【Java】Java面试官告诉你JMM是什么和面什么
我去年以面试官的身份面了多个候选人,深知很多人其实并没有搞清楚Java的内存模型的概念和存在作用,当我在问谈谈Java的内存模型的时候,大多数人都回答了什么JVM的内存结构啊,也就是堆那些啊什么的,这些都是错的,那么实际上Java的内存模型实际上是什么呢?它的常问面试题又是什么呢?别急,我这边已经给你整理好了。
了解几个重要的概念。
CPU和缓存一致性
我们都知道,计算机在执行程序的时候,每条指令都是在 CPU 中执行的,而执行的时候,又免不了和数据打交道,而计算机上面的数据,是存放在计算机的物理内存上的。
当内存的读取速度和CPU的执行速度相比差别不大的时候,这样的机制是没有任何问题的,可是随着CPU的技术的发展,CPU的执行速度和内存的读取速度差距越来越大,导致CPU每次操作内存都要耗费很多等待时间。
为了解决这个问题,初代程序员大佬们想到了一个的办法,就是在CPU和物理内存上新增高速缓存,这样程序的执行过程也就发生了改变,变成了程序在运行过程中,会将运算所需要的数据从主内存复制一份到CPU的高速缓存中,当CPU进行计算时就可以直接从高速缓存中读数据和写数据了,当运算结束再将数据刷新到主内存就可以了。
随着时代的变迁,程序员的越发能干,CPU开始出现了多核的概念,每个核都有一套自己的缓存,并且随着计算机能力不断提升,还开始支持多线程,最终演变成,多个线程访问进程中的某个共享内存,且这多个线程分别在不同的核心上执行,则每个核心都会在各自的 Cache 中保留一份共享内存的缓冲,我们知道多核是可以并行的,这样就会出现多个线程同时写各自的缓存的情况,导致各自的 Cache 之间的数据可能不同。
总结下来就是:在多核 CPU 中,每个核的自己的缓存,关于同一个数据的缓存内容可能不一致。
处理器优化和指令重排
为了使处理器内部的运算单元能够被充分利用,处理器可能会对程序代码进行乱序执行处理,这就是处理器优化。
除了现在很多流行的处理器会对代码进行优化乱序处理,很多编程语言的编译器也会有类似的优化,比如 Java 虚拟机的即时编译器(JIT)也会做指令重排。
可想而知,如果任由处理器优化和编译器对指令重排的话,就可能导致各种各样的问题。
并发编程会带来什么问题
前面说的和硬件有关的概念关注我的可能听得都有点懵逼,应该大多数都是软件工程师吧,但是关于并发编程的问题我们应该是有所了解的,比如耳熟能详的原子性问题,可见性问题和有序性问题啊。
其实呢,原子性问题,可见性问题和有序性问题是后面初代程序大佬们抽象出来的概念,对应的便是前面提到的缓存一致性问题、处理器优化问题和指令重排问题等,不得不说,初代程序大佬们为了让我们这群软件工程师能够理解硬件的概念也是煞费苦心了。
并发编程为了保证数据的安全,必须满足以下三个特性:
- 原子性,指的是在一个操作中CPU 不可以在中途暂停然后再调度,要么不执行,要么就执行完成。
- 可见性,指的是多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改后的值。
- 有序性,指的是程序执行的顺序按照代码的先后顺序执行,而不能瞎几把重排,导致程序出现不一致的结果。
看完上面的三个特性的解释,我们也能知道,缓存一致性问题其实就是可见性问题,而处理器优化是可以导致原子性问题的,指令重排即会导致有序性问题。
总结下来就是:并发编程会带来原子性问题、可见性问题、有序性问题
什么是内存模型
上面说到了缓存一致性问题,其实是硬件的不断升级导致的,有些心大的朋友可能就会直接说了,废除处理器和处理器的优化技术、废除 CPU 缓存,让 CPU 直接和主存交互不就没问题了吗?
首先,想法是肯定的,可以解决,但是做法就有点过了,相当于为了避免有车祸发生,直接将汽车废弃掉一样。
Java为了保证并发编程中可以满足原子性、可见性及有序性,诞生出了一个重要的概念,那就是内存模型,内存模型定义了共享内存系统中多线程程序读写操作行为的规范。
通过这些规则来规范对内存的读写操作,从而保证指令执行的正确性,它解决了 CPU 多级缓存、处理器优化、指令重排等导致的内存访问问题,保证了并发场景下的一致性、原子性和有序性。
总结下来就是:Java内存模型定义了共享内存系统中多线程程序读写操作行为的规范,Java内存模型也就是为了解决这个并发编程问题而存在的。
内存模型怎么解决并发问题的?
