
【Java】【1w字+干货】第一篇,基础:让你的 Redis 不再只是安装吃灰到卸载(Linux环境)
【1w字+干货】第一篇,基础:让你的 Redis 不再只是安装吃灰到卸载(Linux环境)
BWH_Steven发布于 今天 02:00
")
Redis 基础以及进阶的两篇已经全部更新好了,为了字数限制以及阅读方便,分成两篇发布。
本篇主要内容为:NoSQL 引入 Redis ,以及在 Linux7 环境下的安装,配置,以及总结了非常详细的类型,用法以及例子,最后通过 Jedis 以及 Springboot 中的 RedisTemplate 在 IDEA 中远程操作
Redis。
第二篇会主要涉及到配置文件,发布订阅,主从复制,哨兵等一些进阶用法的一个基本使用。
一 简述 NoSQL
可以简单的说,Redis就是一款高性能的NoSQL数据库
(一) 什么是NoSQL?
我们前面所学习的MySQL数据库是典型的的SQL数据库也就是传统的关系型数据库,而我们今天学习的Redis数据库则是一款NoSQL数据库,也叫作非关系型数据库,它与我们熟悉的MySQL等的概念完全是不一样的,它是一项全新的数据库理念,我们帖一组百度百科的解释
说明:我们现在所看到的的博客,RSS,P2P,微博,抖音等均属于 Web2.0的产物,Web2.0相比较过去的Web1.0更加注重于用户的交互,用户不仅可以浏览,还可以上传一些资源到网站上,例如图片文字或者说短视频等,使得用户也参与到了网站内容的制造中去了
(二) 为什么使用NoSQL?
- 部署成本低:部署操作简单,以开源软件为主
- 存储格式丰富:支持 key-value形式、文档、图片等众多形式,包括对象或者集合等格式
- 速度快:数据存储在缓存中,而不是硬盘中,而且例如Redis基于键值对,同时不需要经过SQL层解析,性能非常高
无耦合性,易扩展
- 在SQL中,一个正在使用的数据是不允许删除的,但NoSQL却可以操作
(三) NoSQL可以替代SQL吗?
有人会说,NoSQL = Not SQL ,但是我更倾向这样理解 NoSQL = Not only SQL ,我们不能以一个绝对的结论来判定两项技术的好坏,每一项技术的产生都有其特定的原因,在我看来,NoSQL更适合作为SQL数据库的补充,由于海量数据的出现,性能的要求高了起来,而NoSQL这种产物,对于结构简单但是数据量大的数据处理起来要比传统的SQL快很多,但是同样的,其逻辑运算就必须很简单,否则它也是力不从心的
在我看来,可以简单的说,NoSQL就是以功能换取性能,但是需要处理复杂的业务逻辑还需要使用关系型数据库,所以说想要在模型中完全用NoSQL替代SQL是不现实的,两者更像是互补的关系
SQL的好处:
- 支持在一个表以及多表之前进行复杂的查询操作
- 支持对事物的处理,能保证数据的安全要求
- 学习成本低,资料较多
市面上的NoSQL产品非常多,我们今天所要介绍的就是其中一款基于键值存储的数据库——Redis
(四)NoSQL数据库的四大分类表格分析
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
二 初识Redis
(一) 什么是 Redis
我们在一开始提到了,Redis就是一款高性能的NoSQL数据库,那么它的应用场景是什么呢?
- 用于用户内容缓存,可以处理大量数据的高访问负载,例如:数据查询,新闻,商品内容
- 任务队列,例如:秒杀,12306
- 在线好友列表
- 应用、网站访问统计排行
由于其基于键值存储,那么可以支持的存储的类型有什么呢?
- 字符串类型 - String
- 列表 - list:linkedlist
- 集合 - set
- 有序集合 - sortedset
- 哈希 - hash:map
(二)下载安装
说明:
推荐使用 Linux 进行部署,所以我们后面也会详细介绍 Linux 中的安装配置方式,但是如果只是想快速学习语法,也可以勉强使用 Windows 版本,安装会简单很多。
(1) linux 推荐
官网:https://redis.io(推荐)
- 访问可能较慢
中文网:http://www.redis.net.cn
- 版本有一些滞后,例如官网已经 6.0.9 了,中文网首页仍挂着 5.0.4
A:下载
# 下载 redis-6.0.9 压缩包wget http://download.redis.io/releases/redis-6.0.9.tar.gz
补充:
- 可以通过 http://download.redis.io/rele... 查看选择需要的版本
- 此方式下载后的压缩文件位于
/home目录下
B:解压
一般来说,我们程序都会放在 /opt 目录下,所以我们先将这个压缩文件移动过去再解压
# 移动此文件到根目录下的 opt 目录中mv redis-6.0.9.tar.gz /opt
# 解压此文件
tar -zxvf redis-6.0.9.tar.gz
解压后 opt 目录下就多出一个 redis-6.0.9 的文件夹,我们打开它,就可以看到一些文件在其中,其中 redis.conf 是我们一会要用的配置文件,暂时先不理会
")
解压后的文件貌似也不能运行啊,这是当然的,因为这些文件还没有经过编译和安装,在编译之前,首先要检查一下 GCC 的版本
C:检查 GCC 版本(Redis 6 以下可以忽略)
如果你选择的是 Redis 6 以上的版本,例如这里选择的 6.0.9,你的 gcc 版本如果太低就会导致后面编译出错,最起码你的 gcc 要到 5.3 的版本以上
如果没有 gcc 先进行安装
yum -y install gccyum -y install gcc-c++
安装完成后,通过 gcc -v 查看到安装到的版本是 4.x.x 版本的,所以要升级,旧版本的 Redis 可以不去做升级这一步
依次执行下面每一条命令
# 升级到gcc 9.3yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
# scl命令启用只是临时的,退出shell或重启就会恢复原系统gcc版本
scl enable devtoolset-9 bash
# 长期使用 gcc 9.3 还需要进行如下操作
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
source /etc/profile
查看一下更新后的版本
")
D:编译安装
依次执行编译和安装,
# 编译make
# 安装
make install
make 会慢一下,耐心等待一下,如果出了错误,一般都是 gcc 的问题
")
安装后的内容一般都在 /usr/local/bin 下
E:拷贝配置文件
我们把原来的配置文件就放在那个解压文件中,我们自己用的,单独复制一份出来,方便我们操作和更改
我们先去 /usr/local/bin 中创建一个新的文件夹,然后把之前解压后的文件夹中的 redis.conf 拷贝过来
# 跳转到指定目录下cd /usr/local/bin
# 新建一个文件夹
mkdir myconfig
# 复制 /opt/redis-6.0.9/redis.conf 到 当前目录的 myconfig 文件夹下
cp /opt/redis-6.0.9/redis.conf myconfig
看一下过程
")
F:开启后台运行
为了保证我们的redis可以后台运行,我们去编辑拷贝过来的 redis.conf 配置文件
vim redis.conf在其中找到 daemonize no
将 no 修改为 yes,保存退出
")
G:运行 Redis
下面先运行一下其服务端(保证当前在 usr/local/bin 目录下)
# 运行服务端redis-server myconfig/redis.conf
- 加 myconfig/redis.conf 就是为了制定其启动使用的配置文件
接着运行其客户端
# 运行客户端redis-cli -p 6379
- 因为本身就是本机,所以只需要指定端口就行了,不需要指定ip
可以简单测试一下,例如 set get 一下,能拿到值就代表成功了
")
H:关闭服务以及检查进程是否存在
先看一下运行中时,进程的存在情况
# 查看redis 进程ps -ef|grep redis
")
在客户端中,可以通过 shutdown 和 exit 执行关闭(这个是在Redis客户端中执行)
# 关闭127.0.0.1:6379> shutdown
not connected> exit
# 再次查看一下进程状况
[[email protected] bin]# ps -ef|grep redis
")
(2) windows 不推荐
我们可以去github中寻找windows版本,不过版本会有所滞后,官方起码是没有支持更新的,可能微软还想着能拽他一把。最新的版本好像也都是好几年前的了
https://github.com/microsofta...
解压即可用:分别启动 redis-server.exe 和 redis-cli.exe 就能直接测试使用了吗,有问题修改redis.windows.conf 配置文件
- redis-server.exe:redis服务器端
- redis-cli.exe:redis的客户端
- redis.windows.conf:配置文件
三 Redis 通用命令
(一) 开闭命令
(1) 启动 Redis 服务
redis-server [--port 6379]有时候参数会过多,建议使用配置文件启动
redis-server [xx/redis.conf]例如:redis-server myconfig/redis.conf
(2) 客户端连接 Redis
redis-cli [-h 127.0.0.1 -p 6379]例如 :redis-cli -p 6379
(3) 停止 Redis
在客户端中(标志有 127.0.0.1:6379>)直接输入 shutown 等即可
# 关闭127.0.0.1:6379> shutdown
not connected> exit
若在目录中(前面为 $ 等),可以执行
redis-cli shutdownkill redis-pid
(4) 测试连通性
返回 PONG 即连通了
127.0.0.1:6379> pingPONG
(二) key 以及通用操作
注:每一种类型的存储方式是不太一样的,所以这里的操作不会讲到添加存储,下面会在每种类型中详细讲解。
只是想简单先测试,可以先暂时用这几个命令(这是 String 类型的)
可以使用
set key value添加- set 为命令,key 为键,value 为值
- 例如:
set test ideal-20
get key获取到值
(1) 获取所有键
- 语法:keys pattern
127.0.0.1:6379> keys *1) "test"
2) "test2"
*作为通配符,表示任意字符,因为其会遍历所有键,然后显示所有键列表,时间复杂度O(n),数据量过大的环境,谨慎使用
(2) 获取键总数
- 语法:dbsize
127.0.0.1:6379> dbsize(integer) 2
- 内部变量存储此值,执行获取操作时,非遍历,因此时间复杂度O(1)
(3) 判断当前 key 是否存在
- 语法:exists key [key ...]
127.0.0.1:6379> exists test(integer) 1
- 最后返回的是存在的个数
(4) 查询键类型
- 语法: type key
127.0.0.1:6379> type teststring
(5) 移动键
- 语法:move key db
127.0.0.1:6379> move test2 3(string) 1
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> keys *
1) "ideal-20-2"
- 注:Redis 默认有 16 个数据库 move 代表移动到其中哪个去,然后 select 代表切换到这个数据库
(6) 删除键
- 语法:del key [key ...]
127.0.0.1:6379> del test2(integer) 1
(7) 设置过期时间
- 秒语法:expire key seconds
- 毫秒语法:pexpire key milliseconds
127.0.0.1:6379> expire test 120(integer) 1
(8) 查询key的生命周期(秒)
- 秒语法:ttl key
- 毫秒语法:pttl key
127.0.0.1:6379> ttl test(integer) 116
(9) 设置永不过期
- 语法:persist key
127.0.0.1:6379> persist test(integer) 1
127.0.0.1:6379> ttl test
(integer) -1
(10) 更改键的名称
- 语法:rename key newkey
127.0.0.1:6379> rename test idealOK
127.0.0.1:6379> keys *
1) "ideal"
(11) 清除当前数据库
- 语法:flushdb
127.0.0.1:6379> flushdbOK
127.0.0.1:6379> keys *
(empty array)
(12) 清除全部数据库的内容
- 语法:flushall
127.0.0.1:6379> flushallOK
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379>
四 常见支持类型操作
(一) 字符串类型 - string
(1) 存储
语法:set key value [EX seconds] [PX milliseconds] [NX|XX]
- 后面还可以选择性的跟随过期时间
127.0.0.1:6379> set address beijing 5000OK
(2) 获取
- 语法:get key
127.0.0.1:6379> get address“beijing”
(3) 删除
- 语法:del key
127.0.0.1:6379> del address(string) 1
(4) 递增或递减
如果字符串中的值为数字类型,可以进行递增递减,其它类型会报错
- 递增语法:incr key
- 递增语法(指定步长):incrby key step
- 递减语法:decr key
- 递减语法(指定步长):decrby key step
127.0.0.1:6379> set age 21OK
127.0.0.1:6379> incr age # 递增
(integer) 22
127.0.0.1:6379> incrby age 5 # 递增 5
(integer) 27
127.0.0.1:6379> decr age # 递减
(integer) 26
127.0.0.1:6379> decrby age 5 # 递减 5
(integer) 21
(5) 追加内容
- 语法:append key value
127.0.0.1:6379> set ideal helloOK
127.0.0.1:6379> append ideal ,ideal-20 # 追加内容
(integer) 14
127.0.0.1:6379> get ideal
"hello,ideal-20"
(6) 截取部分字符串
- 语法:getrange key start end
127.0.0.1:6379> get ideal"hello,ideal-20"
127.0.0.1:6379> getrange ideal 0 3
"hell"
127.0.0.1:6379> getrange ideal 0 -1
"hello,ideal-20"
(7) 替换部分字符串
- 语法:setrange key start
127.0.0.1:6379> get ideal"hello,ideal-20"
127.0.0.1:6379> setrange ideal 6 bwh # 从下标为6的位置开始替换
(integer) 14
127.0.0.1:6379> get ideal
"hello,bwhal-20"
(8) 获取值的长度
- 语法:strlen key
127.0.0.1:6379> strlen addr1(integer) 7
(9) 不存在的时候才设置
语法:setnx key value
- 不存在,则创建
- 存在,则失败
127.0.0.1:6379> setnx address guangdong # address键 不存在,则创建(integer) 1
127.0.0.1:6379> get address
"guangdong"
127.0.0.1:6379> setnx address beijing # address键 存在,则失败
(integer) 0
127.0.0.1:6379> get address
"guangdong"
(10) 同时存储获取多个值
- 同时存储多个值:mset key1 value1 key2 value2 ...
