各大公司java面试题分类整理
前言
下面对面试过程中的问题进行分类汇总,这些问题的答案有个人认知、有参考他人的观点,也有一些直接引用别人的文章。本文给出的答案只是一个引子,如果想要深入探究还需要各位通过其他渠道进行详细了解。由于本人知识有限,答案不免有不足或者错误。还望各位犀利指出,小白一定积极改正,进行勘误。
面试题汇总
工作相关篇
Q1: 自己所做过的项目中难点以及如何解决的,介绍系统的业务架构和技术架构
这是一个必问题,所以需要提前准备好项目中的难点以及自己的解决方案。如果是自己遇到并解决的最好,如果自己没有遇到过,那么把项目中其他人解决的难点融会贯通也可。总之:要有亮点,而且自己是深入思考和深入理解的。
Q2: 服务突然RT增大,后续又恢复了,如何定位
- 可能是网络抖动,导致接口短暂超时
- gc影响
Java篇
Java基础
Q1: Java环境变量classpath和path的区别
- path环境变量:系统用来指定可执行文件的完整路径,即使不在path中设置JDK的路径也可执行JAVA文件,但必须把完整的路径写出来
- classpath环境变量:java查找类的路径
Q2: 重写和重载的区别,构造函数可以重写吗
classPerson{String name;
publicPerson(){}
publicPerson(String name){this.name = name;}
publicvoidtalk(){System.out.println("person talk");}
}
classStudentextendsPerson{
String stuNumber;
publicStudent(){}
publicStudent(String name, String stuNumber){
super(name);
this.stuNumber = stuNumber;
}
@Override
publicvoidtalk(){System.out.println("student talk");}
}
复制代码
重写:需要有继承关系,子类重写父类的方法。一般使用@Override注解标识,不标识也无所谓。上面代码中Student类就重写了Person类的talk方法。
重载:函数名相同,参数个数不同或者参数类型不同。注意方法返回值不同是不算重载的。上面代码中对构造函数就是通过参数个数不同进行重载。
构造函数不能被重写,因为重写要求方法名一致。而构造函数的方法名就是类名。子类不可能和父类同名,所以也不可能有相同的构造函数。所以构造函数不能重写,但是可以重载。
Q3: 介绍一些常用的Java工具命令
| 命令 | 说明 |
|---|---|
| jps | 虚拟机进程状态工具,可以列出虚拟机进程 |
| jstat | 虚拟机统计信息监视工具,监视虚拟机各种运行状态信息 |
| jinfo | Java配置信息工具 |
| jmap | 生成堆转储快照 |
集合
Q1: HashMap实现原理
请参考:Java HashMap工作原理及实现
Q2: HashMap为什么线程不安全
请参考:HashMap为什么不是线程安全?
Q3: currentHashMap如何保证线程安全
请参考:高并发编程系列:ConcurrentHashMap的实现原理(JDK1.7和JDK1.8)
Q4: Java容器有哪些?哪些是同步容器,哪些是并发容器?
详细可参考:Java同步容器和并发容器
Java容器有Map、List、Set

Java中同步容器分为2类:
- Vector/Stack/HashTable,其方法都是同步方法,使用
synchronized修饰 - Collections 类中提供的静态工厂方法创建的类(由 Collections.synchronizedXxxx 等方法)
Java中的并发容器:
JDK 的 java.util.concurrent 包(即 juc)中提供了几个非常有用的并发容器。
- CopyOnWriteArrayList - 线程安全的 ArrayList
- CopyOnWriteArraySet - 线程安全的 Set,它内部包含了一个 CopyOnWriteArrayList,因此本质上是由 CopyOnWriteArrayList 实现的。
- ConcurrentSkipListSet - 相当于线程安全的 TreeSet。它是有序的 Set。它由 ConcurrentSkipListMap 实现。
- ConcurrentHashMap - 线程安全的 HashMap。采用分段锁实现高效并发。
- ConcurrentSkipListMap - 线程安全的有序 Map。使用跳表实现高效并发。
- ConcurrentLinkedQueue - 线程安全的无界队列。底层采用单链表。支持 FIFO。
- ConcurrentLinkedDeque - 线程安全的无界双端队列。底层采用双向链表。支持 FIFO 和 FILO。
- ArrayBlockingQueue - 数组实现的阻塞队列。
- LinkedBlockingQueue - 链表实现的阻塞队列。
