【java】Java踩坑记系列之线程池
线程池大家都很熟悉,无论是平时的业务开发还是框架中间件都会用到,大部分都是基于JDK线程池ThreadPoolExecutor做,的封装,比如tomcat的线程池,当然也有单独开发的,但都会牵涉到这几个核心参数的设置:核心线程数,等待队列,最大线程数,拒绝策略等。
先说下我们项目组在使用线程池时踩到的坑:
- 线程池的参数设置一定要结合具体的业务场景,区分I/O密集和CPU密集,如果是I/O密集型业务,核心线程数,
workQueue等待队列,最大线程数等参数设置不合理不仅不能发挥线程池的作用,反而会影响现有业务 - 等待队列
workQueue填满后,新创建的线程会优先处理新请求进来的任务,而不是去处理队列里的任务,队列里的任务只能等核心线程数忙完了才能被执行。有可能造成队列里的任务长时间等待,导致队列积压,尤其是I/O密集场景 - 如果需要得到线程池里的线程执行结果,使用
future的方式,拒绝策略不能使用DiscardPolicy,这种丢弃策略虽然不执行子线程的任务,但是还是会返回future对象(其实在这种情况下我们已经不需要线程池返回的结果了),然后后续代码即使判断了future!=null也没用,这样的话还是会走到future.get()方法,如果get方法没有设置超时时间会导致一直阻塞下去!
伪代码如下:
// 如果线程池已满,新的请求会直接执行拒绝策略Future<String> future = executor.submit(() -> {
// 业务逻辑,比如调用第三方接口等耗时操作放在线程池里执行
return result;
});
// 主流程调用逻辑
if(future != null) // 如果拒绝策略设置不合理还是会走到下面代码
future.get(超时时间); // 调用方阻塞等待结果返回,直到超时
下面就结合实际业务情况逐一进行分析。
当然这些问题一部分是对线程池理解不够导致的,还有一部分是线程池本身的问题。
一. 背景
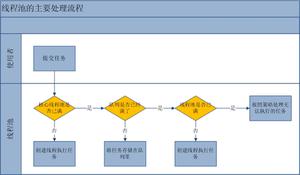
公司有个接口部分功能使用了线程池,这个功能不依赖核心接口,但有一定的耗时,所以放在线程池里和主线程并行执行,等线程池里的任务执行完通过future.get的方式获取线程池里的线程执行结果,然后合并到主流程的结果里返回给前端,业务场景很简单,大致流程如下:

初衷也是为了不影响主流程的性能,不增加整体响应时间。
但是之前使用的线程池jdk的newCachedThreadPool,因为sonar扫描提示说有内存溢出的风险(最大线程数是Integer.MAX_VALUE)所以当时改成使用原生的ThreadPoolExecutor,通过指定核心线程数和最大线程数,来解决sonar问题。
但是改过的线程池并不适合我们这种I/O密集型的业务场景(大部分业务都是通过调用接口实现的),当时设置的核心线程数是cpu核数(线上机器是4核),等待队列是2048,最大线程数是cpu核数*2,从而引发了一系列问题。。。
二. 排查过程
上线后的现象是使用线程池的接口整体响应时间变长,有的甚至到10秒才返回数据,通过线程dump分析发现有大量的线程都阻塞在future.get方法上,如下:

future.get方法会阻塞当前主流程,在超时时间内等待子线程返回结果,如果超时还没结果则结束等待继续执行后续的代码,超时时间设置的是默认接口超时时间10秒(后面已改为200ms),至此可以确定接口总耗时是因为流程都卡在了future.get这一步了。
但这不是根本原因,future是线程池返回的,伪代码如下:
Future<String> future = executor.submit(() -> {// 业务逻辑,比如调用第三方接口等耗时操作放在线程池里执行
return result;
});
通过上面的代码可知future没有结果的原因是提交到线程池里的任务迟迟没有被执行。
那为什么没有执行呢?继续分析线程池的dump文件发现,线程池里的线程数已达到最大数量,满负荷运行,如图:

SubThread是我们自己定义的线程池里线程的名字,8个线程都是runnable状态,说明等待队列里已经塞满任务了,之前设置的队列长度是2048,也就是说还有2048个任务等待执行,这无疑加剧了整个接口的耗时。
线程池的执行顺序是:核心线程数 -> 等待队列 -> 最大线程数 -> 拒绝策略
如果对线程dump分析不太了解的可以看下之前的一篇文章:Windows环境下如何进行线程dump分析,虽然环境不一样但原理类似。
这里基本确定接口耗时变长的主要原因是线程池设置不合理导致的。
另外还有一些偶发问题,就是线上日志显示虽然线程池执行了,但是线程池里的任务却没有记录运行日志,线程池里的任务是调用另外一个服务的接口,和对方接口负责人确认也确实调用了他们的接口,可我们自己的日志里却没有记录下调用报文,经过进一步查看代码发现当时的线程池拒绝策略也被修改过,并不是默认的抛出异常不执行策略AbortPolicy,而是设置的CallerRunsPolicy策略,即交给调用方执行!