- 同时获取多个值:mget key1 key2
同时存储多个值(保证不存在):msetnx key1 value1 key2 value2 ...
- 此操作为原子性操作,要失败全部失败
127.0.0.1:6379> mset addr1 beijing addr2 guangdong addr3 shanghai # 同时存储多个值OK
127.0.0.1:6379> keys *
1) "addr3"
2) "addr2"
3) "addr1"
127.0.0.1:6379> mget addr1 addr2 addr3 # 同时获取多个值
1) "beijing"
2) "guangdong"
3) "shanghai"
127.0.0.1:6379> msetnx age1 20 age2 25 age3 30 # 第一次同时存储多个值(保证不存在)
(integer) 1
127.0.0.1:6379> msetnx age4 35 age5 40 age1 45 # 第二次同时存储多个值(保证不存在),失败了
(integer) 0
127.0.0.1:6379>
(11) 设置对象
- 语法:key value (key 例如:user:1 ,value为一个json字符串)
127.0.0.1:6379> set user:1 {name:zhangsan,age:20} # 存一个对象OK
127.0.0.1:6379> keys *
1) "user:1"
127.0.0.1:6379> get user:1
"{name:zhangsan,age:20}"
- 以上这种 user:1 的设计在 Redis 中是允许的,例子如下
- 语法:对象名:{id}:{filed}
127.0.0.1:6379> mset user:1:name lisi user:1:age 25OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "lisi"
2) "25"
(12) 先 get 后 set
语法:getset
- 先取到原来的值,然后再把新值覆盖,如果原先没有值返回 nil
127.0.0.1:6379> getset addr beijing # 原先没有值,返回 nil(nil)
127.0.0.1:6379> get addr
"beijing"
127.0.0.1:6379> getset addr guangdong # 原先有值,返回原先的值,然后覆盖新值
"beijing"
127.0.0.1:6379> get addr
"guangdong"
(二) 列表类型 - list
(1) 添加
A:从左或从右添加元素
- lpush key value:将元素添加到列表左边
- Rpush key value:将元素添加到列表右边
下面演示添加到左边的,右边的是一样的就不演示了
127.0.0.1:6379> lpush list1 A(integer) 1
127.0.0.1:6379> lpush list1 B
(integer) 2
127.0.0.1:6379> lpush list1 C
(integer) 3
127.0.0.1:6379> lrange list1 0 -1
1) "C"
2) "B"
3) "A"
B:插入新值到某个值前后
- 语法:linsert list before/after value newvalue
127.0.0.1:6379> lrange list1 0 -11) "A"
2) "B"
3) "C"
127.0.0.1:6379> linsert list1 before C XXX # 在 C 前插入 XXX
(integer) 4
127.0.0.1:6379> lrange list1 0 -1
1) "A"
2) "B"
3) "XXX"
4) "C"
(2) 获取:
A:根据区间获取值
- 语法:lrange key start end
127.0.0.1:6379> lrange list1 0 -1 # 获取所有值1) "C"
2) "B"
3) "A"
127.0.0.1:6379> lrange list1 0 1 # 获取指定区间的值
1) "C"
2) "B"
B:根据下标获取值
- 语法:lindex list 下标
127.0.0.1:6379> lrange list1 0 -11) "C"
2) "B
127.0.0.1:6379> lindex list1 0
"C"
127.0.0.1:6379> lindex list1 1
"B"
C:获取列表的长度
- 语法 llen list
127.0.0.1:6379> llen list1(integer) 1
(3) 删除
A:移除最左或最右的元素
- lpop key:删除列表最左边的元素,且返回元素
- rpop key:删除列表最右边的元素,且返回元素
127.0.0.1:6379> lrange list1 0 -11) "D"
2) "C"
3) "B"
4) "A"
127.0.0.1:6379> lpop list1 # 删除列表最左边的元素,且返回元素
"D"
127.0.0.1:6379> rpop list1 # 删除列表最右边的元素,且返回元素
"A"
127.0.0.1:6379> lrange list1 0 -1
1) "C"
2) "B"
B:移除指定的值
- 语法:lrem list num value
127.0.0.1:6379> lrange list1 0 -11) "C"
2) "C"
3) "B"
4) "A"
127.0.0.1:6379> lrem list1 1 A # 删除1个A
(integer) 1
127.0.0.1:6379> lrange list1 0 -1
1) "C"
2) "C"
3) "B"
127.0.0.1:6379> lrem list1 2 C # 删除2个C
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "B"
127.0.0.1:6379>
C:移除最后一个元素且添加到另一个list
- rpoplpush list1 list2
127.0.0.1:6379> lrange list1 0 -11) "A"
2) "B"
3) "C"
127.0.0.1:6379> rpoplpush list1 list2 # 移除 list1 中最后一个元素,且添加到list2 中去
"C"
127.0.0.1:6379> lrange list1 0 -1
1) "A"
2) "B"
127.0.0.1:6379> lrange list2 0 -1
1) "C"
(4) 根据下标范围截取 list
- 语法:ltrim list start end
127.0.0.1:6379> rpush list1 A(integer) 1
127.0.0.1:6379> rpush list1 B
(integer) 2
127.0.0.1:6379> rpush list1 C
(integer) 3
127.0.0.1:6379> rpush list1 D
(integer) 4
127.0.0.1:6379> ltrim list1 1 2 # 截取下标为1到2的值
OK
127.0.0.1:6379> lrange list1 0 -1
1) "B"
2) "C"
(5) 替换指定下标的值
语法:lset list 下标 value
127.0.0.1:6379> exists list1 # 判断是否存在此list(integer) 0
127.0.0.1:6379> lset list1 0 beijing # 不存在,替换报错
(error) ERR no such key
127.0.0.1:6379> lpush list1 guangdong # 创建一个list
(integer) 1
127.0.0.1:6379> lindex list1 0
"guangdong"
127.0.0.1:6379> lset list1 0 beijing # 存在,替换成功
OK
127.0.0.1:6379> lindex list1 0
"beijing"
(三) 集合类型 - set
set:一种无序(不保证有序)集合,且元素不能重复
(1) 添加
- 语法:sadd key value
127.0.0.1:6379> sadd set1 A(integer) 1
127.0.0.1:6379> sadd set1 B
(integer) 1
127.0.0.1:6379> sadd set1 C
(integer) 1
127.0.0.1:6379> sadd set1 C # set的值不能重复
(integer) 0
127.0.0.1:6379> smembers set1 # 查询指定set的所有值,乱序
1) "B"
2) "A"
3) "C"
(2) 获取
A:获取set集合中的所有元素
- 语法:smembers key
127.0.0.1:6379> smesmbers set1 # 查询指定set的所有值,乱序1) "B"
2) "A"
3) "C"
B:获取元素的个数
- 语法:scard set
127.0.0.1:6379> scard set1(integer) 3
C:随机获取元素
语法:sembers set [num]
- 默认获取一个随机元素,后跟数字,代表随机获取几个元素
127.0.0.1:6379> smembers set11) "D"
2) "B"
3) "A"
4) "C"
127.0.0.1:6379> srandmember set1 # 获取一个随机元素
"D"
127.0.0.1:6379> srandmember set1 # 获取一个随机元素
"B"
127.0.0.1:6379> srandmember set1 2 # 获取两个随机元素
1) "A"
2) "D"
(3) 删除
A:删除set集合中某元素
- 语法:srem key value
127.0.0.1:6379> srem set1 C # 删除 C 这个元素(integer) 1
127.0.0.1:6379> smembers set1
1) "B"
2) "A"
B:随机删除一个元素
- 语法:spop set
127.0.0.1:6379> smembers set11) "D"
2) "B"
3) "A"
4) "C"
127.0.0.1:6379> spop set1 # 随机删除一个元素
"A"
127.0.0.1:6379> spop set1 # 随机删除一个元素
"B"
127.0.0.1:6379> smembers set1
1) "D"
2) "C"
(4) 移动指定值到另一个set
- 语法:smove set1 set2 value
127.0.0.1:6379> smembers set11) "D"
2) "C"
127.0.0.1:6379> smove set1 set2 D # 从 set1 移动 D 到 set2
(integer) 1
127.0.0.1:6379> smembers set1
1) "C"
127.0.0.1:6379> smembers set2
1) "D"
(5) 交集 并集 差集
- sinter set1 set2:交集
- sunion set1 set2:并集
- sdiff set1 set2:差集
127.0.0.1:6379> sadd set1 A(integer) 1
127.0.0.1:6379> sadd set1 B
(integer) 1
127.0.0.1:6379> sadd set1 C
(integer) 1
127.0.0.1:6379> sadd set2 B
(integer) 1
127.0.0.1:6379> sadd set2 C
(integer) 1
127.0.0.1:6379> sadd set2 D
(integer) 1
127.0.0.1:6379> sadd set2 E
(integer) 1
127.0.0.1:6379> sinter set1 set2 # 交集
1) "B"
2) "C"
127.0.0.1:6379> sunion set1 set2 # 并集
1) "D"
2) "E"
3) "C"
4) "B"
5) "A"
127.0.0.1:6379> sdiff set1 set2 # 差集
1) "A"
(四) 有序集合类型 - sortedset/zset
此类型和 set 一样也是 string 类型元素的集合,且不允许重复的元素
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序
有序集合的成员是唯一,但分数(score)却可以重复
(1) 添加
- 语法:zadd key score value [score value ... ...]
127.0.0.1:6379> zadd sortedset1 20 zhangsan # 添加一个(integer) 1
127.0.0.1:6379> zadd sortedset1 10 lisi 60 wangwu # 添加多个
(integer) 2
(2) 获取
A:获取所有值(默认排序)
语法:zrange sortedset start end [withscores]
- 根据那个值的大小进行了排序,例如上面的 10 20 60
127.0.0.1:6379> zrange sortedset1 0 -11) "lisi"
2) "zhangsan"
3) "wangwu"
B:获取所有值(从小到大和从大到小)
- zrangebyscore sortedset -inf +inf:从小到大
- zrevrange sortedset 0 -1:从大到小
127.0.0.1:6379> zrangebyscore sortedset1 -inf +inf # 从小到大1) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrevrange sortedset1 0 -1 # 从大到小
1) "wangwu"
2) "zhangsan"
3) "lisi"
C:获取值且附带数值
- zrangebyscore sortedset -inf +inf withscores:从小到大且附带值
127.0.0.1:6379> zrangebyscore sortedset1 -inf +inf withscores # 显示从小到大且附带值1) "lisi"
2) "10"
3) "zhangsan"
4) "20"
5) "wangwu"
6) "60"
127.0.0.1:6379> zrangebyscore sortedset1 -inf 20 withscores # 显示从小到大,且数值小于20的
1) "lisi"
2) "10"
3) "zhangsan"
4) "20"
127.0.0.1:6379>
D:获取有序集合中的个数
- 语法:zcard sortedset
127.0.0.1:6379> zcard sortedset1(integer) 2
E:获取指定区间成员数量
- 语法:zcount sortedset start end (strat 和 end是指那个数值,而不是什么下标)
127.0.0.1:6379> zcount sortedset1 10 60(integer) 3
(2) 删除
- zrem key value
127.0.0.1:6379> zrange sortedset1 0 -11) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrem sortedset1 wangwu # 删除 wangwu 这个元素
(integer) 1
127.0.0.1:6379> zrange sortedset1 0 -1
1) "lisi"
2) "zhangsan"
(五) 哈希类型 - hash
(1) 添加
A:普通添加
- 语法:hset hash field value
127.0.0.1:6379> hset hash1 username admin(integer) 1
127.0.0.1:6379> hset hash1 password admin
(integer) 1
B:不存在才可以添加
- 语法:hsetnx hash filed value
127.0.0.1:6379> hsetnx hash1 username admin888 # 已存在,失败(integer) 0
127.0.0.1:6379> hsetnx hash1 code 666 # 不存在,成功
(integer) 1
(2) 获取
A:获取指定的field对应的值
- 语法:hget hash field [ key field ... ...]