- LinkedBlockingDeque - 双向链表实现的双端阻塞队列。
线程
Q1: 如何让线程A在线程B执行之后再执行
- CountDownLatch。线程A中
latch.await(),线程B中latch.countDown() - wait()、notify()。可能存在线程B的
notify()先执行,导致线程A一直处于阻塞状态
Q2: ThreadLocal的理解和适用场景
请参考:Java中的ThreadLocal详解
Thread类里面有2个变量,threadLocals和inheritableThreadLocals,类型均为ThreadLocalMap。
为什么Thread类使用map,而不是直接一个value的存储( T value),如果是一个T value的话,这个值就是多个线程共享的,会出现问题。ThreadLocal就是为了解决该问题而来的
使用ThreadLocal注意事项:
ThreadLocalMap中的Entry的key使用的是ThreadLocal对象的弱引用,在没有其他地方对ThreadLoca依赖,ThreadLocalMap中的ThreadLocal对象就会被回收掉,但是对应的value不会被回收,这个时候Map中就可能存在key为null但是value不为null的项,这需要实际的时候使用完毕及时调用remove方法避免内存泄漏。
Q3: 一个线程的生命周期有哪几种状态?它们之间如何流转的
请参考:Java多线程学习(三)---线程的生命周期
Q4: 线程池提交流程

Q5: 线程池中任务队列已满,如何处理
- AbortPolicy:直接抛出RejectedExecutionException异常。是Executors里面默认线程池的默认处理策略
- DiscardPolicy:do nothing
- DiscardOldestPolicy:抛弃最老的任务,执行新的
- CallerRunsPolicy:调用线程执行
Q6: 保证线程安全的方式
- automic:使用提供的原子类
- syntronized:同步代码块
- lock:锁
- volatile:保证可见性
Q7: 2个线程交替打印2个数组的内容
publicclassTest1{publicstaticvoidmain(String[] args){
int[] nums1 = {1, 3, 5, 7, 9};
int[] nums2 = {2, 4, 6, 8, 10};
Object obj = new Object();
Thread t1 = new Thread(() -> {
synchronized (obj) {
for (int n : nums1) {
System.out.print(n + "\t");
try {
obj.notifyAll();
obj.wait();
} catch (Exception e) {
}
}
}
});
Thread t2 = new Thread(() -> {
synchronized (obj) {
for (int n : nums2) {
System.out.print(n + "\t");
try {
obj.notifyAll();
obj.wait();
} catch (Exception e) {
}
}
}
});
t1.start();
t2.start();
}
}
复制代码
锁
Q1: 同步方法的锁是类还是对象
同步方法默认用this或者当前类class对象作为锁;
同步代码块是通过传入的对象作为锁。
Q2: 同步方法A调用同步方法B,能进入嘛
可以,因为synchronized是可重入锁
Q3: synchonized和ReentrantLock的区别
不同点
synchonized是java的关键字;ReentrantLock是类synchonized是非公平锁;ReentrantLock默认是非公平锁,但是有公平锁和非公平锁两种实现方式。synchonized可用在同步代码块、同步方法上;ReentrantLock的使用方式需要lock()和unlock()
相同点
- 两者都是可重入锁
- 都是同步阻塞方式
Q4: 什么是活锁、饥饿、无锁、死锁?怎么检测一个线程是否拥有锁
死锁:
是指两个或两个以上的进程(或线程) 在执行过程中,因 争夺资源而造成的一种互相等待 的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
死锁的条件:
- 互斥: 线程对资源的访问是排他性的,如果一个线程对占用了某资源,那么其他线程必须处于等待状态,直到资源被释放。
- 请求和保持: 线程T1至少已经保持了一个资源R1占用,但又提出对另一个资源R2请求,而此时,资源R2被其他线程T2占用,于是该线程T1也必须等待,但又对自己保持的资源R1不释放。
- 不可剥夺: 线程已获得的资源,在未使用完之前,不能被其他线程剥夺,只能在使用完以后由自己释放。
- 循环等待
活锁