也就是说当线程池达到最大负荷时执行的拒绝策略是让主流程去执行提交到线程池里的任务,这样除了进一步加剧整个接口的耗时外,还会导致主流程被hang死,最关键的是无法确定是在哪一步执行提交到线程池的任务。
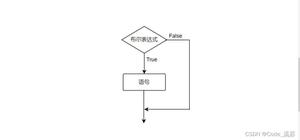
分析日志埋点可以推断出调用的时间点应该是已经调用完了记录日志的方法,要返回给前端结果的时才执行线程池里任务,此时记录日志的方法已调用过,不会再去打印日志了,而且子任务返回的结果也无法合并到主流程结果里,因为合并主流程结果和线程池任务返回结果的方法也在之前调用过,不会回过头来再调用了,大致流程如下:

其实这种拒绝策略并不适合我们现在的业务场景,因为线程池里的任务不是核心任务,不应该影响主流程的执行。
三. 改进
- 调整线程池参数,核心线程数基于线上接口的QPS计算,最大线程数参考线上tomcat的最大线程数配置,能够cover住高峰流量,队列设置的尽量小,避免造成任务挤压。关于线程数如何设置会在后续文章中单独讲解。
- 扩展线程池,封装原生JDK线程池
ThreadPoolExecutor,增加对线程池各项指标的监控,包括线程池运行状态、核心线程数、最大线程数、任务等待数、已完成任务数、线程池异常关闭等信息,便于实时监控和定位问题。 - 重写线程池拒绝策略,主要也是记录超出线程池负载情况下的各项指标情况,以及调用线程的堆栈信息,便于排查分析,通过抛出异常方式中断执行,避免引用的future不为null的问题。
- 合理调整
future.get超时时间,防止阻塞主线程时间过长。
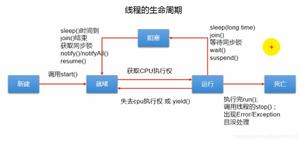
线程池内部流程:

线程池监控和自定义拒绝策略的代码如下,大家可以结合自己的业务场景使用:
package com.javakk;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.text.MessageFormat;
import java.util.List;
import java.util.concurrent.*;
/**
* 自定义线程池<p>
* 1.监控线程池状态及异常关闭等情况<p>
* 2.监控线程池运行时的各项指标, 比如:任务等待数、已完成任务数、任务异常信息、核心线程数、最大线程数等<p>
* author: 老K
*/
public class ThreadPoolExt extends ThreadPoolExecutor{
private static final Logger log = LoggerFactory.getLogger(ThreadPoolExt.class);
private TimeUnit timeUnit;
public ThreadPoolExt(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
{
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
this.timeUnit = unit;
}
@Override
public void shutdown() {
// 线程池将要关闭事件,此方法会等待线程池中正在执行的任务和队列中等待的任务执行完毕再关闭
monitor("ThreadPool will be shutdown:");
super.shutdown();
}
@Override
public List<Runnable> shutdownNow() {
// 线程池立即关闭事件,此方法会立即关闭线程池,但是会返回队列中等待的任务
monitor("ThreadPool going to immediately be shutdown:");
// 记录被丢弃的任务, 暂时只记录日志, 后续可根据业务场景做进一步处理
List<Runnable> dropTasks = null;
try {
dropTasks = super.shutdownNow();
log.error(MessageFormat.format("ThreadPool discard task count:{0}", dropTasks.size()));
} catch (Exception e) {
log.error("ThreadPool shutdownNow error", e);
}
return dropTasks;
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
// 监控线程池运行时的各项指标
monitor("ThreadPool monitor data:");
}
@Override
protected void afterExecute(Runnable r, Throwable ex) {
if (ex != null) { // 监控线程池中的线程执行是否异常
log.error("unknown exception caught in ThreadPool afterExecute:", ex);
}
}
/**
* 监控线程池运行时的各项指标, 比如:任务等待数、任务异常信息、已完成任务数、核心线程数、最大线程数等<p>
*/
private void monitor(String title){
try {
// 线程池监控信息记录, 这里需要注意写ES的时机,尤其是多个子线程的日志合并到主流程的记录方式
String threadPoolMonitor = MessageFormat.format(
"{0}{1}core pool size:{2}, current pool size:{3}, queue wait size:{4}, active count:{5}, completed task count:{6}, " +