127.0.0.1:6379> hget hash1 password"admin"
B:获取所有的field和value
- 语法:hgetall hash
127.0.0.1:6379> hgetall hash11) "username"
2) "admin"
3) "password"
4) "admin"
C:获取 hash 的字段数量
- 语法:hlen hash
127.0.0.1:6379> hlen hash1(integer) 2
D:只获取所有 field 或 value
- hkeys hash:获取所有 field 字段
- hvals hash:获取所有 value 值
127.0.0.1:6379> hkeys hash1 # 获取所有 field 字段1) "username"
2) "password"
127.0.0.1:6379> hvals hash1 # 获取所有 value 值
1) "admin"
2) "admin"
(3) 删除
- 语法:hdel hash field
127.0.0.1:6379> hdel hash1 username(integer) 1
(4) 自增自减
- hincrby hash field 增量
127.0.0.1:6379> hsetnx hash1 code 666(integer) 1
127.0.0.1:6379> hincrby hash1 code 2
(integer) 668
127.0.0.1:6379> hincrby hash1 code -68
(integer) 600
五 三种特殊数据类型
(一) Geospatial(地理位置)
使用经纬度,作为地理坐标,然后存储到一个有序集合 zset/sortedset 中去保存,所以 zset 中的命令也是可以使用的
- 特别是需要删除一个位置时,没有GEODEL命令,是因为你可以用ZREM来删除一个元素(其结构就是一个有序结构)
- Geospatial 这个类型可以用来实现存储城市坐标,一般都不是自己录入,因为城市数据都是固定的,所以都是通过 Java 直接导入的,下面都是一些例子而已
- Geospatial 还可以用来实现附近的人这种概念,每一个位置就是人当前的经纬度,还有一些能够测量距离等等的方法,后面都会提到
命令列表:
(1) 存储经纬度
语法:geoadd key longitud latitude member [..]
- longitud——经度、 latitude——纬度
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
127.0.0.1:6379> geoadd china:city 116.413384 39.910925 beijing(integer) 1
127.0.0.1:6379> geoadd china:city 113.271431 23.135336 guangzhou
(integer) 1
127.0.0.1:6379> geoadd china:city 113.582555 22.276565 zhuhai
(integer) 1
127.0.0.1:6379> geoadd china:city 112.556391 37.876989 taiyuan
(integer) 1
(2) 获取集合中一个或者多个成员的坐标
- 语法:geopos key member [member..]
127.0.0.1:6379> geopos china:city beijing zhuhai1) 1) "116.41338318586349487"
2) "39.9109247398676743"
2) 1) "116.41338318586349487"
2) "39.9109247398676743"
(3) 返回两个给定位置之间的距离
语法:geodist key member1 member2 [unit]
- 单位默认为米,可以修改,跟在 member 后即可,例如 km
指定单位的参数 unit 必须是以下单位的其中一个:
m 表示单位为米
km 表示单位为千米
mi 表示单位为英里
ft 表示单位为英尺
127.0.0.1:6379> geodist china:city guangzhou taiyuan"1641074.3783"
127.0.0.1:6379> geodist china:city guangzhou taiyuan km
"1641.0744"
(4) 查找附近的元素(给定经纬度和长度)
- 含义:以给定的经纬度为中心, 返回集合包含的位置元素当中
语法:georadius key longitude latitude radius m|km|mi|ft WITHCOORD [WITHHASH] [COUNT count]
- 与中心的距离不超过给定最大距离的所有位置元素
通过
georadius就可以完成 附近的人功能(例如这个位置我们输入的是人当前的位置)- withcoord:带上坐标
- withdist:带上距离,单位与半径单位相同
- count :只显示前n个(按距离递增排序)
127.0.0.1:6379> georadius china:city 113.582555 22.276565 500 km1) "zhuhai"
2) "guangzhou"
127.0.0.1:6379> georadius china:city 113.582555 22.276565 500 km withdist withcoord count 1
1) 1) "zhuhai"
2) "0.0002"
3) 1) "113.58255296945571899"
2) "22.27656546780746538"
127.0.0.1:6379> georadius china:city 113.582555 22.276565 500 km withdist withcoord count 2
1) 1) "zhuhai"
2) "0.0002"
3) 1) "113.58255296945571899"
2) "22.27656546780746538"
2) 1) "guangzhou"
2) "100.7111"
3) 1) "113.27143281698226929"
2) "23.13533660075498233"
(5) 查找附近的元素(指定已有成员和长度)
- 含义:5 与 4 相同,给定的不是经纬度而是集合中的已有成员
- 语法:GEORADIUSBYMEMBER key member radius...
127.0.0.1:6379> georadiusbymember china:city zhuhai 500 km1) "zhuhai"
2) "guangzhou"
(6) 返回一个或多个位置元素的Geohash表示
- 语法:geohash key member1 [member2..]
127.0.0.1:6379> geohash china:city zhuhai1) "weby8xk63k0"
(二) Hyperloglog(基数统计)
HyperLogLog 是用来做基数(数据集中不重复的元素的个数)统计的算法,其底层使用string数据类型
HyperLogLog 的优点是:
在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的
- 花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
一个常见的例子:
- 传统实现,存储用户的id,然后每次进行比较。当用户变多之后这种方式及其浪费空间,而我们的目的只是计数,Hyperloglog就能帮助我们利用最小的空间完成。
(1) 添加
含义:添加指定元素到 HyperLogLog 中
语法:PFADD key element1 [elememt2..]
127.0.0.1:6379> pfadd test1 A B C D E F G(integer) 1
127.0.0.1:6379> pfadd test2 C C C D E F G
(integer) 1
(2) 估算myelx的基数
含义:返回给定 HyperLogLog 的基数估算值
语法:PFCOUNT key [key]
127.0.0.1:6379> pfcount test1(integer) 7
127.0.0.1:6379> pfcount test2
(integer) 5
(3) 合并
含义:将多个 HyperLogLog 合并为一个 HyperLogLog
语法:PFMERGE destkey sourcekey [sourcekey..]
127.0.0.1:6379> pfmerge test test1 test2OK
127.0.0.1:6379> pfcount test
(integer) 9
(三) BitMaps(位图)
BitMaps 使用位存储,信息状态只有 0 和 1
- Bitma p是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR,NOT以及其它位操作
- 这种类型的应用场景很多,例如统计员工是否打卡,或者登陆未登录,活跃不活跃,都可以考虑使用此类型
(1) 设置值
- 含义:为指定key的offset位设置值
- 语法:setbit key offset value
127.0.0.1:6379> setbit sign 0 1(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 0
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
(2) 获取
- 含义:获取offset位的值
- 语法:getbit key offset
127.0.0.1:6379> getbit sign 4(integer) 1
127.0.0.1:6379> getbit sign 2
(integer) 0
(3) 统计
- 含义:统计字符串被设置为1的bit数,也可以指定统计范围按字节
- 语法:bitcount key [start end]
127.0.0.1:6379> bitcount sign(integer) 4
六 事务
(一) 定义
定义:Redis 事务的本质是一组命令的集合
- 事务支持一次执行多个命令,一个事务中所有命令都会被序列化
- 在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中
即:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令
首先
(二) 特点
(1)不保证原子性
可能受到关系型数据库的影响,大家会将事务一概而论的认为数据库中的事务都是原子性的,但其实,Redis 中的事务是非原子性的。
原子性:所有的操作要么全做完,要么就全不做,事务必须是一个最小的整体,即像化学组中的原子,是构成物质的最小单位。
- 数据库中的某个事务中要更新 t1表、t2表的某条记录,当事务提交,t1、t2两个表都被更新,只要其中一个表操作失败,事务就会回滚
非原子性:与原子性反之
- 数据库中的某个事务中要更新 t1表、t2表的某条记录,当事务提交,t1、t2两个表都被更新,若其中一个表操作失败,另一个表操作继续,事务不会回滚
(2) 不支持事务回滚
多数事务失败是由语法错误或者数据结构类型错误导致的,而语法的错误是在命令入队前就进行检测,而类型错误是在执行时检测的,Redis为提升性能而采用这种简单的事务
(3) 事务没有隔离级别的概念
批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到
(三) 相关命令
(1) 开启事务
含义:开启事务,下一步就会将内容逐个放入队列中去,然后通过 exec 命令,原子化的执行
命令:multi
由于 multi 和 exec 需要搭配使用,所以在第二点一起演示示例
(2) 执行事务
含义:执行事务中的所有操作
命令:exec
A:正常开启且执行一个事务
首先先存一个 k1 和 k2,开启事务后,对这两个值进行修改,然后将这个事务执行,最后发现两个 OK ,然后用 get 查看一下值的变化
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11 # 修改 k1
QUEUED
127.0.0.1:6379> set k2 v22 # 修改 k2
QUEUED
127.0.0.1:6379> exec # 执行事务
1) OK
2) OK
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> get k2
"v22"
B:语法错误导致的事务失败
语法错误(编译器错误)导致的事务失败,会使得保持原值,例如下文事务中,修改 k1 没问题,但是修改 k2 的时候出现了语法错误,set 写成了 sett ,执行 exec 也会出错,最后发现 k1 和 k2 的值都没有变
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11 # 修改正常
QUEUED
127.0.0.1:6379> sett k2 v22 # 修改有语法错误
(error) ERR unknown command `sett`, with args beginning with: `k2`, `v22`,
127.0.0.1:6379> exec # 执行事务
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k2
"v2"
C:类型错误导致的事务失败
类型错误(运行时错误)导致的事务异常,例如下面 k2 被当做了一个 list 处理,这样在运行时就会报错,最后事务提交失败,但是并不会回滚,结果就是 k1 修改成功,而 k2 失败
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11
QUEUED
127.0.0.1:6379> lpush k2 v22 # 类型错误
QUEUED
127.0.0.1:6379> exec # 执行事务
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> get k2
"v2"
(3) 取消事务
这个没什么好说的,就是取消执行
127.0.0.1:6379> multiOK
127.0.0.1:6379> set k1 k11
QUEUED
127.0.0.1:6379> set k2 k22
QUEUED
127.0.0.1:6379> discard
OK
(4) watch 监控
Redis的命令是原子性的,而事务是非原子性的,通过 watch 这个命令可以实现 Redis 具有回滚的一个效果
做法就是,在 multi 之前先用 watch 监控某些键值对,然后继续开启以及执行事务
- 如果 exec 执行事务时,这些被监控的键值对没发生改变,它会执行事务队列中的命令
- 如果 exec 执行事务时,被监控的键值对发生了变化,则将不会执行事务中的任何命令,然后取消事务中的操作
我们监控 k1,然后再事务开启之前修改了 k1,又想在事务中修改 k1 ,可以看到最后结果中,事务中的操作就都没有执行了
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> watch k1 # 监控 k1
OK
127.0.0.1:6379> set k1 v111111 # k1 被修改了
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11
QUEUED
127.0.0.1:6379> set k2 v22
QUEUED
127.0.0.1:6379> exec # 执行事务
(nil)
127.0.0.1:6379> get k1
"v111111"
127.0.0.1:6379> get k2
"v2"
(5) unwatch 取消监控
取消后,就可以正常执行了
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> watch k1 # 监控
OK
127.0.0.1:6379> set k1 v111111
OK
127.0.0.1:6379> unwatch # 取消监控
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v11
QUEUED
127.0.0.1:6379> set k2 v22
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> get k2
"v22"
七 IDEA 中使用 Jedis 操作 Redis
Jedis 是一款可以让我们在java中操作redis数据库的工具,下载其jar包,或者引入到 maven 中即可,使用还是非常简单的
(一) 引入依赖和编码
我这里创建了一个空项目,然后创建一个普通的 maven 模块用来演示 jedis
首先引入 jedis 依赖,后面需要所以还引入了fastjson
版本自己去 maven 中去查就可以了,因为我们 linux 中安装的 redis 是一个新的版本,所以我们依赖也用了最新的
<dependencies><dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
创建测试类
- 如果是本机,例如 windows 下,启动 win 下的 redis 服务,然后用 127.0.0.1 访问
- 如果是远程机器,虚拟机或者云服务器,使用对应 ip 访问
- new Jedis 时空构造代表默认值 "localhost", 6379端口
public class Demo01 {public static void main(String[] args) {
// 远程 linux(虚拟机)
Jedis jedis = new Jedis("192.168.122.1", 6379);
// 测一下是否连通
System.out.println(jedis.ping());
}
}
(二) 连接 linux 的操作步骤
如果直接输入ip和端口,会连接不上,所以需要先做以下操作
① 保证 6379 端口开放