内存模型解决并发问题主要采取两种方式,分别是限制处理器优化,另一种是使用了内存屏障。
而对于这两种方式,Java底层其实已经封装好了一些关键字,我们这边只需要用起来就可以了。
关于解决并发编程中的原子性问题,Java底层封装了Synchronized的方式,来保证方法和代码块内的操作都是原子性的;
而至于可见性问题,Java底层则封装了Volatile的方式,将被修饰的变量在修改后立即同步到主内存中。
至于有序性问题,其实也就是我们所说的重排序问题,Volatile关键字也会禁止指令的重排序,而Synchroinzed关键字由于保证了同一时刻只允许一条线程操作,自然也就保证了有序性。
总结一波:看到这里,基本上都应该了解JMM是什么以及用来干嘛的了吧,上面的解释应该是很清晰易懂的了,如果还看不懂就看两遍吧,理解JMM是什么对并发编程来说太重要了。
分享几个常考的面试题
线程之间的通信机制可以分为两种,分别是
- 共享内存
- 消息传递
目前Java的并发通信采用的是共享内存的方式。
这道题算是比较常见的理论题了,有一部分人对操作系统有点了解的知道线程之间的通信机制有两种,但是很少人知道Java的并发通信采用的是共享内存的方式。
内存模型是吗?请问下是JVM的内存模型呢?还是Java内存模型,也就是JMM呢?
这个问题比较容易让人混淆,大多数一听内存模型,都会率先想到JVM内存模型,也就是堆内存那些,所以如果遇见概念不清的问题,一定要大胆问,记得我刚毕业的时候第一次听见这种问题,就理解错以为是JVM内存模型导致丢分。
JMM其实并不像JVM内存模型一样是真实存在的,它只是一个抽象的规范。在不同的硬件或者操作系统下,对内存的访问逻辑都有一定的差异,而这种差异会导致同一套代码在不同操作系统或者硬件下,得到了不同的结果,而JMM的存在就是为了解决这个问题,通过JMM的规范,保证Java程序在各种平台下对内存的访问都能得到一致的效果。
JMM的概念其实比较容易忘记,所以我这边特地表明了它是为了解决上面问题而存在的,通过理解它是什么,用来做什么,比较容易产生深度记忆。
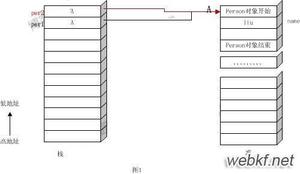
JMM规定了内存主要划分为主内存和工作内存两种,规定所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中用到的变量的主内存的副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。
不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。

为了清楚展示这个过程,我特地画了张图
此处的工作内存和主内存其实跟JVM内存的划分是在不同层次上进行的,是自己的一套抽象概念,大概可以理解为,主内存对应的是Java堆中的对象实例部分,而工作内存对应的则是栈中的部分区域,
JMM定义了8个操作来完成主内存和工作内存的交互操作,首先是从lock加锁开始,把主内存中的变量标志为一条线程独占的状态;read读取,将一个变量的值从主内存传输到工作内存中;load加载,把read得到的值加载到工作内存的变量副本中;use使用,把工作内存中变量的值传递给执行引擎;assign赋值,把从执行引擎接收到的值赋值给工作内存的变量;store存储,把工作内存中变量的值传送回主内存中;write写入,把store得到的值放入主内存的变量中;最后是unlock解锁,把主内存中处于锁定状态的变量释放出来,流程到这一步就结束了。

JMM基本可以说是围绕着在并发中如何处理这三个特性而建立起来的,也就是原子性、可见性、以及有序性。
所谓的原子性指的就是一个操作或者多个操作要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
拓展:我们都知道CPU有时间片的概念,会根据不同的调度算法进行线程调度,而当线程在执行一个读改写操作时,在执行完读改之后,时间片耗完,就会被要求放弃CPU,并等待重新调度。这种情况下,读改写就不是一个原子操作,即存在原子性问题。
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
拓展:多个线程访问进程中的某个共享内存时,这多个线程是分别在不同的CPU上执行的,则每个CPU都会在各自的cache中保留一份共享内存的缓冲,由于多核是可以并行的,可能会出现多个线程同时写各自的缓存的情况,而各自的cache之间的数据就有可能不同,这就存在了可见性问题。
有序性即程序执行的顺序按照代码的先后顺序执行。
拓展:由于处理器优化和指令重排以及CPU还可能对输入代码进行乱序执行,比如load->add->save 有可能被优化成load->save->add ,这就是有序性问题。
归根结底,就是为了实现多个线程的工作内存的数据一致性,让程序在多线程并发、指令重排序优化的环境中也能如预期中的一样执行。