是指线程1可以使用资源,但它很礼貌,让其他线程先使用资源,线程2也可以使用资源,但它很绅士,也让其他线程先使用资源。这样你让我,我让你,最后两个线程都无法使用资源。
举个例子:马路中间有条小桥,只能容纳一辆车经过,桥两头开来两辆车A和B,A比较礼貌,示意B先过,B也比较礼貌,示意A先过,结果两人一直谦让谁也过不去。
饥饿
是指如果线程T1占用了资源R,线程T2又请求封锁R,于是T2等待。T3也请求资源R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求......,T2可能永远等待。
不公平锁能够提高吞吐量但不可避免的会造成某些线程的饥饿,或者优先级低的线程容易产生饥饿
无锁:
无锁,即没有对资源进行锁定,即所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。无锁典型的特点就是一个修改操作在一个循环内进行,线程会不断的尝试修改共享资源,如果没有冲突就修改成功并退出否则就会继续下一次循环尝试。所以,如果有多个线程修改同一个值必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。CAS 原理及应用即是无锁的实现。
检测线程是否有锁
Thread.holdsLock(Object obj):当且仅当 当前线程拥有obj对象锁的时候,返回true。
该方法用例断言打当前线程是否持有锁。assert Thread.holdsLock(obj);
Q5: synchronized实现原理
参考:深入分析Synchronized原理
Q6: java中悲观锁、乐观锁的例子
- Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
- java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的
jvm
Q1: 介绍一些了解的JVM参数
| 参数 | 说明 | 备注 |
|---|---|---|
| -Xms | 最小堆大小 | 一般-Xms和-Xmx大小相等,避免内存的扩展 |
| -Xmx | 最大堆大小 | 一般-Xms和-Xmx大小相等,避免内存的扩展 |
| -Xmn | 年轻代大小 | 其中分了1个Eden和2个Survivor;默认比例 8:1 |
| -XX:SurvivorRatio | eden和survivor的比例 | 默认8:1 |
| -XX:PermSize | 永久代大小 | -XX:PermSize与-XX:MaxPermSize大小最好一致,避免运行时自动扩展 |
| -XX:MaxPermSize | 永久带最大值 | -XX:PermSize与-XX:MaxPermSize大小最好一致 |
| -XX:+UserConcMarkSweepGC | 使用CMS收集器 |
Q2: 为什么 Java 要采用垃圾回收机制,而不采用 C/C++的显式内存管理
在C++中,对象所占的内存在程序结束运行之前一直被占用,在明确释放之前不能分配给其它对象;而在Java中,当没有对象引用指向原先分配给某个对象 的内存时,该内存便成为垃圾。 垃圾回收能自动释放内存空间,减轻编程的负担,JVM的一个系统级线程会自动释放该内存块。释放无用内存,避免内存泄漏
Java禁止显示内存回收,jvm决定回收时机,而且避免开发人员忘记释放内存的问题
Q3: JVM内存模型

Q4: JVM内存分配策略
- 对象优先分配在Eden区,当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC。垃圾收集期间虚拟机对象全部无法放入Survivor空间,通过分配担保机制提前转移到老年代去。
- 大对象直接进入老年代
- 长期存活的对象进入老年代,可以通过-XX:MaxTenuringThreshold设置年龄
- 动态对象年龄判定。为了能更好地适应不同程序的内存状况,HotSpot虚拟机并不是永远要求对象的年龄必须达到-XX:MaxTenuringThreshold才能晋升老年代,如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到-XX:MaxTenuringThreshold中要求的年龄
Q5: 有哪些垃圾回收算法
- 标记-清除:会产生内存碎片
- 标记-复制:年轻代采用该算法进行垃圾收集
- 标记-整理:让所有存活的对象都向内存空间一端移动,延迟增大
类加载
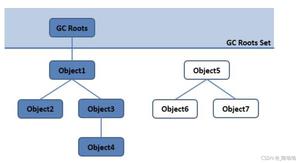
关于类加载器看这一篇文章就够了。深入理解Java类加载机制。但是这篇文章最后有一个错误:下面图片中此时的counter2=1应该是counter2=0

Q1: classLoader和Class.forName()的区别
java中class.forName()和classLoader都可用来对类进行加载。
class.forName()前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象
MySQL篇