以 centos 7.9 为例,其他版本例如 6.x 可以查一下具体命令,以及防火墙是不是给拦截了,只要保证端口能访问到就可以了
- 开启6379端口
firewall-cmd --zone=public --add-port=6379/tcp --permanent# 显示
succss
- 重启防火墙
firewall-cmd --reload# 显示
success
- 检查端口是否开启
firewall-cmd --query-port=6379/tcp# 显示
yes
- 重启 redis 服务
[[email protected] bin]# redis-cli shutdown[[email protected] bin]# redis-server myconfig/redis.conf
你还可以在 window 的机器上,使用 telnet 192.168.122.1 6379 的方式测试一下是否能访问到,如果出现错误,请检查端口和防火墙的问题
② 修改 redis 配置文件
- 注释绑定的ip地址(注释掉 bind 127.0.0.1 这一句)
设置保护模式为 no(protected-mode 把 yes 改为 no)
- Linux上的 redis 处于安全保护模式,这就让你无法从虚拟机外部去轻松建立连接,所以在 redis.conf 中设置保护模式(protected-mode)为 no
")
再次在 IDEA 中访问,就可以访问到了
(三) 常见 API
(1) 字符串类型 - String
// 存储jedis.set("address","beijing");
// 获取
String address = jedis.get("address");
// 关闭连接
jedis.close();
补充:setex() 方法可以存储数据,并且指定过期时间
// 将aaa-bbb存入,且10秒后过期jedis.setex("aaa",10,"bbb")
(2) 列表类型 - list
// 存储jedis.lpush("listDemo","zhangsan","lisi","wangwu");//从左
jedis.rpush("listDemo","zhangsan","lisi","wangwu");//从右
// 获取
List<String> mylist = jedis.lrange("listDemo", 0, -1);
// 删除,并且返回元素
String e1 = jedis.lpop("listDemo");//从左
String e2 = jedis.rpop("listDemo");//从右
// 关闭连接
jedis.close();
(3) 集合类型 - set
// 存储jedis.sadd("setDemo","zhangsan","lisi","wangwu");
// 获取
Set<String> setDemo = jedis.smembers("setDemo");
// 关闭连接
jedis.close();
(4) 有序集合类型 - sortedset/zset
// 存储jedis.zadd("sortedsetDemo",20,"zhangsan");
jedis.zadd("sortedsetDemo",10,"lisi");
jedis.zadd("sortedsetDemo",60,"wangwu");
// 获取
Set<String> sortedsetDemo = jedis.zrange("sortedsetDemo", 0, -1);
// 关闭连接
jedis.close();
(5) 哈希类型 - hash
// 存储jedis.hset("hashDemo","name","lisi");
jedis.hset("hashDemo","age","20");
// 获取
String name = jedis.hget("hashDemo", "name");
// 获取所有数据
Map<String, String> user = jedis.hgetAll("hashDemo");
Set<String> keySet = user.keySet();
for (String key : keySet) {
//获取value
String value = user.get(key);
System.out.println(key + ":" + value);
}
// 关闭连接
jedis.close();
(四) Jedis 执行事务
public class Demo01 {public static void main(String[] args) {
// 远程 linux(虚拟机)
Jedis jedis = new Jedis("192.168.122.1", 6379);
JSONObject jsonObject = new JSONObject();
jsonObject.put("name", "zhangsan");
jsonObject.put("age", "21");
// 开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
try {
multi.set("userA", result);
multi.set("userB", result);
// 执行事务
multi.exec();
} catch (Exception e) {
// 放弃事务
multi.discard();
} finally {
System.out.println(jedis.get("userA"));
System.out.println(jedis.get("userB"));
// 关闭连接
jedis.close();
}
}
}
为了将结果显示出来,在关闭前添加两句输出语句
执行结果:
{"name":"zhangsan","age":"21"}
{"name":"zhangsan","age":"21"}
(五) Jedis 连接池
为什么我们要使用连接池呢?
我们要使用Jedis,必须建立连接,我们每一次进行数据交互的时候,都需要建立连接,Jedis虽然具有较高的性能,但建立连接却需要花费较多的时间,如果使用连接池则可以同时在客户端建立多个连接并且不释放,连接的时候只需要通过一定的方式获取已经建立的连接,用完则归还到连接池,这样时间就大大的节省了
下面就是我们直接创建了一个连接池,不过我们使用时一般都会封装一个工具类
@Testpublic void testJedisPool(){
// 0.创建一个配置对象
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(50);
config.setMaxIdle(10);
// 1.创建Jedis连接池对象
JedisPool jedisPool = new JedisPool(config,"192.168.122.1",6379);
// 2.获取连接
Jedis jedis = jedisPool.getResource();
// 3. 存储
jedis.set("name","zhangsan");
// 4. 输出结果
System.out.println(jedis.get("name"));
//5. 关闭 归还到连接池中
jedis.close();;
}
(一) 连接池工具类
直接使用工具类就可以了
import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
/**
* JedisPool工具类
* 加载配置文件,配置连接池的参数
* 提供获取连接的方法
*/
public class JedisPoolUtils {
private static JedisPool jedisPool;
static {
//读取配置文件
InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties");
//创建Properties对象
Properties pro = new Properties();
//关联文件
try {
pro.load(is);
} catch (IOException e) {
e.printStackTrace();
}
//获取数据,设置到JedisPoolConfig中
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal")));
config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle")));
//初始化JedisPool
jedisPool = new JedisPool(config, pro.getProperty("host"), Integer.parseInt(pro.getProperty("port")));
}
/**
* 获取连接方法
*/
public static Jedis getJedis() {
return jedisPool.getResource();
}
}
别忘了配置文件
host=192.168.122.1port=6379
maxTotal=50
maxIdle=100
调用代码
@Testpublic void testJedisPoolUtil(){
// 0. 通过连接池工具类获取
Jedis jedis = JedisPoolUtils.getJedis();
// 1. 使用
jedis.set("name","lisi");
System.out.println(jedis.get("name"));
// 2. 关闭 归还到连接池中
jedis.close();;
}
八 SpringBoot 整合 Redis
(一) 简单使用(存在序列化问题)
① 创建 Springboot项目或模块,引入依赖
<dependency><groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
可以看到,这个官方的 starter 引入了 Redis,但是并没有引入 Jedis,而是引入了 Lettuce
")
② 编写配置文件
# 配置redisspring.redis.host=192.168.122.1
spring.redis.port=6379
③ 测试代码
@SpringBootTestclass Redis02BootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","zhangsan");
System.out.println(redisTemplate.opsForValue().get("name"));
}
}
运行结果:
zhangsan
(二) 使用自定义 RedisTemplate 模板(推荐)
上述操作,在 IDEA 中的结果肯定是没问题的,但是我们去 Linux 中去看一下 Redis 的内容,却发现 key 都是乱码,例如存储的 name 却变成了如下内容
127.0.0.1:6379> keys *1) "\xac\xed\x00\x05t\x00\x04name"
这就是序列化的问题,下面我们会分析这个问题,这里先给出解决方案,即自定义 RedisTemplate 模板
① 自定义 RedisConfig 类
@Configurationpublic class RedisConfig {
/**
* 自定义 RedisTemplate 怒ban
*
* @param factory
* @return
*/
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 为开发方便,一般直接使用 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
② 调用
@SpringBootTestclass Redis02BootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("address","beijing");
System.out.println(redisTemplate.opsForValue().get("address"));
}
}
我们分别存储了 name2 和 address 这两个key,去终端中查看一下
127.0.0.1:6379> keys *1) "address"
2) "\xac\xed\x00\x05t\x00\x04name"
3) "name2"
可以看到,问题被解决了
(三) 封装一个工具类
我们操作追求的是便捷,而每次都是用一大堆 redisTemplate.opsForValue().xxxxx 很长的命令,所以封装一个工具类能更加事半功倍,具体工具类我就不在这里贴了,因为太长了,后面我会传到 github上去然后更新链接,当然了百度上其实一搜一大把
例如下面,我们使用工具类后就可以很简单的使用封装 redisTemplate 后的方法了
@Autowiredprivate RedisUtil redisUtil;
@Test
void contextLoads() {
redisUtil.set("address2", "zhuhai");
System.out.println(redisUtil.get("address2"));
}
(四) 简单分析原理
这一块的简单分析,主要想要弄清楚四个内容
- ① 是不是不再使用 Jedis 了,而是使用 Lettuce
- ② 查看配置文件的配置属性
- ③ 如何操作 Redis
- ④ 序列化问题(即存储乱码问题)
在以前 Springboot 的文章中,关于自动配置的原理中可知,整合一个内容的时候,都会有一个自动配置类,然后再 spring.factories 中能找到它的完全限定类名
")
进入 spring.factories,查找关于 redis 的自动装配类
")
进入 RedisAutoConfiguration 类后,在注解中就能看到 RedisProperties 类的存在,这很显然是关于配置文件的类
@Configuration(proxyBeanMethods = false)@ConditionalOnClass(RedisOperations.class)
// 这个注解!!!
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
// ...... 省略
}
进入 RedisProperties 类
alt + 7 可以在 IDEA 中查看到这个类中的属性方法等,这里查看一下其属性
")
例如地址端口,超时时间等等配置都清楚了,例如我们当时的配置文件是这样配的
# 配置redisspring.redis.host=192.168.122.1
spring.redis.port=6379
继续回到类,查看下面一个注解,发现有两个类
- LettuceConnectionConfiguration
- JedisConnectionConfiguration
@Configuration(proxyBeanMethods = false)@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
// 这个注解!!!
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
// ...... 省略
}
先来进入 Jedis 这个看看,GenericObjectPool 和 Jedis 这两个内容都是默认缺失的,所以是不会生效的
")
再来看看 LettuceConnectionConfiguration,是没有问题的,所以确实现在默认的实现都是使用 Lettuce 了
")
继续回到 RedisAutoConfiguration
其 Bean 只有两个
- RedisTemplate
- StringRedisTemplate
这种 XxxTemplate ,例如 JdbcTemplate、RestTemplate 等等都是通过 Template 来操作这些组件,所以这里的两个 Template 也是这也昂,分别用来操作 Redis 和 Redis 的 String 数据类型(因为 String 类型很常用)
// 注解略public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
特别注意这一个注解
@ConditionalOnMissingBean(name = "redisTemplate")它的意思就是说如果没有自定义,就默认使用这个,这也就是告诉我们,我们可以自己自定义Template,来覆盖掉默认的,前面的使用中我们知道,使用默认的 Template 会涉及到乱码,也就是序列化问题
因为在网络中传输的对象需要序列化,否则就是乱码
我们进入默认的 RedisTemplate 看看
首先看到的就是一些关于序列化的参数
")
往下看,可以看到默认的序列化方式使用的是 Jdk 序列化,而我们自定义中使用的是 Json 序列化
")
而默认的RedisTemplate中的所有序列化器都是使用这个序列化器
")
RedisSerializer 中为我们提供了多种序列化方式
")
所以后来我们就自定了 RedisTemplate 模板,重新定义了各种类型的序列化方式,这也是我们推荐的做法
linuxredisjava后端
阅读 53发布于 今天 02:00
本作品系原创,采用《署名-非商业性使用-禁止演绎 4.0 国际》许可协议
理想二旬不止
BWH_Steven
原创JAVA技术公众号:理想二旬不止
153 声望
8 粉丝
BWH_Steven
原创JAVA技术公众号:理想二旬不止
153 声望
8 粉丝
宣传栏
Redis 基础以及进阶的两篇已经全部更新好了,为了字数限制以及阅读方便,分成两篇发布。
本篇主要内容为:NoSQL 引入 Redis ,以及在 Linux7 环境下的安装,配置,以及总结了非常详细的类型,用法以及例子,最后通过 Jedis 以及 Springboot 中的 RedisTemplate 在 IDEA 中远程操作
Redis。
第二篇会主要涉及到配置文件,发布订阅,主从复制,哨兵等一些进阶用法的一个基本使用。
一 简述 NoSQL
可以简单的说,Redis就是一款高性能的NoSQL数据库
(一) 什么是NoSQL?