"task count:{7}, largest pool size:{8}, max pool size:{9}, keep alive time:{10}, is shutdown:{11}, is terminated:{12}, " +
"thread name:{13}{14}",
System.lineSeparator(), title, this.getCorePoolSize(), this.getPoolSize(),
this.getQueue().size(), this.getActiveCount(), this.getCompletedTaskCount(), this.getTaskCount(), this.getLargestPoolSize(),
this.getMaximumPoolSize(), this.getKeepAliveTime(timeUnit != null ? timeUnit : TimeUnit.SECONDS), this.isShutdown(),
this.isTerminated(), Thread.currentThread().getName(), System.lineSeparator());
log.info(threadPoolMonitor);
} catch (Exception e) {
log.error("ThreadPool monitor error", e);
}
}
}
自定义拒绝策略代码:
package com.javakk;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.lang.management.*;
import java.text.MessageFormat;
import java.util.concurrent.RejectedExecutionException;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 自定义线程池拒绝策略:<p>
* 1.记录线程池的核心线程数,活跃数,已完成数等信息,以及调用线程的堆栈信息,便于排查<p>
* 2.抛出异常中断执行<p>
* author: 老K
*/
public class RejectedPolicyWithReport implements RejectedExecutionHandler {
private static final Logger log = LoggerFactory.getLogger(RejectedPolicyWithReport.class);
private static volatile long lastPrintTime = 0;
private static final long TEN_MINUTES_MILLS = 10 * 60 * 1000;
private static Semaphore guard = new Semaphore(1);
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
try {
String title = "thread pool execute reject policy!!";
String msg = MessageFormat.format(
"{0}{1}core pool size:{2}, current pool size:{3}, queue wait size:{4}, active count:{5}, completed task count:{6}, " +
"task count:{7}, largest pool size:{8}, max pool size:{9}, keep alive time:{10}, is shutdown:{11}, is terminated:{12}, " +
"thread name:{13}{14}",
System.lineSeparator(), title, e.getCorePoolSize(), e.getPoolSize(), e.getQueue().size(), e.getActiveCount(),
e.getCompletedTaskCount(), e.getTaskCount(), e.getLargestPoolSize(), e.getMaximumPoolSize(), e.getKeepAliveTime(TimeUnit.SECONDS),
e.isShutdown(), e.isTerminated(), Thread.currentThread().getName(), System.lineSeparator());
log.info(msg);
threadDump(); // 记录线程堆栈信息包括锁争用信息
} catch (Exception ex) {
log.error("RejectedPolicyWithReport rejectedExecution error", ex);
}
throw new RejectedExecutionException("thread pool execute reject policy!!");
}
/**
* 获取线程dump信息<p>
* 注意: 该方法默认会记录所有线程和锁信息虽然方便debug, 使用时最好加开关和间隔调用, 否则可能会增加latency<p>
* 1.当前线程的基本信息:id,name,state<p>
* 2.堆栈信息<p>
* 3.锁相关信息(可以设置不记录)<p>
* 默认在log记录<p>
* @return
*/
private void threadDump() {
