读Kafka源码架构简介
这个 Kafka 的专题,我会从系统整体架构,设计到代码落地。和大家一起杠源码,学技巧,涨知识。希望大家持续关注一起见证成长!
我相信:技术的道路,十年如一日!十年磨一剑!
往期文章
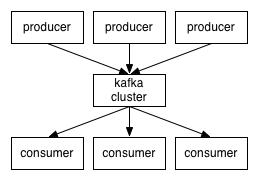
Kafka 探险 - 架构简介
Kafka 探险 - 源码环境搭建
Kafka 探险 - Kafka 探险 - 生产者源码分析: 核心组件
前言
首先还是看一眼 Kafka 生产者中的方法,核心分为三类:构造器,消息发送,其他。

我们今天要探讨的是在构造器中初始化配置时用到的配置类,看起来是构造方法中一个不起眼的参数,但是代码中暗藏了很多技巧。而这些技巧应用于平时的开发,也能让我们在写业务代码的时享受到写底层中间件的感觉,让代码看起来简洁,健壮,易扩展,有层次。

四个构造方法,其余三个构造器最终都调用到 :KafkaProducer(ProducerConfig, Serializer<K>, Serializer<V>)
第一个参数是 生产者配置类,他继承了 AbstractConfig , 这个配置类中大部分内容为 : 配置项的 key 和 配置项代表的含义 doc ,例如

但是还有一个非常重要的字段: ConfigDef CONFIG , ConfigDef 这个类定义了一份配置的元数据,并且提供了: 继承,分组,存储的能力。分别对应 ConfigDef 的以下三个字段:

配置定义
配置存储
配置存储即通过 ConfigKey 来完成,他定义了配置的元数据,包括 数据类型,key,分组,优先级,校验器。通过一个抽象的 Validator 接口实现添加配置时的校验逻辑

为每个字段设置校验器,各个字段校验器有各自的实现类,这一点可以借鉴下,对于字段的校验 自定义校验器,将校验逻辑集中封装,而不是散落在代码的各个位置

配置继承
配置的继承实现非常简单,直接传递一个配置类,将里面存储的配置和分组拷贝过来

配置分组
一方面通过 ConfigKey 中定义的 group 字段,另外在定义配置项的时候将 key 与 group 的关系存放到 Map 中。

配置操作
看完了配置元数据的定义后,继续回到构造方法 KafkaProducer(ProducerConfig, Serializer<K>, Serializer<V>) ,可以看到需要传递一个 ProducerConfig ,他其实就是Kafka 的配置类,而这个配置类恰巧就对应了 producer.properties 这个配置文件。看到这里是不是发现这与 Spring 中的 JavaConfig 同 Xml 有异曲同工之妙?事实正是如此大多数框架都会有一套配置文件与 Java 类的映射关系,方便默认配置加载,或者配置的动态加载,网络加载等等...
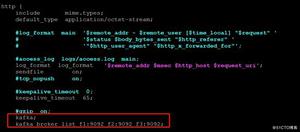
生产者的配置类为 ProducerConfig 消费者为 ConsumerConfig 他们都继承了 AbstractConfig 从下面的图看一看到,Kafka 中所有的配置都是由这个基类来驱动的。

我们需要关注的方法主要为: 构造器、取配置值、其他

构造方法

整体代码相对比较简单,将传入的原始 Map 配置解析到当前类的 values 成员变量中,此时 values 也是一个 Map ,只不过他的 value 不是简单的字符串了而是解析后的对象类型。
这里需要注意的一点在于他的 postProcessParsedConfig() 方法,这个方法在当前类是一个空实现,具体的实现是在子类实现的。在有类的继承关系的时候某些通用的前置后置操作,但是这些操作根据不同的子类需要不同的实现的时候我们经常会这么处理,这种方法也叫做模板方法或者称作 模板设计模式 。

取值方法
这些方法比较简单,但是非常有必要。我经常在很多项目里面看到这样的代码

我相信大家都不陌生,在很多工程中都会见到这样的代码,某个类中定义了一个 Map 或者一个 JSONObject 但是并没有封装对应值的方法,而是在使用到的时候直接 get 一个字符串,然后类型强转。
这样的代码显然是低质量的代码,缺点很明显我们并不知道这个 Map 都会有哪些 key,每次取数据的时候只能使用魔法字符串。另外取出来的值有可能是空,直接强壮很有可能 NPE 。需要做判空操作,强制类型转换,这些非常常用的基础代码会散落在项目的各个文件中。
一般来说我们最好直接定义类,少定义 Map 或者 JSON 。那么万一使用了我们又该如何让他变得 易懂,易维护,易使用呢?
首先针对使用魔法值 get 的问题,我们需要针对这个 Map 定义一个常量,定义 Map 中所有会存储和取出的 Key 每次如果需要往这个 Map 中写入新的 Key 需要修改下这个常量类。
而对于每次根据 key 取数据,并强转的问题我们可以定义一些基础方法,例如 getIntExtVal() getLongExtVal() 等等一系列的方法,将判空和强转一并解决了甚至还可以配置默认值。简化下大概长下面这样,是不是代码瞬间清晰了很多,调用起来也变得方便了。

尾声(唠叨)
过完春节的第一个周末,终于也是写完这篇文章了。只是好久没有锻炼身体了,上周打完羽毛球胳膊简直废了,后面要好好运动!
以上是 读Kafka源码架构简介 的全部内容, 来源链接: utcz.com/a/121845.html