我们前面所学习的MySQL数据库是典型的的SQL数据库也就是传统的关系型数据库,而我们今天学习的Redis数据库则是一款NoSQL数据库,也叫作非关系型数据库,它与我们熟悉的MySQL等的概念完全是不一样的,它是一项全新的数据库理念,我们帖一组百度百科的解释
说明:我们现在所看到的的博客,RSS,P2P,微博,抖音等均属于 Web2.0的产物,Web2.0相比较过去的Web1.0更加注重于用户的交互,用户不仅可以浏览,还可以上传一些资源到网站上,例如图片文字或者说短视频等,使得用户也参与到了网站内容的制造中去了
(二) 为什么使用NoSQL?
- 部署成本低:部署操作简单,以开源软件为主
- 存储格式丰富:支持 key-value形式、文档、图片等众多形式,包括对象或者集合等格式
- 速度快:数据存储在缓存中,而不是硬盘中,而且例如Redis基于键值对,同时不需要经过SQL层解析,性能非常高
无耦合性,易扩展
- 在SQL中,一个正在使用的数据是不允许删除的,但NoSQL却可以操作
(三) NoSQL可以替代SQL吗?
有人会说,NoSQL = Not SQL ,但是我更倾向这样理解 NoSQL = Not only SQL ,我们不能以一个绝对的结论来判定两项技术的好坏,每一项技术的产生都有其特定的原因,在我看来,NoSQL更适合作为SQL数据库的补充,由于海量数据的出现,性能的要求高了起来,而NoSQL这种产物,对于结构简单但是数据量大的数据处理起来要比传统的SQL快很多,但是同样的,其逻辑运算就必须很简单,否则它也是力不从心的
在我看来,可以简单的说,NoSQL就是以功能换取性能,但是需要处理复杂的业务逻辑还需要使用关系型数据库,所以说想要在模型中完全用NoSQL替代SQL是不现实的,两者更像是互补的关系
SQL的好处:
- 支持在一个表以及多表之前进行复杂的查询操作
- 支持对事物的处理,能保证数据的安全要求
- 学习成本低,资料较多
市面上的NoSQL产品非常多,我们今天所要介绍的就是其中一款基于键值存储的数据库——Redis
(四)NoSQL数据库的四大分类表格分析
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
二 初识Redis
(一) 什么是 Redis
我们在一开始提到了,Redis就是一款高性能的NoSQL数据库,那么它的应用场景是什么呢?
- 用于用户内容缓存,可以处理大量数据的高访问负载,例如:数据查询,新闻,商品内容
- 任务队列,例如:秒杀,12306
- 在线好友列表
- 应用、网站访问统计排行
由于其基于键值存储,那么可以支持的存储的类型有什么呢?
- 字符串类型 - String
- 列表 - list:linkedlist
- 集合 - set
- 有序集合 - sortedset
- 哈希 - hash:map
(二)下载安装
说明:
推荐使用 Linux 进行部署,所以我们后面也会详细介绍 Linux 中的安装配置方式,但是如果只是想快速学习语法,也可以勉强使用 Windows 版本,安装会简单很多。
(1) linux 推荐
官网:https://redis.io(推荐)
- 访问可能较慢
中文网:http://www.redis.net.cn
- 版本有一些滞后,例如官网已经 6.0.9 了,中文网首页仍挂着 5.0.4
A:下载
# 下载 redis-6.0.9 压缩包wget http://download.redis.io/releases/redis-6.0.9.tar.gz
补充:
- 可以通过 http://download.redis.io/rele... 查看选择需要的版本
- 此方式下载后的压缩文件位于
/home目录下
B:解压
一般来说,我们程序都会放在 /opt 目录下,所以我们先将这个压缩文件移动过去再解压
# 移动此文件到根目录下的 opt 目录中mv redis-6.0.9.tar.gz /opt
# 解压此文件
tar -zxvf redis-6.0.9.tar.gz
解压后 opt 目录下就多出一个 redis-6.0.9 的文件夹,我们打开它,就可以看到一些文件在其中,其中 redis.conf 是我们一会要用的配置文件,暂时先不理会
解压后的文件貌似也不能运行啊,这是当然的,因为这些文件还没有经过编译和安装,在编译之前,首先要检查一下 GCC 的版本
C:检查 GCC 版本(Redis 6 以下可以忽略)
如果你选择的是 Redis 6 以上的版本,例如这里选择的 6.0.9,你的 gcc 版本如果太低就会导致后面编译出错,最起码你的 gcc 要到 5.3 的版本以上
如果没有 gcc 先进行安装
yum -y install gccyum -y install gcc-c++
安装完成后,通过 gcc -v 查看到安装到的版本是 4.x.x 版本的,所以要升级,旧版本的 Redis 可以不去做升级这一步
依次执行下面每一条命令
# 升级到gcc 9.3yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
# scl命令启用只是临时的,退出shell或重启就会恢复原系统gcc版本
scl enable devtoolset-9 bash
# 长期使用 gcc 9.3 还需要进行如下操作
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
source /etc/profile
查看一下更新后的版本
D:编译安装
依次执行编译和安装,
# 编译make
# 安装
make install
make 会慢一下,耐心等待一下,如果出了错误,一般都是 gcc 的问题
安装后的内容一般都在 /usr/local/bin 下
E:拷贝配置文件
我们把原来的配置文件就放在那个解压文件中,我们自己用的,单独复制一份出来,方便我们操作和更改
我们先去 /usr/local/bin 中创建一个新的文件夹,然后把之前解压后的文件夹中的 redis.conf 拷贝过来
# 跳转到指定目录下cd /usr/local/bin
# 新建一个文件夹
mkdir myconfig
# 复制 /opt/redis-6.0.9/redis.conf 到 当前目录的 myconfig 文件夹下
cp /opt/redis-6.0.9/redis.conf myconfig
看一下过程
F:开启后台运行
为了保证我们的redis可以后台运行,我们去编辑拷贝过来的 redis.conf 配置文件
vim redis.conf在其中找到 daemonize no
将 no 修改为 yes,保存退出
G:运行 Redis
下面先运行一下其服务端(保证当前在 usr/local/bin 目录下)
# 运行服务端redis-server myconfig/redis.conf
- 加 myconfig/redis.conf 就是为了制定其启动使用的配置文件
接着运行其客户端
# 运行客户端redis-cli -p 6379
- 因为本身就是本机,所以只需要指定端口就行了,不需要指定ip
可以简单测试一下,例如 set get 一下,能拿到值就代表成功了
H:关闭服务以及检查进程是否存在
先看一下运行中时,进程的存在情况
# 查看redis 进程ps -ef|grep redis
在客户端中,可以通过 shutdown 和 exit 执行关闭(这个是在Redis客户端中执行)
# 关闭127.0.0.1:6379> shutdown
not connected> exit
# 再次查看一下进程状况
[[email protected] bin]# ps -ef|grep redis
(2) windows 不推荐
我们可以去github中寻找windows版本,不过版本会有所滞后,官方起码是没有支持更新的,可能微软还想着能拽他一把。最新的版本好像也都是好几年前的了
https://github.com/microsofta...
解压即可用:分别启动 redis-server.exe 和 redis-cli.exe 就能直接测试使用了吗,有问题修改redis.windows.conf 配置文件
- redis-server.exe:redis服务器端
- redis-cli.exe:redis的客户端
- redis.windows.conf:配置文件
三 Redis 通用命令
(一) 开闭命令
(1) 启动 Redis 服务
redis-server [--port 6379]有时候参数会过多,建议使用配置文件启动
redis-server [xx/redis.conf]例如:redis-server myconfig/redis.conf
(2) 客户端连接 Redis
redis-cli [-h 127.0.0.1 -p 6379]例如 :redis-cli -p 6379
(3) 停止 Redis
在客户端中(标志有 127.0.0.1:6379>)直接输入 shutown 等即可
# 关闭127.0.0.1:6379> shutdown
not connected> exit
若在目录中(前面为 $ 等),可以执行
redis-cli shutdownkill redis-pid
(4) 测试连通性
返回 PONG 即连通了
127.0.0.1:6379> pingPONG
(二) key 以及通用操作
注:每一种类型的存储方式是不太一样的,所以这里的操作不会讲到添加存储,下面会在每种类型中详细讲解。
只是想简单先测试,可以先暂时用这几个命令(这是 String 类型的)
可以使用
set key value添加- set 为命令,key 为键,value 为值
- 例如:
set test ideal-20
get key获取到值
(1) 获取所有键
- 语法:keys pattern
127.0.0.1:6379> keys *1) "test"
2) "test2"
*作为通配符,表示任意字符,因为其会遍历所有键,然后显示所有键列表,时间复杂度O(n),数据量过大的环境,谨慎使用
(2) 获取键总数
- 语法:dbsize
127.0.0.1:6379> dbsize(integer) 2
- 内部变量存储此值,执行获取操作时,非遍历,因此时间复杂度O(1)
(3) 判断当前 key 是否存在
- 语法:exists key [key ...]
127.0.0.1:6379> exists test(integer) 1
- 最后返回的是存在的个数
(4) 查询键类型
- 语法: type key
127.0.0.1:6379> type teststring
(5) 移动键
- 语法:move key db
127.0.0.1:6379> move test2 3(string) 1
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> keys *
1) "ideal-20-2"
- 注:Redis 默认有 16 个数据库 move 代表移动到其中哪个去,然后 select 代表切换到这个数据库
(6) 删除键
- 语法:del key [key ...]
127.0.0.1:6379> del test2(integer) 1
(7) 设置过期时间
- 秒语法:expire key seconds
- 毫秒语法:pexpire key milliseconds
127.0.0.1:6379> expire test 120(integer) 1
(8) 查询key的生命周期(秒)
- 秒语法:ttl key
- 毫秒语法:pttl key
127.0.0.1:6379> ttl test(integer) 116
(9) 设置永不过期
- 语法:persist key
127.0.0.1:6379> persist test(integer) 1
127.0.0.1:6379> ttl test
(integer) -1
(10) 更改键的名称
- 语法:rename key newkey
127.0.0.1:6379> rename test idealOK
127.0.0.1:6379> keys *
1) "ideal"
(11) 清除当前数据库
- 语法:flushdb
127.0.0.1:6379> flushdbOK
127.0.0.1:6379> keys *
(empty array)
(12) 清除全部数据库的内容
- 语法:flushall
127.0.0.1:6379> flushallOK
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379>
四 常见支持类型操作
(一) 字符串类型 - string
(1) 存储
语法:set key value [EX seconds] [PX milliseconds] [NX|XX]
- 后面还可以选择性的跟随过期时间
127.0.0.1:6379> set address beijing 5000OK
(2) 获取
- 语法:get key
127.0.0.1:6379> get address“beijing”
(3) 删除
- 语法:del key
127.0.0.1:6379> del address(string) 1
(4) 递增或递减
如果字符串中的值为数字类型,可以进行递增递减,其它类型会报错
- 递增语法:incr key
- 递增语法(指定步长):incrby key step
- 递减语法:decr key
- 递减语法(指定步长):decrby key step
127.0.0.1:6379> set age 21OK
127.0.0.1:6379> incr age # 递增
(integer) 22
127.0.0.1:6379> incrby age 5 # 递增 5
(integer) 27
127.0.0.1:6379> decr age # 递减
(integer) 26
127.0.0.1:6379> decrby age 5 # 递减 5
(integer) 21
(5) 追加内容
- 语法:append key value
127.0.0.1:6379> set ideal helloOK
127.0.0.1:6379> append ideal ,ideal-20 # 追加内容
(integer) 14
127.0.0.1:6379> get ideal
"hello,ideal-20"
(6) 截取部分字符串
- 语法:getrange key start end
127.0.0.1:6379> get ideal"hello,ideal-20"
127.0.0.1:6379> getrange ideal 0 3
"hell"
127.0.0.1:6379> getrange ideal 0 -1
"hello,ideal-20"
(7) 替换部分字符串
- 语法:setrange key start
127.0.0.1:6379> get ideal"hello,ideal-20"
127.0.0.1:6379> setrange ideal 6 bwh # 从下标为6的位置开始替换
(integer) 14
127.0.0.1:6379> get ideal
"hello,bwhal-20"
(8) 获取值的长度
- 语法:strlen key
127.0.0.1:6379> strlen addr1(integer) 7
(9) 不存在的时候才设置
语法:setnx key value
- 不存在,则创建
- 存在,则失败
127.0.0.1:6379> setnx address guangdong # address键 不存在,则创建(integer) 1
127.0.0.1:6379> get address
"guangdong"
127.0.0.1:6379> setnx address beijing # address键 存在,则失败
(integer) 0
127.0.0.1:6379> get address
"guangdong"
(10) 同时存储获取多个值
- 同时存储多个值:mset key1 value1 key2 value2 ...
