样子的:

线程 A 被挂起之后,线程 B 被调度得以运行,巧的是,线程 B 经过 Hash 之后得到的要落到的桶索引坐标和线程 A 一样,此时线程 B 也进行插入操作,线程 B 因为时间片足够用,所以就成功的将记录插入到了桶里面:

线程 B 插入成功之后,根据 Java 内存模型,此时主内存中存放的值就是线程 B 运行之后的结果
接下来线程 A 被唤醒,继续执行插入操作。对于 A 来说,前面的步骤都已经执行过了,所以就不需要再次运行,直接从 newTable[i] = e; 这行代码开始往下继续运行即可,线程 A 保存的环境是 e = 12next = 6e.next = newTable[i]; 即 newTable[3] = null; ,那么接下来执行 newTable[i] = e; & e = next 也就是 newTable[3] = 12e = next = 6 执行完毕之后,大概就是这样:

元素 15 就这么被覆盖掉了
jdk 1.8
看完 1.7 之后,咱们再来看看 1.8 版本。数据覆盖主要发生在 put 操作中,下面是 1.8 源码(阿粉在这里截取了一小部分):
1 | |
在上面的代码中,我们能够看到,源码只是判断了 hash 是否有碰撞,如果没有就不再做别的检查进行插入操作
在多线程环境下,如果线程 1 检查完了 hash 没有碰撞,要进行插入时, CPU 时间片使用完毕,此时它被挂起,线程 2 开始跑,无巧不成书嘛,此时线程 2 经过 hash 之后得到的值和线程 1 的 hash 值一样,线程 2 将值插入进去,线程 1 恢复运行,因为前面检查了 hash 碰撞,此时插入时不再做任何检查,直接将值插入
那么线程 2 插入的值就被覆盖掉了
HashMap 之所以发生数据覆盖的问题,最主要的原因在于它没有加锁,所以在多线程环境下会发生数据覆盖问题
修正一个问题
在 面试官你能不能别问我 HashMap 了? 这篇文章中,阿粉说之所以是 8 转为红黑树,和时间复杂度有关,后来经过一位小伙伴留言才发现阿粉的思路错了,和泊松分布有关,这一点源码中也有说明:
1 | |
从源码中可以看到,在负载因子 0.75 ( HashMap 默认)的情况下,单个 hash 槽内元素个数为 8 的概率为 0.00000006,是相当小的一个值了,因此将 7 作为一个分水岭,等于 7 时不做转换,大于等于 8 才转红黑树,小于等于 6 才转链表。
哈希搅动和高低 16 位有关系吗?
有的小伙伴问阿粉,哈希搅动和高低 16 位有关系吗?
阿粉不太清楚这个有关系是怎样的一个有关系,但是 16 这个数字的选取,作者肯定也是经过考虑之后再决定的
哈希搅动主要发生在 resize() 这个方法中,我们可以看到源码中的注释:
1 | |
翻译一下就是:在初始化或者增加表大小时,如果没有指定,那么就按照初始容量来进行分配。如果指定了,由于使用的是 2 的幂,所以每个 bin 元素也必须保持相同的索引,或者在新表中以 2 的幂偏移
这样看的话,好像和 16 位有点儿关系
碎碎念
在上面提到的文章中,阿粉本来想一篇文章就把相关知识点说完的,结果发现越说越多,所以有的内容就没有深入写
有的读者就说,感觉其实没有写那么详细,阿粉就意识到犯了一个错误,一篇文章如果能够把一个点给读者讲明白,那么这篇文章就是有价值的,我有点儿贪婪了,想一篇文章讲完所有和 HashMap 相关的,阿粉在以后的文章中,尽量一篇文章只讲一个点,不贪多了
最后,读者们有什么建议,对文章中有疑惑的地方都可以提出来,毕竟阿粉这么宠你们,只要提要求,能满足的肯定就尽量满足咯~
以上是 读者提问:为什么 HashMap 会发生数据覆盖问题 的全部内容, 来源链接: utcz.com/a/131435.html