Q1: MySQL存在哪些索引类型
- 唯一索引
- 全文索引
- 联合索引
- 普通索引
Q2: InnoDB为什么采用B+树的索引结构
请参考腾讯技术工程的文章:深入理解 Mysql 索引底层原理。
Q3: 介绍聚簇索引、非聚簇索引、索引覆盖
请参考文章:mysql聚簇索引和非聚簇索引
Q4: 如何提高SQL性能,工作中SQL优化经验
提高SQL的性能我认为一定要让MySQL选择正确的索引。
在工作中,小白曾优化过系统中的SQL。其体现主要表现在以下几个方面(这只是小白在工作中遇到的,跟各位遇到的应该会有不同哦):
- MySQL错误选择索引
- 字段类型错误导致没走索引
- 本可使用索引覆盖的SQL语句,却回表查了多余数据
Q5: MySQL数据库隔离级别
请参考:Mysql数据库隔离级别
Spring篇
Q1: 介绍Spring IOC和AOP
请参考:深入理解Spring两大特性:IoC和AOP
IOC:控制反转。IOC之前对象A依赖对象B时,需要A主动去通过new创建B的实例,控制权是在对象A上。IOC就是将对象的控制权交给IOC容器处理。
AOP:面向切面编程(AOP)就是纵向的编程。比如业务A和业务B现在需要一个相同的操作,传统方法我们可能需要在A、B中都加入相关操作代码,而应用AOP就可以只写一遍代码,A、B共用这段代码。并且,当A、B需要增加新的操作时,可以在不改动原代码的情况下,灵活添加新的业务逻辑实现。AOP主要一般应用于签名验签、参数校验、日志记录、事务控制、权限控制、性能统计、异常处理等
Q2: AOP如何实现
Spring通过动态代理实现AOP。
请参考:从代理机制到Spring AOP
Q3: Spring如何实现事务管理
请参考:可能是最漂亮的Spring事务管理详解
Q4: Spring事务传播机制
请参考:Spring事务传播行为详解
Q5: Spring Bean生命周期
请参考: 请别再问Spring Bean的生命周期了!
Redis篇
Q1: redis如何实现分布式锁
使用setnx key value实现,并使用expire key 设置超时时间。
这种方式存在的问题:这2步操作由于不是一个事务,所以可能出现设置超时时间失败的问题。如果超时时间设置失败则会导致该key永不过期,占用内存。
解决方式:
- 可使用lua脚本自己编写,使之变成一个原子性操作
- redis提供了
SET key value [EX seconds] [PX milliseconds] [NX|XX]
Q2: redis有支持几种数据结构
String、List、Set、Zset、Map、GEO、Bitmap
Q3: 字符串数据结构底层实现
Redis的字符串底层由SDS简单动态字符串实现。
特性
- 空间预分配:当修改字符串并需要空间扩展时,分为以下2种情况:
- 扩展之后空间小于1M,则预分配与已使用空间一样大小的空间(已使用空间包含扩展之后的字符串)
- 扩展之后空间大于1M,则直接分配1M
- 惰性释放:为了避免释放之后再扩展的问题,redis采用了惰性释放策略,使用
free字段来记录未使用的长度,等待使用。同时也提供了相关的API再有需要时释放空间。
Q4: Map数据结构底层实现
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对。
字典数据结构中是一个哈希表数组,共有2个哈希表。在扩容时使用。
Redis的hash算法使用MurmurHash2算法。
Q5: Redis过期键删除策略
定时删除: 在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来临时,立即执行对键的删除操作。
优点: 内存友好,可以实时释放内存
缺点: 对CPU不友好,为了删除过期键,大量占用CPU
惰性删除: 放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键
优点: 对CPU友好,只有使用到的时候才判断
缺点: 对内存不友好
实现: 通过expireIfNeeded函数,读写redis命令之前都会调用该函数,判断是否需要过期该键
定期删除: 每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定
优点: 兼顾内存和CPU
实现: Redis的服务器周期性操作redis.c/serverCron函数执行时,activeExpireCycle函数就会被调用。函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
Q6: redis的淘汰策略
- noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)
- allkeys-lru:从所有key中使用LRU算法进行淘汰
- volatile-lru:从设置了过期时间的key中使用LRU算法进行淘汰
- allkeys-random:从所有key中随机淘汰数据
- volatile-random:从设置了过期时间的key中随机淘汰