- 同时获取多个值:mget key1 key2
同时存储多个值(保证不存在):msetnx key1 value1 key2 value2 ...
- 此操作为原子性操作,要失败全部失败
127.0.0.1:6379> mset addr1 beijing addr2 guangdong addr3 shanghai # 同时存储多个值OK
127.0.0.1:6379> keys *
1) "addr3"
2) "addr2"
3) "addr1"
127.0.0.1:6379> mget addr1 addr2 addr3 # 同时获取多个值
1) "beijing"
2) "guangdong"
3) "shanghai"
127.0.0.1:6379> msetnx age1 20 age2 25 age3 30 # 第一次同时存储多个值(保证不存在)
(integer) 1
127.0.0.1:6379> msetnx age4 35 age5 40 age1 45 # 第二次同时存储多个值(保证不存在),失败了
(integer) 0
127.0.0.1:6379>
(11) 设置对象
- 语法:key value (key 例如:user:1 ,value为一个json字符串)
127.0.0.1:6379> set user:1 {name:zhangsan,age:20} # 存一个对象OK
127.0.0.1:6379> keys *
1) "user:1"
127.0.0.1:6379> get user:1
"{name:zhangsan,age:20}"
- 以上这种 user:1 的设计在 Redis 中是允许的,例子如下
- 语法:对象名:{id}:{filed}
127.0.0.1:6379> mset user:1:name lisi user:1:age 25OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "lisi"
2) "25"
(12) 先 get 后 set
语法:getset
- 先取到原来的值,然后再把新值覆盖,如果原先没有值返回 nil
127.0.0.1:6379> getset addr beijing # 原先没有值,返回 nil(nil)
127.0.0.1:6379> get addr
"beijing"
127.0.0.1:6379> getset addr guangdong # 原先有值,返回原先的值,然后覆盖新值
"beijing"
127.0.0.1:6379> get addr
"guangdong"
(二) 列表类型 - list
(1) 添加
A:从左或从右添加元素
- lpush key value:将元素添加到列表左边
- Rpush key value:将元素添加到列表右边
下面演示添加到左边的,右边的是一样的就不演示了
127.0.0.1:6379> lpush list1 A(integer) 1
127.0.0.1:6379> lpush list1 B
(integer) 2
127.0.0.1:6379> lpush list1 C
(integer) 3
127.0.0.1:6379> lrange list1 0 -1
1) "C"
2) "B"
3) "A"
B:插入新值到某个值前后
- 语法:linsert list before/after value newvalue
127.0.0.1:6379> lrange list1 0 -11) "A"
2) "B"
3) "C"
127.0.0.1:6379> linsert list1 before C XXX # 在 C 前插入 XXX
(integer) 4
127.0.0.1:6379> lrange list1 0 -1
1) "A"
2) "B"
3) "XXX"
4) "C"
(2) 获取:
A:根据区间获取值
- 语法:lrange key start end
127.0.0.1:6379> lrange list1 0 -1 # 获取所有值1) "C"
2) "B"
3) "A"
127.0.0.1:6379> lrange list1 0 1 # 获取指定区间的值
1) "C"
2) "B"
B:根据下标获取值
- 语法:lindex list 下标
127.0.0.1:6379> lrange list1 0 -11) "C"
2) "B
127.0.0.1:6379> lindex list1 0
"C"
127.0.0.1:6379> lindex list1 1
"B"
C:获取列表的长度
- 语法 llen list
127.0.0.1:6379> llen list1(integer) 1
(3) 删除
A:移除最左或最右的元素
- lpop key:删除列表最左边的元素,且返回元素
- rpop key:删除列表最右边的元素,且返回元素
127.0.0.1:6379> lrange list1 0 -11) "D"
2) "C"
3) "B"
4) "A"
127.0.0.1:6379> lpop list1 # 删除列表最左边的元素,且返回元素
"D"
127.0.0.1:6379> rpop list1 # 删除列表最右边的元素,且返回元素
"A"
127.0.0.1:6379> lrange list1 0 -1
1) "C"
2) "B"
B:移除指定的值
- 语法:lrem list num value
127.0.0.1:6379> lrange list1 0 -11) "C"
2) "C"
3) "B"
4) "A"
127.0.0.1:6379> lrem list1 1 A # 删除1个A
(integer) 1
127.0.0.1:6379> lrange list1 0 -1
1) "C"
2) "C"
3) "B"
127.0.0.1:6379> lrem list1 2 C # 删除2个C
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "B"
127.0.0.1:6379>
C:移除最后一个元素且添加到另一个list
- rpoplpush list1 list2
127.0.0.1:6379> lrange list1 0 -11) "A"
2) "B"
3) "C"
127.0.0.1:6379> rpoplpush list1 list2 # 移除 list1 中最后一个元素,且添加到list2 中去
"C"
127.0.0.1:6379> lrange list1 0 -1
1) "A"
2) "B"
127.0.0.1:6379> lrange list2 0 -1
1) "C"
(4) 根据下标范围截取 list
- 语法:ltrim list start end
127.0.0.1:6379> rpush list1 A(integer) 1
127.0.0.1:6379> rpush list1 B
(integer) 2
127.0.0.1:6379> rpush list1 C
(integer) 3
127.0.0.1:6379> rpush list1 D
(integer) 4
127.0.0.1:6379> ltrim list1 1 2 # 截取下标为1到2的值
OK
127.0.0.1:6379> lrange list1 0 -1
1) "B"
2) "C"
(5) 替换指定下标的值
语法:lset list 下标 value
127.0.0.1:6379> exists list1 # 判断是否存在此list(integer) 0
127.0.0.1:6379> lset list1 0 beijing # 不存在,替换报错
(error) ERR no such key
127.0.0.1:6379> lpush list1 guangdong # 创建一个list
(integer) 1
127.0.0.1:6379> lindex list1 0
"guangdong"
127.0.0.1:6379> lset list1 0 beijing # 存在,替换成功
OK
127.0.0.1:6379> lindex list1 0
"beijing"
(三) 集合类型 - set
set:一种无序(不保证有序)集合,且元素不能重复
(1) 添加
- 语法:sadd key value
127.0.0.1:6379> sadd set1 A(integer) 1
127.0.0.1:6379> sadd set1 B
(integer) 1
127.0.0.1:6379> sadd set1 C
(integer) 1
127.0.0.1:6379> sadd set1 C # set的值不能重复
(integer) 0
127.0.0.1:6379> smembers set1 # 查询指定set的所有值,乱序
1) "B"
2) "A"
3) "C"
(2) 获取
A:获取set集合中的所有元素
- 语法:smembers key
127.0.0.1:6379> smesmbers set1 # 查询指定set的所有值,乱序1) "B"
2) "A"
3) "C"
B:获取元素的个数
- 语法:scard set
127.0.0.1:6379> scard set1(integer) 3
C:随机获取元素
语法:sembers set [num]
- 默认获取一个随机元素,后跟数字,代表随机获取几个元素
127.0.0.1:6379> smembers set11) "D"
2) "B"
3) "A"
4) "C"
127.0.0.1:6379> srandmember set1 # 获取一个随机元素
"D"
127.0.0.1:6379> srandmember set1 # 获取一个随机元素
"B"
127.0.0.1:6379> srandmember set1 2 # 获取两个随机元素
1) "A"
2) "D"
(3) 删除
A:删除set集合中某元素
- 语法:srem key value
127.0.0.1:6379> srem set1 C # 删除 C 这个元素(integer) 1
127.0.0.1:6379> smembers set1
1) "B"
2) "A"
B:随机删除一个元素
- 语法:spop set
127.0.0.1:6379> smembers set11) "D"
2) "B"
3) "A"
4) "C"
127.0.0.1:6379> spop set1 # 随机删除一个元素
"A"
127.0.0.1:6379> spop set1 # 随机删除一个元素
"B"
127.0.0.1:6379> smembers set1
1) "D"
2) "C"
(4) 移动指定值到另一个set
- 语法:smove set1 set2 value
127.0.0.1:6379> smembers set11) "D"
2) "C"
127.0.0.1:6379> smove set1 set2 D # 从 set1 移动 D 到 set2
(integer) 1
127.0.0.1:6379> smembers set1
1) "C"
127.0.0.1:6379> smembers set2
1) "D"
(5) 交集 并集 差集
- sinter set1 set2:交集
- sunion set1 set2:并集
- sdiff set1 set2:差集
127.0.0.1:6379> sadd set1 A(integer) 1
127.0.0.1:6379> sadd set1 B
(integer) 1
127.0.0.1:6379> sadd set1 C
(integer) 1
127.0.0.1:6379> sadd set2 B
(integer) 1
127.0.0.1:6379> sadd set2 C
(integer) 1
127.0.0.1:6379> sadd set2 D
(integer) 1
127.0.0.1:6379> sadd set2 E
(integer) 1
127.0.0.1:6379> sinter set1 set2 # 交集
1) "B"
2) "C"
127.0.0.1:6379> sunion set1 set2 # 并集
1) "D"
2) "E"
3) "C"
4) "B"
5) "A"
127.0.0.1:6379> sdiff set1 set2 # 差集
1) "A"
(四) 有序集合类型 - sortedset/zset
此类型和 set 一样也是 string 类型元素的集合,且不允许重复的元素
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序
有序集合的成员是唯一,但分数(score)却可以重复
(1) 添加
- 语法:zadd key score value [score value ... ...]
127.0.0.1:6379> zadd sortedset1 20 zhangsan # 添加一个(integer) 1
127.0.0.1:6379> zadd sortedset1 10 lisi 60 wangwu # 添加多个
(integer) 2
(2) 获取
A:获取所有值(默认排序)
语法:zrange sortedset start end [withscores]
- 根据那个值的大小进行了排序,例如上面的 10 20 60
127.0.0.1:6379> zrange sortedset1 0 -11) "lisi"
2) "zhangsan"
3) "wangwu"
B:获取所有值(从小到大和从大到小)
- zrangebyscore sortedset -inf +inf:从小到大
- zrevrange sortedset 0 -1:从大到小
127.0.0.1:6379> zrangebyscore sortedset1 -inf +inf # 从小到大1) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrevrange sortedset1 0 -1 # 从大到小
1) "wangwu"
2) "zhangsan"
3) "lisi"
C:获取值且附带数值
- zrangebyscore sortedset -inf +inf withscores:从小到大且附带值
127.0.0.1:6379> zrangebyscore sortedset1 -inf +inf withscores # 显示从小到大且附带值1) "lisi"
2) "10"
3) "zhangsan"
4) "20"
5) "wangwu"
6) "60"
127.0.0.1:6379> zrangebyscore sortedset1 -inf 20 withscores # 显示从小到大,且数值小于20的
1) "lisi"
2) "10"
3) "zhangsan"
4) "20"
127.0.0.1:6379>
D:获取有序集合中的个数
- 语法:zcard sortedset
127.0.0.1:6379> zcard sortedset1(integer) 2
E:获取指定区间成员数量
- 语法:zcount sortedset start end (strat 和 end是指那个数值,而不是什么下标)
127.0.0.1:6379> zcount sortedset1 10 60(integer) 3
(2) 删除
- zrem key value
127.0.0.1:6379> zrange sortedset1 0 -11) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrem sortedset1 wangwu # 删除 wangwu 这个元素
(integer) 1
127.0.0.1:6379> zrange sortedset1 0 -1
1) "lisi"
2) "zhangsan"
(五) 哈希类型 - hash
(1) 添加
A:普通添加
- 语法:hset hash field value
127.0.0.1:6379> hset hash1 username admin(integer) 1
127.0.0.1:6379> hset hash1 password admin
(integer) 1
B:不存在才可以添加
- 语法:hsetnx hash filed value
127.0.0.1:6379> hsetnx hash1 username admin888 # 已存在,失败(integer) 0
127.0.0.1:6379> hsetnx hash1 code 666 # 不存在,成功
(integer) 1
(2) 获取
A:获取指定的field对应的值
- 语法:hget hash field [ key field ... ...]
