原来JVM垃圾回收是这么回事
最近想复习一下JVM的知识。然后发现网上不少文章在写JVM的垃圾回收算法时,都比较偏向于具体实现,而少有站在更高角度来看垃圾回收算法的文章。而我本人想对垃圾回收算法有个全景的认识,所以,就找到了这本《垃圾回收的算法与实现》(以下简称《垃圾回收》)。本篇博客就是尝试对“全景”的总结。
以下为方便讨论,垃圾回收缩写成GC。
为什么要有GC
我时而听到C++程序员说我们是被GC惯坏了的一代。的确是这样的,我本人在学习GC算法时,大脑里第一问题就是为什么需要GC这样的东西。说明我已经认为GC是理所当然了。
总的一句话:没有GC的世界,我们需要手动进行内存管理,而手动内存管理是纯技术活,又容易出错。
既然我们写的大多程序都是为了解决现实业务问题,那么,我们为什么不把这种纯技术活自动化呢?但是自动化,也是有代价的。这是我的个人理解,不代表John McCarthy本人的理解。
“垃圾”的定义
首先,我们要给个“垃圾”的定义,才能进行回收吧。书中给出的定义:把分配到堆中那些不能通过程序引用的对象称为非活动对象,也就是死掉的对象,我们称为“垃圾”。
GC的定义
因为我们期望让内存管理变得自动(只管用内存,不管内存的回收),我们就必须做两件事情: 1. 找到内存空间里的垃圾;2. 回收垃圾,让程序员能再次利用这部分空间 。(《垃圾回收》 P2)只要满足这两项功能的程序,就是GC,不论它是在JVM中,还是在Ruby的VM中。
但这只是两个需求,并没有说明GC应该何时找垃圾,何时回收垃圾等等更具体的问题,各类GC算法就是在这些更具体问题的处理方式上施展手脚。
GC的历史
John McCarthy身为Lisp之父和人工智能之父,同时,他也是GC之父。1960年,他在其论文中首次发布了GC算法(其实是委婉的提出)。
- 标记-清除算法 由John McCarthy在1960年提出
- 引用计数法 由George E. Collins在1960年提出。此算法会有循环引用问题,Harold McBeth 1963年指出。
- 复制算法 由Marvin L. Minsky在1963年提出
《垃圾回收》的作者认为:
从50年前GC算法首次发布以来,众多研究者对其进行了各种各样的研究,因此许多GC算法也得以发布。但事实上,这些算法只不过是把前文中提到的三种算法进行组合或应用。也可以这么说,1963年GC复制算法诞生时,GC的根本性内容就已经完成了。(《垃圾回收》 P4)
那我们常常听说的分代垃圾回收又是怎么回事?作者是这样说的:人们从众多程序案例中总结出了一个经验:“大部分的对象在生成后马上就变成了垃圾,很少有对象能活得很久”。分代垃圾回收利用该经验,在对象中导入了“年龄”的概念,经历过一次GC后活下来的对象年龄为1岁。(垃圾回收》 P141)
分代垃圾回收中把对象分类成几代,针对不同的代使用不同的GC算法,我们把刚生成的对象称为新生代对象,到达一定年龄的对象则称为老年代对象。(《垃圾回收》 P142)
好了,这下我总算知道为什么要分代了,我的总结是: 将对象根据存活概率进行分类,对存活时间长一些的对象,可以减少扫描“垃圾”的时间,以减少GC频率和时长。根本思路就是对对象进行分类,才能针对各个分类采用不同的垃圾回收算法,以对各算法进行扬长避短。
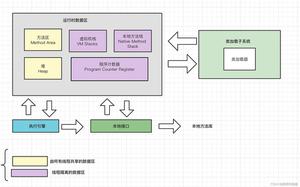
留一个问题给读者:我们知道分代垃圾回收所采用的堆结构是:

为什么新生代空间要分成“生成空间”和“幸存空间”,而幸存空间又分成两块大小相等的幸存空间1,幸存空间2?
这些GC算法共同解决的问题
上面我们说了,GC的定义只给出了需求,三种算法都为实现这个需求,那么它们总会遇到共同要解决的问题吧? 我尝试总结出:
- 如何分辨出什么是垃圾?
- 如何、何时搜索垃圾?
- 如何、何时清除垃圾?
这样,只要涉及到垃圾回收,我就可以从这2点需求,3个共同问题(两点三共)出发来讨论、学习。
如何评价GC算法?
如果没有评价标准,我们当然无法评估这些GC算法的性能。作者给出了4个标准:
- 吞吐量: 单位时间内的处理能力
- 最大暂停时间:GC执行过程中,应用暂停的时长。较大的吞吐量和较短的最大暂停时间不可兼得
- 堆的使用效率:就是堆空间的利用率。可用的堆越大,GC运行越快;相反,越想有效地利用有限的堆,GC花费的时间就越长。
- 访问的局部性:把具有引用关系的对象安排在堆中较近的位置,就能提高在缓存中读取到想利用的数据的概率。
好吧。两点三共,四标~
小结
搞清楚为什么要GC,要实现GC都要解决什么问题,而各类算法又是怎么解决的,最后怎么评价这些算法。GC原来是这么回事。
但是这不是GC的全部。但是提供我一个思考GC的思考框架。
以上就是《垃圾回收的算法与实现》的读书笔记。如果想更深入,可以阅读《垃圾回收算法手册:自动内存管理的艺术》。
以上是 原来JVM垃圾回收是这么回事 的全部内容, 来源链接: utcz.com/a/128298.html