long now = System.currentTimeMillis();
// 每隔10分钟dump一次
if (now - lastPrintTime < TEN_MINUTES_MILLS) {
return;
}
if (!guard.tryAcquire()) {
return;
}
// 异步dump线程池信息
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.execute(() -> {
try {
ThreadMXBean threadMxBean = ManagementFactory.getThreadMXBean();
StringBuilder sb = new StringBuilder();
for (ThreadInfo threadInfo : threadMxBean.dumpAllThreads(true, true)) {
sb.append(getThreadDumpString(threadInfo));
}
log.error("thread dump info:", sb.toString());
} catch (Exception e) {
log.error("thread dump error", e);
} finally {
guard.release();
}
lastPrintTime = System.currentTimeMillis();
});
pool.shutdown();
}
@SuppressWarnings("all")
private String getThreadDumpString(ThreadInfo threadInfo) {
StringBuilder sb = new StringBuilder("\"" + threadInfo.getThreadName() + "\"" +
" Id=" + threadInfo.getThreadId() + " " +
threadInfo.getThreadState());
if (threadInfo.getLockName() != null) {
sb.append(" on " + threadInfo.getLockName());
}
if (threadInfo.getLockOwnerName() != null) {
sb.append(" owned by \"" + threadInfo.getLockOwnerName() +
"\" Id=" + threadInfo.getLockOwnerId());
}
if (threadInfo.isSuspended()) {
sb.append(" (suspended)");
}
if (threadInfo.isInNative()) {
sb.append(" (in native)");
}
sb.append('\n');
int i = 0;
StackTraceElement[] stackTrace = threadInfo.getStackTrace();
MonitorInfo[] lockedMonitors = threadInfo.getLockedMonitors();
for (; i < stackTrace.length && i < 32; i++) {
StackTraceElement ste = stackTrace[i];
sb.append("\tat " + ste.toString());
sb.append('\n');
if (i == 0 && threadInfo.getLockInfo() != null) {
Thread.State ts = threadInfo.getThreadState();
switch (ts) {
case BLOCKED:
sb.append("\t- blocked on " + threadInfo.getLockInfo());
sb.append('\n');
break;
case WAITING:
sb.append("\t- waiting on " + threadInfo.getLockInfo());
sb.append('\n');
break;
case TIMED_WAITING:
sb.append("\t- waiting on " + threadInfo.getLockInfo());
sb.append('\n');
break;
default:
}
}
for (MonitorInfo mi : lockedMonitors) {
if (mi.getLockedStackDepth() == i) {
sb.append("\t- locked " + mi);
sb.append('\n');
}
}
}
if (i < stackTrace.length) {
sb.append("\t...");
sb.append('\n');
}
LockInfo[] locks = threadInfo.getLockedSynchronizers();
if (locks.length > 0) {
sb.append("\n\tNumber of locked synchronizers = " + locks.length);
sb.append('\n');
for (LockInfo li : locks) {
sb.append("\t- " + li);
sb.append('\n');
}
}
sb.append('\n');
return sb.toString();
}
}
以上是 【java】Java踩坑记系列之线程池 的全部内容, 来源链接: utcz.com/a/125314.html