- volatile-ttl:在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰
Q7: zset的底层实现
跳跃表。可参考通俗易懂的Redis数据结构基础教程
Kafka篇
Q1: Kafka如何保证高性能和可靠性
请参考:Kafka 数据可靠性深度解读。
画外音:该文章需要细细阅读,理解每一块内容。只要明白了该文章里所说内容,应对面试中的Kafka面试题应该不成问题。
Q2: Kafka支持事务嘛
请参考:Kafka 设计解析(八):Kafka 事务机制与 Exactly Once 语义实现原理
Q3: Kafka中zookeeper的作用
- 再平衡消费者
- 选主
编程题
基本都是Leetcode的中等难度的题目,各位小伙伴可以刷起来了
Q1: 求A/B,不能使用除法
详细讲解请看:两数相除
publicintdivide(int dividend, int divisor){if (dividend == 0) {
return0;
}
if (dividend == Integer.MIN_VALUE && divisor == -1) {
return Integer.MAX_VALUE;
}
int flag = -1;
if ((dividend > 0 && divisor > 0) || (dividend < 0 && divisor < 0)) {
flag = 1;
}
long a = Math.abs((long) dividend);
long b = Math.abs((long) divisor);
return flag * getRes(a, b);
}
privateintgetRes(long a, long b){
if (a < b) {
return0;
}
int count = 1;
long tmp = b;
while (a > b << 1) {
b = b << 1;
count = count << 1;
}
return count + getRes(a - b, tmp);
}
复制代码
Q2: 给定包含n个数字的数组,将这些数字进行拼接,求拼接成的最大数值
Q3: 链表中找到倒数第K个节点
Q4: 买卖股票的最佳时机
为了找到最大利润,我们需要找到最小的买入价格。假设nums[i]是最低的买入价格,nums[j]是最高的买入价格。当满足i < j时的最大利润即为nums[j] - nums[i]。
详细描述请参考:121. 买卖股票的最佳时机
publicintmaxProfit(int[] prices){int len = prices.length;
if (len <= 1) {
return0;
}
// 存储最小的买入价格
int minBuyPrice = prices[0];
// 存储最高的卖出价格
int maxSellPrice = 0;
for (int i = 1; i < len; i++) {
// 计算最高的卖出价格:当前最高卖出价格与当天的卖出价格对比。其中price[i]-minBuyPrice就是当天的卖出价格
maxSellPrice = Math.max(maxSellPrice, prices[i] - minBuyPrice);
// 更新最小的买入价格
minBuyPrice = Math.min(minBuyPrice, prices[i]);
}
return maxSellPrice;
}
复制代码
Q5: 复制带随机指针的链表
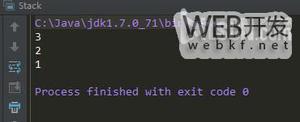
Q6: 消除816。例如原字符串12881616,最终返回12。12881616 -> 12816 -> 12
提示:使用栈数据结构
Q7: 数组中奇数、偶数数量相同,交换内容最终使得奇数下标存储奇数,偶数下标存储偶数
Q8: leetcode 154题
链接:154. 寻找旋转排序数组中的最小值II
解题思路,欢迎查阅小白的个人博客:154. 寻找旋转排序数组中的最小值II
Q9: 单链表结构,每个节点表示0-9的数字。给定2个链表,进行求和。例如 9->9和2->1。求和结果是1->2->2
三种思路,请参考:Leetcode 445. 两数相加 II
Q10:实现一个LRU数据结构,插入和查询要求时间复杂度
- 可以使用LinkedHashMap直接实现。
- 使用一个
LinkedList存储key的顺序吗,到达O(1)的插入,使用map存储k-v映射关系,达到O(1)的查询复杂度
publicclassMain{// 使用map存储结构中已有的key,便于O(1)的查询复杂度
HashMap<String, Integer> map = new HashMap<>();
// 存储key的顺序,对于最近访问的key,移动到队列的头部
LinkedList<String> lruKeys = new LinkedList<>();
// LRU结构的大小
int size = 4;