大白话解释了一波原子性问题、可见性问题、有序性问题,同样先记住概念,再理解拓展,够了,没什么坑。概念那块是必答的,而拓展那块其实是加分项,我们面试官都喜欢候选人对答案有自己的见解,而不是一上来就是背各种答案,没有自己的见解只能算是平庸。
a = 20;
b = a;
除了第一个操作,其他都是非原子性操作。
这里可能很多人都不理解,为什么第二个操作是非原子性操作,实际上第二个操作包含了两部分,它先要去读取a的值,然后再讲a的值写入b中,虽然读取a的值以及将a的值写入工作内存都是两个原子性操作,但是合起来就不是原子性操作了。
JMM只保证了基本读取和赋值是原子性的操作,但是如果要实现更大范围操作的原子性,则可以通过synchroinzed和lock来实现,synchronized和lock能够保证任一时刻只有一个线程执行该代码块,从而保证了原子性。
对可见性来说,Java提供了volatile关键字来保证可见性,而synchronized和lock也能够保证可见性,synchronized和lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中,因此可以保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值被立即更新到主内存中,当有其他线程读取该值时,也不会直接读取工作内存中的值,而是直接去主内存中读取。
而普通的共享变量不能保证可见性的,因为普通共享变量被修改后,写写入了工作内存中,什么时候写入主内存其实是不可知的,当其他线程去读取是,此时无论是工作内存还是主内存,可能还是原来的值,因此无法保证可见性。
首先,Java里边可以通过synchronized和lock来保证有序性,synchronized和Lock可以保证每个时刻是有一个线程执行同步代码,相当于是让线程按照顺序的执行同步代码,自然也就保证了有序性。
另外Java内存模型也通过happens-before原则来保证有序性。
这个关比较复杂,也不好描述,为了向面试官清楚描述这个过程,我举了一个例子,加入现在程序中有两个操作,分别为A和B;

首先这两个操作可以在一个线程之内被执行,也可以在不同线程之间被执行;
而如果是单线程下的话,编译后的字节码天然就包括了happens-before关系,因为单线程内共享一份工作内存,不存在数据一致性的问题。 在程序控制流路径中靠前的字节码 happens-before 靠后的字节码,即靠前的字节码执行完之后操作结果对靠后的字节码是可见的。
当然了,这并不意味着前者一定在后者之前执行,实际上,如果后者不依赖前者的运行结果,那么它们可能会被重排序。
而如果是多线程下的话,由于每个线程都有一份共享变量的副本,如果没有对共享变量做同步的处理,线程1更新执行操作A共享变量的值之后,线程2开始执行操作B,此时操作A产生的结果对操作B不一定可见。
为了解决这个多线程开发的问题,方便程序开发,JMM通过happens-before关系向我们程序员提供跨线程的内存可见性保证,也就是说如果线程1的A操作与线程2的B操作之间存在happens-before关系,尽管A操作和B操作在不同的线程中执行,JMM依旧向我们程序员保证A操作对B操作是可见的。
不是的。JMM虽然定义了如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,但是这并不是以为这Java平台的具体实现必须按照happens-before关系指定的顺序执行,如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法,也就是说,JMM是允许这种重排序的。
扩展:我们要记住,JMM其实就是是在遵循一个基本原则,就是只要不改变程序的执行结果,不管是单线程,还是多线程,编译器和处理器怎么优化都行。其实JMM可以这么做的原因也很简单,毕竟我们开发中对于这两个操作是否真的被重排序并不关心,我们关心的是程序执行结果不能被改变,也就是只要别出bug就可以了,哭唧唧。
最后
目前好好面试系列已经汇总了以下面试题
- 隐藏在Java基础中的50个坑
- 全面了解JMM以及常考面试题
- ...
后续会继续推出JVM、集合、Spring系列,有兴趣的关注一波。
为了感谢最近大家的支持,我这边特地跳了一些Java相关的资源,很多专题,比如JAVA+TCP、Java反射机制、Java多线程专题等,都是针对性训练的利器,建议人手一份。

有兴趣的关注我一波,Java面试官带你们跨过一个个的面试坑,保证不亏。
公众号:饭谈编程
原文链接:https://mp.weixin.qq.com/s/_zmhLhEDgLggejUdF1c9gw
谢谢点赞支持👍👍👍!
以上是 【Java】Java面试官告诉你JMM是什么和面什么 的全部内容, 来源链接: utcz.com/a/101621.html