
【JS】nodejs爬取简单网站小说生成txt
nodejs爬取简单网站小说生成txt
玛德致发布于 24 分钟前
找了一个没有反爬虫机制的普通网站,应该是ssr的,直接请求返回的html中就有全部的dom内容,没有异步请求,所以抓内容很容易。
一开始使用js脚本,发现请求跨域,所以改为node发送,步骤和代码很简单。
1.异步请求
使用了request-promise包+promise
2.处理内容
使用了cheerio,返回的内容直接是完整的html,cheerio可以把字符串的html转为dom结构,用法和jq差不多,很方便,而且我扒的网站页面结构也很简单,所有的小说文本都在id为content的div里
3.生成txt
直接fs写入文件即可
全部代码
var rp = require('request-promise');var cheerio = require('cheerio');
var fs = require('fs')
var start = 786776
var end = 786844
var arr = new Array(end-start+1).fill(null).map(function(item,index){
return rp('小说网址'+(start+index)+'.html')
})
Promise.all(arr).then(function(res,err){
if(err){
console.log('err')
}
var str=''
res.map(function(item,index){
var $ = cheerio.load(item.toString());
var table=$('body').find('#content').eq(0).text();
str+=table
})
fs.writeFile('恶徒.txt',str,'utf8',function(error){
if(error){
console.log(error);
return false;
}
console.log('写入成功');
})
})
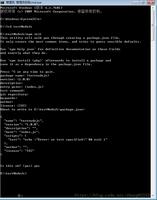
最终成果:
初次尝试,之后再试试爬异步请求的网站,如有问题请指出,感谢。
javascriptnode.js
阅读 21更新于 22 分钟前
本作品系原创,采用《署名-非商业性使用-禁止演绎 4.0 国际》许可协议
玛德致
272 声望
5 粉丝
玛德致
272 声望
5 粉丝
宣传栏
找了一个没有反爬虫机制的普通网站,应该是ssr的,直接请求返回的html中就有全部的dom内容,没有异步请求,所以抓内容很容易。
一开始使用js脚本,发现请求跨域,所以改为node发送,步骤和代码很简单。
1.异步请求
使用了request-promise包+promise
2.处理内容
使用了cheerio,返回的内容直接是完整的html,cheerio可以把字符串的html转为dom结构,用法和jq差不多,很方便,而且我扒的网站页面结构也很简单,所有的小说文本都在id为content的div里
3.生成txt
直接fs写入文件即可
全部代码
var rp = require('request-promise');var cheerio = require('cheerio');
var fs = require('fs')
var start = 786776
var end = 786844
var arr = new Array(end-start+1).fill(null).map(function(item,index){
return rp('小说网址'+(start+index)+'.html')
})
Promise.all(arr).then(function(res,err){
if(err){
console.log('err')
}
var str=''
res.map(function(item,index){
var $ = cheerio.load(item.toString());
var table=$('body').find('#content').eq(0).text();
str+=table
})
fs.writeFile('恶徒.txt',str,'utf8',function(error){
if(error){
console.log(error);
return false;
}
console.log('写入成功');
})
})
最终成果:
初次尝试,之后再试试爬异步请求的网站,如有问题请指出,感谢。
以上是 【JS】nodejs爬取简单网站小说生成txt 的全部内容, 来源链接: utcz.com/a/107435.html




得票时间