
【Java】Java HashMap总结
Java HashMap总结
东瓜发布于 2 月 10 日
HashMap的hash函数实现原理
1、JDK 1.8 中,通过key的hashCode()方法得到值的高16位异或低16 位实现的:
(h = k.hashCode()) ^ (h >>> 16)2、使用计算得到的hash值与数组长度n-1做与位运算得到数组下标:
if ((p = tab[i = (n - 1) & hash]) == null)为什么使用异或运算?
这段代码叫“扰动函数”,目的是为了混合原hash码的高位和地位,混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相的保留下来
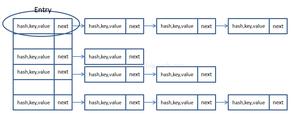
- 计算得到hash值后需要与数组长度-1做与位运算得到元素所在数组下标位置,此时数组长度-1相当于一个“低位掩码”,结果是hash值的高位全部归零,只保留低位值
- hashCode函数返回的int值范围为32位,右移16位再异或,相当于自己的高半区和低半区做异或,这样得到的hash值混合了原始hash码高位和低位的特征,减少了hash碰撞的几率
为什么用异或,不用与和或运算?
图片转自:https://zhuanlan.zhihu.com/p/...
java
阅读 35发布于 2 月 10 日
本作品系原创,采用《署名-非商业性使用-禁止演绎 4.0 国际》许可协议
东瓜
12 声望
0 粉丝
东瓜
12 声望
0 粉丝
宣传栏
目录
HashMap的hash函数实现原理
1、JDK 1.8 中,通过key的hashCode()方法得到值的高16位异或低16 位实现的:
(h = k.hashCode()) ^ (h >>> 16)2、使用计算得到的hash值与数组长度n-1做与位运算得到数组下标:
if ((p = tab[i = (n - 1) & hash]) == null)为什么使用异或运算?
这段代码叫“扰动函数”,目的是为了混合原hash码的高位和地位,混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相的保留下来
- 计算得到hash值后需要与数组长度-1做与位运算得到元素所在数组下标位置,此时数组长度-1相当于一个“低位掩码”,结果是hash值的高位全部归零,只保留低位值
- hashCode函数返回的int值范围为32位,右移16位再异或,相当于自己的高半区和低半区做异或,这样得到的hash值混合了原始hash码高位和低位的特征,减少了hash碰撞的几率
为什么用异或,不用与和或运算?
图片转自:https://zhuanlan.zhihu.com/p/...
以上是 【Java】Java HashMap总结 的全部内容, 来源链接: utcz.com/a/114613.html




得票时间