127.0.0.1:6379> hget hash1 password"admin"
B:获取所有的field和value
- 语法:hgetall hash
127.0.0.1:6379> hgetall hash11) "username"
2) "admin"
3) "password"
4) "admin"
C:获取 hash 的字段数量
- 语法:hlen hash
127.0.0.1:6379> hlen hash1(integer) 2
D:只获取所有 field 或 value
- hkeys hash:获取所有 field 字段
- hvals hash:获取所有 value 值
127.0.0.1:6379> hkeys hash1 # 获取所有 field 字段1) "username"
2) "password"
127.0.0.1:6379> hvals hash1 # 获取所有 value 值
1) "admin"
2) "admin"
(3) 删除
- 语法:hdel hash field
127.0.0.1:6379> hdel hash1 username(integer) 1
(4) 自增自减
- hincrby hash field 增量
127.0.0.1:6379> hsetnx hash1 code 666(integer) 1
127.0.0.1:6379> hincrby hash1 code 2
(integer) 668
127.0.0.1:6379> hincrby hash1 code -68
(integer) 600
五 三种特殊数据类型
(一) Geospatial(地理位置)
使用经纬度,作为地理坐标,然后存储到一个有序集合 zset/sortedset 中去保存,所以 zset 中的命令也是可以使用的
- 特别是需要删除一个位置时,没有GEODEL命令,是因为你可以用ZREM来删除一个元素(其结构就是一个有序结构)
- Geospatial 这个类型可以用来实现存储城市坐标,一般都不是自己录入,因为城市数据都是固定的,所以都是通过 Java 直接导入的,下面都是一些例子而已
- Geospatial 还可以用来实现附近的人这种概念,每一个位置就是人当前的经纬度,还有一些能够测量距离等等的方法,后面都会提到
命令列表:
(1) 存储经纬度
语法:geoadd key longitud latitude member [..]
- longitud——经度、 latitude——纬度
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
127.0.0.1:6379> geoadd china:city 116.413384 39.910925 beijing(integer) 1
127.0.0.1:6379> geoadd china:city 113.271431 23.135336 guangzhou
(integer) 1
127.0.0.1:6379> geoadd china:city 113.582555 22.276565 zhuhai
(integer) 1
127.0.0.1:6379> geoadd china:city 112.556391 37.876989 taiyuan
(integer) 1
(2) 获取集合中一个或者多个成员的坐标
- 语法:geopos key member [member..]
127.0.0.1:6379> geopos china:city beijing zhuhai1) 1) "116.41338318586349487"
2) "39.9109247398676743"
2) 1) "116.41338318586349487"
2) "39.9109247398676743"
(3) 返回两个给定位置之间的距离
语法:geodist key member1 member2 [unit]
- 单位默认为米,可以修改,跟在 member 后即可,例如 km
指定单位的参数 unit 必须是以下单位的其中一个:
m 表示单位为米
km 表示单位为千米
mi 表示单位为英里
ft 表示单位为英尺
127.0.0.1:6379> geodist china:city guangzhou taiyuan"1641074.3783"
127.0.0.1:6379> geodist china:city guangzhou taiyuan km
"1641.0744"
(4) 查找附近的元素(给定经纬度和长度)
- 含义:以给定的经纬度为中心, 返回集合包含的位置元素当中
语法:georadius key longitude latitude radius m|km|mi|ft WITHCOORD [WITHHASH] [COUNT count]
- 与中心的距离不超过给定最大距离的所有位置元素
通过
georadius就可以完成 附近的人功能(例如这个位置我们输入的是人当前的位置)- withcoord:带上坐标
- withdist:带上距离,单位与半径单位相同
- count :只显示前n个(按距离递增排序)
127.0.0.1:6379> georadius china:city 113.582555 22.276565 500 km1) "zhuhai"
2) "guangzhou"
127.0.0.1:6379> georadius china:city 113.582555 22.276565 500 km withdist withcoord count 1
1) 1) "zhuhai"
2) "0.0002"
3) 1) "113.58255296945571899"
2) "22.27656546780746538"
127.0.0.1:6379> georadius china:city 113.582555 22.276565 500 km withdist withcoord count 2
1) 1) "zhuhai"
2) "0.0002"
3) 1) "113.58255296945571899"
2) "22.27656546780746538"
2) 1) "guangzhou"
2) "100.7111"
3) 1) "113.27143281698226929"
2) "23.13533660075498233"
(5) 查找附近的元素(指定已有成员和长度)
- 含义:5 与 4 相同,给定的不是经纬度而是集合中的已有成员
- 语法:GEORADIUSBYMEMBER key member radius...
127.0.0.1:6379> georadiusbymember china:city zhuhai 500 km1) "zhuhai"
2) "guangzhou"
(6) 返回一个或多个位置元素的Geohash表示
- 语法:geohash key member1 [member2..]
127.0.0.1:6379> geohash china:city zhuhai1) "weby8xk63k0"
(二) Hyperloglog(基数统计)
HyperLogLog 是用来做基数(数据集中不重复的元素的个数)统计的算法,其底层使用string数据类型
HyperLogLog 的优点是:
在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的
- 花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
一个常见的例子:
- 传统实现,存储用户的id,然后每次进行比较。当用户变多之后这种方式及其浪费空间,而我们的目的只是计数,Hyperloglog就能帮助我们利用最小的空间完成。
(1) 添加
含义:添加指定元素到 HyperLogLog 中
语法:PFADD key element1 [elememt2..]
127.0.0.1:6379> pfadd test1 A B C D E F G(integer) 1
127.0.0.1:6379> pfadd test2 C C C D E F G
(integer) 1
(2) 估算myelx的基数
含义:返回给定 HyperLogLog 的基数估算值
语法:PFCOUNT key [key]
127.0.0.1:6379> pfcount test1(integer) 7
127.0.0.1:6379> pfcount test2
(integer) 5
(3) 合并
含义:将多个 HyperLogLog 合并为一个 HyperLogLog
语法:PFMERGE destkey sourcekey [sourcekey..]
127.0.0.1:6379> pfmerge test test1 test2OK
127.0.0.1:6379> pfcount test
(integer) 9
(三) BitMaps(位图)
BitMaps 使用位存储,信息状态只有 0 和 1
- Bitma p是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR,NOT以及其它位操作
- 这种类型的应用场景很多,例如统计员工是否打卡,或者登陆未登录,活跃不活跃,都可以考虑使用此类型
(1) 设置值
- 含义:为指定key的offset位设置值
- 语法:setbit key offset value
127.0.0.1:6379> setbit sign 0 1(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 0
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
(2) 获取
- 含义:获取offset位的值
- 语法:getbit key offset
127.0.0.1:6379> getbit sign 4(integer) 1
127.0.0.1:6379> getbit sign 2
(integer) 0
(3) 统计
- 含义:统计字符串被设置为1的bit数,也可以指定统计范围按字节
- 语法:bitcount key [start end]
127.0.0.1:6379> bitcount sign(integer) 4
六 事务
(一) 定义
定义:Redis 事务的本质是一组命令的集合
- 事务支持一次执行多个命令,一个事务中所有命令都会被序列化
- 在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中
即:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令
首先
(二) 特点
(1)不保证原子性
可能受到关系型数据库的影响,大家会将事务一概而论的认为数据库中的事务都是原子性的,但其实,Redis 中的事务是非原子性的。
原子性:所有的操作要么全做完,要么就全不做,事务必须是一个最小的整体,即像化学组中的原子,是构成物质的最小单位。
- 数据库中的某个事务中要更新 t1表、t2表的某条记录,当事务提交,t1、t2两个表都被更新,只要其中一个表操作失败,事务就会回滚
非原子性:与原子性反之
- 数据库中的某个事务中要更新 t1表、t2表的某条记录,当事务提交,t1、t2两个表都被更新,若其中一个表操作失败,另一个表操作继续,事务不会回滚
(2) 不支持事务回滚
多数事务失败是由语法错误或者数据结构类型错误导致的,而语法的错误是在命令入队前就进行检测,而类型错误是在执行时检测的,Redis为提升性能而采用这种简单的事务
(3) 事务没有隔离级别的概念
批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到
(三) 相关命令
(1) 开启事务
含义:开启事务,下一步就会将内容逐个放入队列中去,然后通过 exec 命令,原子化的执行
命令:multi
由于 multi 和 exec 需要搭配使用,所以在第二点一起演示示例
(2) 执行事务
含义:执行事务中的所有操作
命令:exec
A:正常开启且执行一个事务
首先先存一个 k1 和 k2,开启事务后,对这两个值进行修改,然后将这个事务执行,最后发现两个 OK ,然后用 get 查看一下值的变化
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11 # 修改 k1
QUEUED
127.0.0.1:6379> set k2 v22 # 修改 k2
QUEUED
127.0.0.1:6379> exec # 执行事务
1) OK
2) OK
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> get k2
"v22"
B:语法错误导致的事务失败
语法错误(编译器错误)导致的事务失败,会使得保持原值,例如下文事务中,修改 k1 没问题,但是修改 k2 的时候出现了语法错误,set 写成了 sett ,执行 exec 也会出错,最后发现 k1 和 k2 的值都没有变
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11 # 修改正常
QUEUED
127.0.0.1:6379> sett k2 v22 # 修改有语法错误
(error) ERR unknown command `sett`, with args beginning with: `k2`, `v22`,
127.0.0.1:6379> exec # 执行事务
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k2
"v2"
C:类型错误导致的事务失败
类型错误(运行时错误)导致的事务异常,例如下面 k2 被当做了一个 list 处理,这样在运行时就会报错,最后事务提交失败,但是并不会回滚,结果就是 k1 修改成功,而 k2 失败
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11
QUEUED
127.0.0.1:6379> lpush k2 v22 # 类型错误
QUEUED
127.0.0.1:6379> exec # 执行事务
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> get k2
"v2"
(3) 取消事务
这个没什么好说的,就是取消执行
127.0.0.1:6379> multiOK
127.0.0.1:6379> set k1 k11
QUEUED
127.0.0.1:6379> set k2 k22
QUEUED
127.0.0.1:6379> discard
OK
(4) watch 监控
Redis的命令是原子性的,而事务是非原子性的,通过 watch 这个命令可以实现 Redis 具有回滚的一个效果
做法就是,在 multi 之前先用 watch 监控某些键值对,然后继续开启以及执行事务
- 如果 exec 执行事务时,这些被监控的键值对没发生改变,它会执行事务队列中的命令
- 如果 exec 执行事务时,被监控的键值对发生了变化,则将不会执行事务中的任何命令,然后取消事务中的操作
我们监控 k1,然后再事务开启之前修改了 k1,又想在事务中修改 k1 ,可以看到最后结果中,事务中的操作就都没有执行了
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> watch k1 # 监控 k1
OK
127.0.0.1:6379> set k1 v111111 # k1 被修改了
OK
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v11
QUEUED
127.0.0.1:6379> set k2 v22
QUEUED
127.0.0.1:6379> exec # 执行事务
(nil)
127.0.0.1:6379> get k1
"v111111"
127.0.0.1:6379> get k2
"v2"
(5) unwatch 取消监控
取消后,就可以正常执行了
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> watch k1 # 监控
OK
127.0.0.1:6379> set k1 v111111
OK
127.0.0.1:6379> unwatch # 取消监控
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v11
QUEUED
127.0.0.1:6379> set k2 v22
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> get k2
"v22"
七 IDEA 中使用 Jedis 操作 Redis
Jedis 是一款可以让我们在java中操作redis数据库的工具,下载其jar包,或者引入到 maven 中即可,使用还是非常简单的
(一) 引入依赖和编码
我这里创建了一个空项目,然后创建一个普通的 maven 模块用来演示 jedis
首先引入 jedis 依赖,后面需要所以还引入了fastjson
版本自己去 maven 中去查就可以了,因为我们 linux 中安装的 redis 是一个新的版本,所以我们依赖也用了最新的
<dependencies><dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
创建测试类
- 如果是本机,例如 windows 下,启动 win 下的 redis 服务,然后用 127.0.0.1 访问
- 如果是远程机器,虚拟机或者云服务器,使用对应 ip 访问
- new Jedis 时空构造代表默认值 "localhost", 6379端口
public class Demo01 {public static void main(String[] args) {
// 远程 linux(虚拟机)