publicstaticvoidmain(String[] args){
Main main = new Main();
main.set("math", 100);
main.set("chiness", 200);
main.set("english", 210);
main.print();
System.out.println("-------");
main.set("music", 250);
main.set("draw", 250);
main.print();
System.out.println("-------");
main.get("english");
main.print();
}
privatevoidprint(){
for (String key : lruKeys) {
System.out.println(key + " = " + map.get(key));
}
}
privatevoidset(String key, int val){
if (map.containsKey(key)) {
map.put(key, val);
moveToFirst(key);
} else {
if (lruKeys.size() == size) {
String removeKey = lruKeys.removeLast();
map.remove(removeKey);
}
map.put(key, val);
lruKeys.addFirst(key);
}
}
privateintget(String key){
if (map.containsKey(key)) {
moveToFirst(key);
return map.get(key);
}
return0;
}
privatevoidmoveToFirst(String key){
lruKeys.remove(key);
lruKeys.addFirst(key);
}
}
复制代码
Q11:最长回文子串
Leetcode 5:最长回文子串
思维题
Q1: 36辆车,6个跑道,最少多少次可以筛选出跑的最快的3辆车(不可用表计时)
8次 = 6 + 1 + 1。
分析:
- 首先将36辆车随机分成6组进行比赛,对每组进行排名并选择出每组的第一名(6次)
- 将步骤1结果的6辆车再进行一轮比赛,并选择出前三名,假设分别为A车、B车、C车(1次)
- 然后从A车所在的组(步骤1的分组)选出第2、3名,从B车所在的组(步骤1的分组)选出第2名。(因为A车第一,所以存在A车所在组的第2、3名比B、C车块的可能性;同理B车所在组的第2名存在比C车块的可能性;由于只选最快的3辆车,所以无需从C车所在组进行选车)
- 然后将步骤3选择出来的3辆车再加上A车、B车、C车进行一次比赛,选择出前三名(1次)
- 步骤4的结果就是最快的3辆车
Q2: 1000w个数据中找出重复的
使用bitmap。不要使用布隆过滤器,因为布隆过滤器并非100%准确。
Q3: 有2个玻璃球和一栋256层的高楼,如何快速定位到使得玻璃球摔碎的最低楼层
方案一:拿玻璃球一层层由低到高测试。
方案二:二分法。但是如果在中间的时候玻璃球碎了,那就无法再二分了,只能一层层的实验。
方案三:拿玻璃球测试楼层为n,2n,3n....这种。如果玻璃球在2n层摔坏了,则那另一个玻璃球从n+1 到 2n-1的楼层逐层实验。
其实可以看出来方案三中n=1时,就是方案一逐层实验;当n=128时,就是方案二。那我们如何求出n来使得结果最优呢?
假设使得玻璃球碎的楼层是256,步长n。则此时的次数为:256/n+n。要想该数值最小,则需要256/n = n。所以n = 16。
Q4: 有100只狼和1只羊,狼可以吃草,但他们更愿意吃羊。
假设:
A:每次只有一只狼可以吃样,而且一旦他吃了羊,他自己就变成羊。
B:所有的狼都不想被吃掉。
问最后这只羊会不会被吃掉?
使用数学归纳法。
- 当有1只狼,1只羊的时候,该羊一定被吃。(因为狼变成羊之后,不会被吃)
- 当有2只狼,1只羊的时候,该羊一定不被吃。(因为如果某狼吃了该羊之后,就会变成1狼1羊的情况,一定被吃)
- 当有3只狼,1只羊的时候,该羊一定被吃。(因为如果某狼吃了该羊之后,就会变成2狼1羊的情况,安全)
综上,当奇数狼时,羊会被吃;偶数狼时,羊不会被吃。
面试心得
面试前
- 准备简历,并保证简历中没有错别字。
- 简历中技能栏和项目栏中的项目一定要熟练。对于某技术熟悉就是熟悉、了解就是了解,要实事求是。否则被面试官问住是一件很尴尬的事情
- 准备1~2分钟的自我介绍
- 先拿几家不想去公司试试手,因为一开始面试被pass的几率很大
- 临近面试时,提前准备几个给面试官的问题,面试之后进行沟通。
面试中
- 不要紧张,遇到问题会就是会,不会就是不会。即使不会也可以说一下自己的思考和理解。
- 针对编程题,需要充分考虑边界问题和异常情况
面试后
- 对刚才的面试进行复盘。针对不会的问题或者答得不好的问题,进行总结并收集相关知识点。
以上是 各大公司java面试题分类整理 的全部内容, 来源链接: utcz.com/a/115875.html