Jedis jedis = new Jedis("192.168.122.1", 6379);
// 测一下是否连通
System.out.println(jedis.ping());
}
}
(二) 连接 linux 的操作步骤
如果直接输入ip和端口,会连接不上,所以需要先做以下操作
① 保证 6379 端口开放
以 centos 7.9 为例,其他版本例如 6.x 可以查一下具体命令,以及防火墙是不是给拦截了,只要保证端口能访问到就可以了
- 开启6379端口
firewall-cmd --zone=public --add-port=6379/tcp --permanent# 显示
succss
- 重启防火墙
firewall-cmd --reload# 显示
success
- 检查端口是否开启
firewall-cmd --query-port=6379/tcp# 显示
yes
- 重启 redis 服务
[[email protected] bin]# redis-cli shutdown[[email protected] bin]# redis-server myconfig/redis.conf
你还可以在 window 的机器上,使用 telnet 192.168.122.1 6379 的方式测试一下是否能访问到,如果出现错误,请检查端口和防火墙的问题
② 修改 redis 配置文件
- 注释绑定的ip地址(注释掉 bind 127.0.0.1 这一句)
设置保护模式为 no(protected-mode 把 yes 改为 no)
- Linux上的 redis 处于安全保护模式,这就让你无法从虚拟机外部去轻松建立连接,所以在 redis.conf 中设置保护模式(protected-mode)为 no
再次在 IDEA 中访问,就可以访问到了
(三) 常见 API
(1) 字符串类型 - String
// 存储jedis.set("address","beijing");
// 获取
String address = jedis.get("address");
// 关闭连接
jedis.close();
补充:setex() 方法可以存储数据,并且指定过期时间
// 将aaa-bbb存入,且10秒后过期jedis.setex("aaa",10,"bbb")
(2) 列表类型 - list
// 存储jedis.lpush("listDemo","zhangsan","lisi","wangwu");//从左
jedis.rpush("listDemo","zhangsan","lisi","wangwu");//从右
// 获取
List<String> mylist = jedis.lrange("listDemo", 0, -1);
// 删除,并且返回元素
String e1 = jedis.lpop("listDemo");//从左
String e2 = jedis.rpop("listDemo");//从右
// 关闭连接
jedis.close();
(3) 集合类型 - set
// 存储jedis.sadd("setDemo","zhangsan","lisi","wangwu");
// 获取
Set<String> setDemo = jedis.smembers("setDemo");
// 关闭连接
jedis.close();
(4) 有序集合类型 - sortedset/zset
// 存储jedis.zadd("sortedsetDemo",20,"zhangsan");
jedis.zadd("sortedsetDemo",10,"lisi");
jedis.zadd("sortedsetDemo",60,"wangwu");
// 获取
Set<String> sortedsetDemo = jedis.zrange("sortedsetDemo", 0, -1);
// 关闭连接
jedis.close();
(5) 哈希类型 - hash
// 存储jedis.hset("hashDemo","name","lisi");
jedis.hset("hashDemo","age","20");
// 获取
String name = jedis.hget("hashDemo", "name");
// 获取所有数据
Map<String, String> user = jedis.hgetAll("hashDemo");
Set<String> keySet = user.keySet();
for (String key : keySet) {
//获取value
String value = user.get(key);
System.out.println(key + ":" + value);
}
// 关闭连接
jedis.close();
(四) Jedis 执行事务
public class Demo01 {public static void main(String[] args) {
// 远程 linux(虚拟机)
Jedis jedis = new Jedis("192.168.122.1", 6379);
JSONObject jsonObject = new JSONObject();
jsonObject.put("name", "zhangsan");
jsonObject.put("age", "21");
// 开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
try {
multi.set("userA", result);
multi.set("userB", result);
// 执行事务
multi.exec();
} catch (Exception e) {
// 放弃事务
multi.discard();
} finally {
System.out.println(jedis.get("userA"));
System.out.println(jedis.get("userB"));
// 关闭连接
jedis.close();
}
}
}
为了将结果显示出来,在关闭前添加两句输出语句
执行结果:
{"name":"zhangsan","age":"21"}
{"name":"zhangsan","age":"21"}
(五) Jedis 连接池
为什么我们要使用连接池呢?
我们要使用Jedis,必须建立连接,我们每一次进行数据交互的时候,都需要建立连接,Jedis虽然具有较高的性能,但建立连接却需要花费较多的时间,如果使用连接池则可以同时在客户端建立多个连接并且不释放,连接的时候只需要通过一定的方式获取已经建立的连接,用完则归还到连接池,这样时间就大大的节省了
下面就是我们直接创建了一个连接池,不过我们使用时一般都会封装一个工具类
@Testpublic void testJedisPool(){
// 0.创建一个配置对象
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(50);
config.setMaxIdle(10);
// 1.创建Jedis连接池对象
JedisPool jedisPool = new JedisPool(config,"192.168.122.1",6379);
// 2.获取连接
Jedis jedis = jedisPool.getResource();
// 3. 存储
jedis.set("name","zhangsan");
// 4. 输出结果
System.out.println(jedis.get("name"));
//5. 关闭 归还到连接池中
jedis.close();;
}
(一) 连接池工具类
直接使用工具类就可以了
import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
/**
* JedisPool工具类
* 加载配置文件,配置连接池的参数
* 提供获取连接的方法
*/
public class JedisPoolUtils {
private static JedisPool jedisPool;
static {
//读取配置文件
InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties");
//创建Properties对象
Properties pro = new Properties();
//关联文件
try {
pro.load(is);
} catch (IOException e) {
e.printStackTrace();
}
//获取数据,设置到JedisPoolConfig中
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal")));
config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle")));
//初始化JedisPool
jedisPool = new JedisPool(config, pro.getProperty("host"), Integer.parseInt(pro.getProperty("port")));
}
/**
* 获取连接方法
*/
public static Jedis getJedis() {
return jedisPool.getResource();
}
}
别忘了配置文件
host=192.168.122.1port=6379
maxTotal=50
maxIdle=100
调用代码
@Testpublic void testJedisPoolUtil(){
// 0. 通过连接池工具类获取
Jedis jedis = JedisPoolUtils.getJedis();
// 1. 使用
jedis.set("name","lisi");
System.out.println(jedis.get("name"));
// 2. 关闭 归还到连接池中
jedis.close();;
}
八 SpringBoot 整合 Redis
(一) 简单使用(存在序列化问题)
① 创建 Springboot项目或模块,引入依赖
<dependency><groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
可以看到,这个官方的 starter 引入了 Redis,但是并没有引入 Jedis,而是引入了 Lettuce
② 编写配置文件
# 配置redisspring.redis.host=192.168.122.1
spring.redis.port=6379
③ 测试代码
@SpringBootTestclass Redis02BootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","zhangsan");
System.out.println(redisTemplate.opsForValue().get("name"));
}
}
运行结果:
zhangsan
(二) 使用自定义 RedisTemplate 模板(推荐)
上述操作,在 IDEA 中的结果肯定是没问题的,但是我们去 Linux 中去看一下 Redis 的内容,却发现 key 都是乱码,例如存储的 name 却变成了如下内容
127.0.0.1:6379> keys *1) "\xac\xed\x00\x05t\x00\x04name"
这就是序列化的问题,下面我们会分析这个问题,这里先给出解决方案,即自定义 RedisTemplate 模板
① 自定义 RedisConfig 类
@Configurationpublic class RedisConfig {
/**
* 自定义 RedisTemplate 怒ban
*
* @param factory
* @return
*/
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 为开发方便,一般直接使用 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
② 调用
@SpringBootTestclass Redis02BootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("address","beijing");
System.out.println(redisTemplate.opsForValue().get("address"));
}
}
我们分别存储了 name2 和 address 这两个key,去终端中查看一下
127.0.0.1:6379> keys *1) "address"
2) "\xac\xed\x00\x05t\x00\x04name"
3) "name2"
可以看到,问题被解决了
(三) 封装一个工具类
我们操作追求的是便捷,而每次都是用一大堆 redisTemplate.opsForValue().xxxxx 很长的命令,所以封装一个工具类能更加事半功倍,具体工具类我就不在这里贴了,因为太长了,后面我会传到 github上去然后更新链接,当然了百度上其实一搜一大把
例如下面,我们使用工具类后就可以很简单的使用封装 redisTemplate 后的方法了
@Autowiredprivate RedisUtil redisUtil;
@Test
void contextLoads() {
redisUtil.set("address2", "zhuhai");
System.out.println(redisUtil.get("address2"));
}
(四) 简单分析原理
这一块的简单分析,主要想要弄清楚四个内容
- ① 是不是不再使用 Jedis 了,而是使用 Lettuce
- ② 查看配置文件的配置属性
- ③ 如何操作 Redis
- ④ 序列化问题(即存储乱码问题)
在以前 Springboot 的文章中,关于自动配置的原理中可知,整合一个内容的时候,都会有一个自动配置类,然后再 spring.factories 中能找到它的完全限定类名
进入 spring.factories,查找关于 redis 的自动装配类
进入 RedisAutoConfiguration 类后,在注解中就能看到 RedisProperties 类的存在,这很显然是关于配置文件的类
@Configuration(proxyBeanMethods = false)@ConditionalOnClass(RedisOperations.class)
// 这个注解!!!
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
// ...... 省略
}
进入 RedisProperties 类
alt + 7 可以在 IDEA 中查看到这个类中的属性方法等,这里查看一下其属性
例如地址端口,超时时间等等配置都清楚了,例如我们当时的配置文件是这样配的
# 配置redisspring.redis.host=192.168.122.1
spring.redis.port=6379
继续回到类,查看下面一个注解,发现有两个类
- LettuceConnectionConfiguration
- JedisConnectionConfiguration
@Configuration(proxyBeanMethods = false)@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
// 这个注解!!!
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
// ...... 省略
}
先来进入 Jedis 这个看看,GenericObjectPool 和 Jedis 这两个内容都是默认缺失的,所以是不会生效的
再来看看 LettuceConnectionConfiguration,是没有问题的,所以确实现在默认的实现都是使用 Lettuce 了
继续回到 RedisAutoConfiguration
其 Bean 只有两个
- RedisTemplate
- StringRedisTemplate
这种 XxxTemplate ,例如 JdbcTemplate、RestTemplate 等等都是通过 Template 来操作这些组件,所以这里的两个 Template 也是这也昂,分别用来操作 Redis 和 Redis 的 String 数据类型(因为 String 类型很常用)
// 注解略public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
特别注意这一个注解
@ConditionalOnMissingBean(name = "redisTemplate")它的意思就是说如果没有自定义,就默认使用这个,这也就是告诉我们,我们可以自己自定义Template,来覆盖掉默认的,前面的使用中我们知道,使用默认的 Template 会涉及到乱码,也就是序列化问题
因为在网络中传输的对象需要序列化,否则就是乱码
我们进入默认的 RedisTemplate 看看
首先看到的就是一些关于序列化的参数
往下看,可以看到默认的序列化方式使用的是 Jdk 序列化,而我们自定义中使用的是 Json 序列化
而默认的RedisTemplate中的所有序列化器都是使用这个序列化器
RedisSerializer 中为我们提供了多种序列化方式
所以后来我们就自定了 RedisTemplate 模板,重新定义了各种类型的序列化方式,这也是我们推荐的做法
以上是 【Java】【1w字+干货】第一篇,基础:让你的 Redis 不再只是安装吃灰到卸载(Linux环境) 的全部内容, 来源链接: utcz.com/a/107722.html
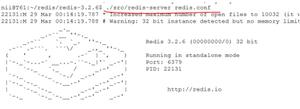



得票时间